Spatial Features
Last updated: 2020-06-05
Checks: 7 0
Knit directory: STUtility_web_site/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20191031) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version f3c5cb4. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: analysis/.DS_Store
Ignored: analysis/manual_annotation.png
Ignored: analysis/visualization_3D.Rmd
Ignored: pre_data/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/spatial_features.Rmd) and HTML (docs/spatial_features.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | f3c5cb4 | Ludvig Larsson | 2020-06-05 | Build site. |
| html | f89df7e | Ludvig Larsson | 2020-06-05 | Build site. |
| html | 1e67a7c | Ludvig Larsson | 2020-06-04 | Build site. |
| html | f71b0c0 | Ludvig Larsson | 2020-06-04 | Build site. |
| html | 8a54a4d | Ludvig Larsson | 2020-06-04 | Build site. |
| html | 5e466eb | Ludvig Larsson | 2020-06-04 | Build site. |
| html | 377408d | Ludvig Larsson | 2020-06-04 | Build site. |
| html | ed54ffb | Ludvig Larsson | 2020-06-04 | Build site. |
| html | f14518c | Ludvig Larsson | 2020-06-04 | Build site. |
| html | efd885b | Ludvig Larsson | 2020-06-04 | Build site. |
| html | 4f42429 | Ludvig Larsson | 2020-06-04 | Build site. |
| Rmd | 3660612 | Ludvig Larsson | 2020-06-04 | update website |
| html | f677bf1 | jbergenstrahle | 2020-04-01 | Build site. |
| Rmd | d1999a1 | jbergenstrahle | 2020-04-01 | Refs added |
| html | a024bce | jbergenstrahle | 2020-01-12 | Build site. |
| Rmd | d936ce7 | jbergenstrahle | 2020-01-12 | changed to 10x public data |
| html | 0b6d8e8 | jbergenstrahle | 2020-01-11 | Build site. |
| Rmd | 859a8e7 | jbergenstrahle | 2020-01-11 | Fixed figure aspect ratios |
| html | fb06450 | jbergenstrahle | 2020-01-11 | Build site. |
| Rmd | 6444381 | jbergenstrahle | 2020-01-10 | Removed MultipleFeature.. |
| Rmd | 2890e65 | jbergenstrahle | 2020-01-08 | pre-pek |
| Rmd | efbbda3 | jbergenstrahle | 2020-01-01 | update pek |
| Rmd | 672191f | Ludvig Larsson | 2019-12-16 | Added 3D plotting to vignette |
| Rmd | baff98e | jbergenstrahle | 2019-12-16 | adding |
| Rmd | 5cb8ab1 | jbergenstrahle | 2019-12-02 | update2 |
| html | a3a1f1f | Ludvig Larsson | 2019-10-31 | Changed font |
| Rmd | 7cdf8e1 | Ludvig Larsson | 2019-10-31 | Changed font size |
| Rmd | 786357d | Ludvig Larsson | 2019-10-31 | Fixed warnings |
| html | 786357d | Ludvig Larsson | 2019-10-31 | Fixed warnings |
| Rmd | f10ef37 | Ludvig Larsson | 2019-10-31 | Added section noramlization and spatial faetures |
| html | f10ef37 | Ludvig Larsson | 2019-10-31 | Added section noramlization and spatial faetures |
Finding spatial expression patterns
The strength of untargeted whole transcriptome capture is the ability to perform unsupervised analysis and the ability to find spatial gene expression patterns. We’ve found good use of using non-negative matrix factorization (NNMF or NMF) to find underlying patterns of transcriptomic profiles. This factor analysis, along with various dimensionality reduction techniques, can all be ran via “RunXXX()”, where X = the method of choice, e.g.:
se <- RunNMF(se, nfactors = 40) #Specificy nfactors to choose the number of factors, default=20.
While RunNMF() is an STUtility add-on, others are supported via Seurat (RunPCA(), RunTSNE, RunICA(), runUMAP() ) and for all of them, the output are stored in the Seurat object.
We can then plot a variable number of dimensions across the samples using ST.DimPlot or as an overlay using DimOverlay. These two functions are similar to the ST.FeaturePlot and FeatureOverlay but have been adapted to specifically draw dimensionality reduction vectors instead of features.
NOTE: by default, the colorscale of dimensionality reduction vectors will be centered at 0. If we have a dimensionality reduction vector x this means that the range of colors will go from -max(abs(x)) to max(abs(x)). This behaviour is typically desired when plotting e.g. PCA vectors, but for NMF all values are strictly positive so you can disable this centering by setting center.zero = FALSE.
cscale <- c("darkblue", "cyan", "yellow", "red", "darkred")
ST.DimPlot(se,
dims = 1:10,
ncol = 2, # Sets the number of columns at dimensions level
grid.ncol = 2, # Sets the number of columns at sample level
reduction = "NMF",
dark.theme = T,
pt.size = 0.5,
center.zero = F,
cols = cscale)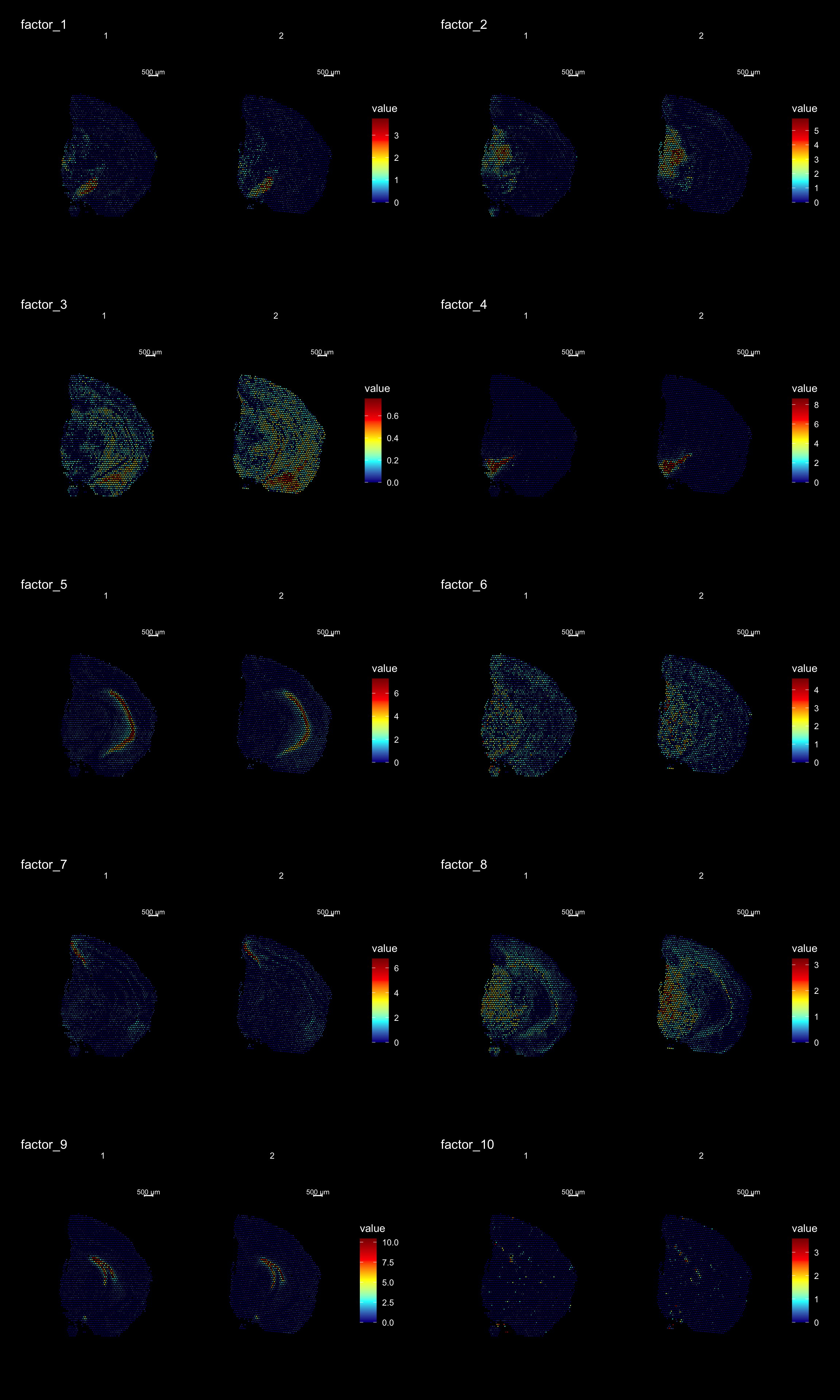
ST.DimPlot(se,
dims = 11:20,
ncol = 2,
grid.ncol = 2,
reduction = "NMF",
dark.theme = T,
pt.size = 0.5,
center.zero = F,
cols = cscale)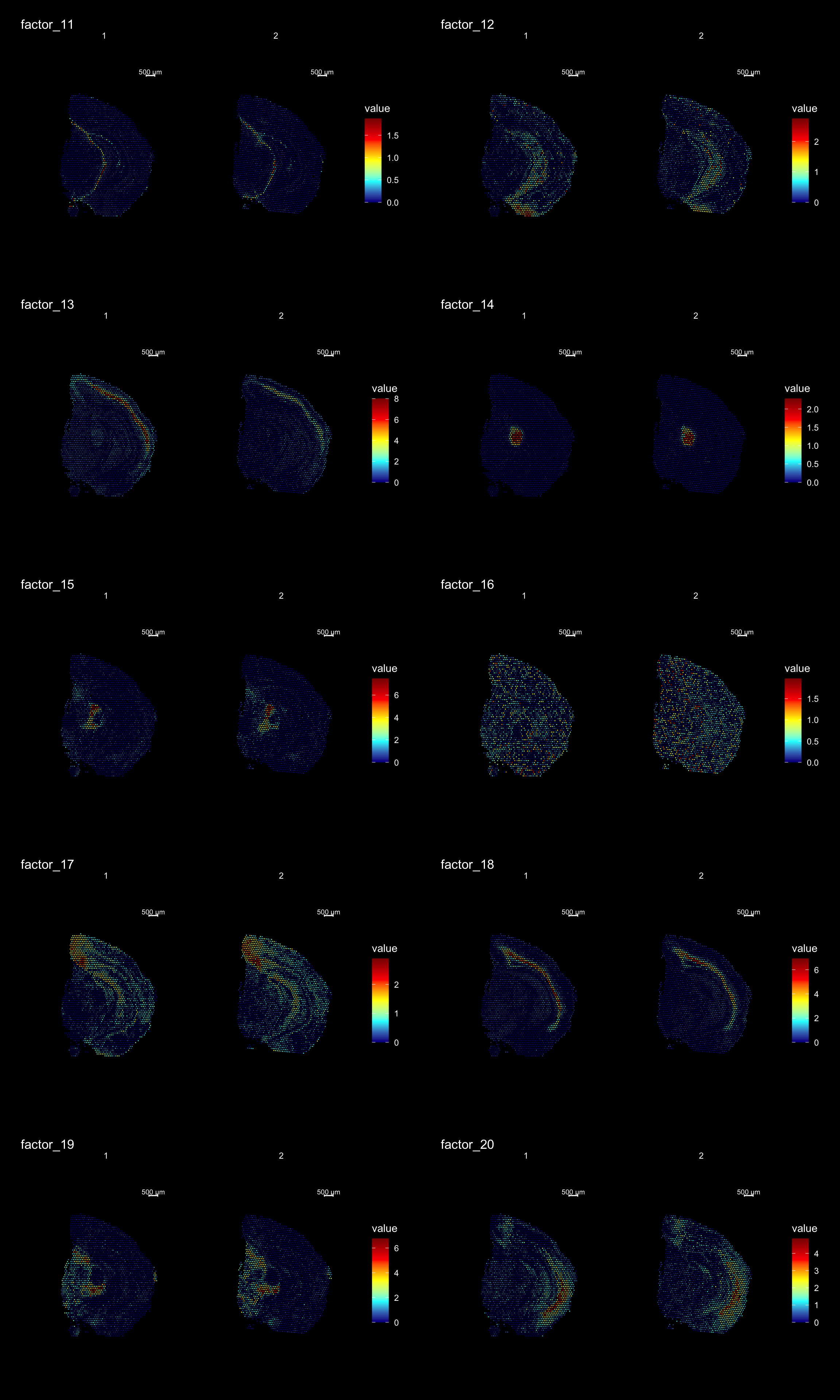
ST.DimPlot(se,
dims = 21:30,
ncol = 2,
grid.ncol = 2,
reduction = "NMF",
dark.theme = T,
pt.size = 0.5,
center.zero = F,
cols = cscale)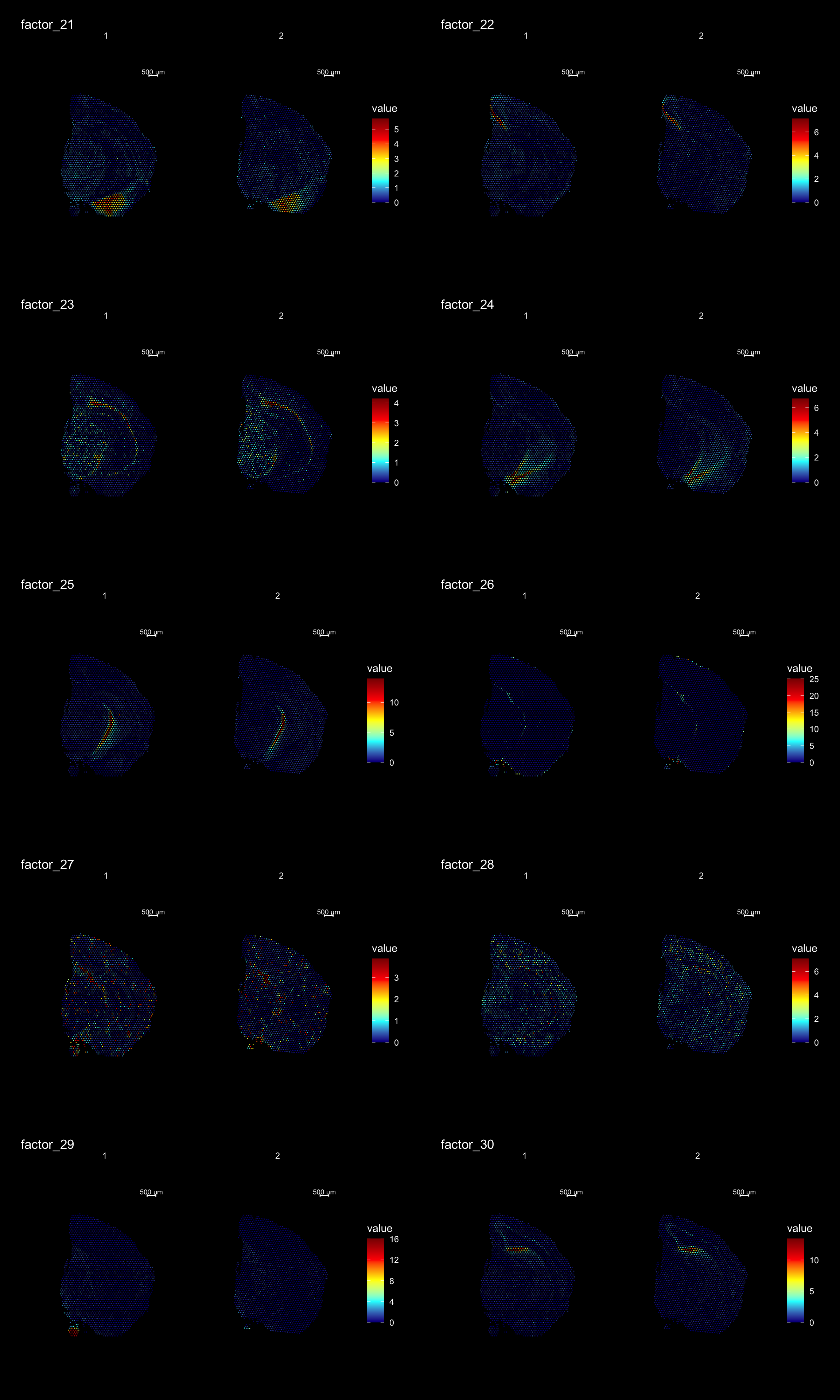
ST.DimPlot(se,
dims = 31:40,
ncol = 2,
grid.ncol = 2,
reduction = "NMF",
dark.theme = T,
pt.size = 0.5,
center.zero = F,
cols = cscale)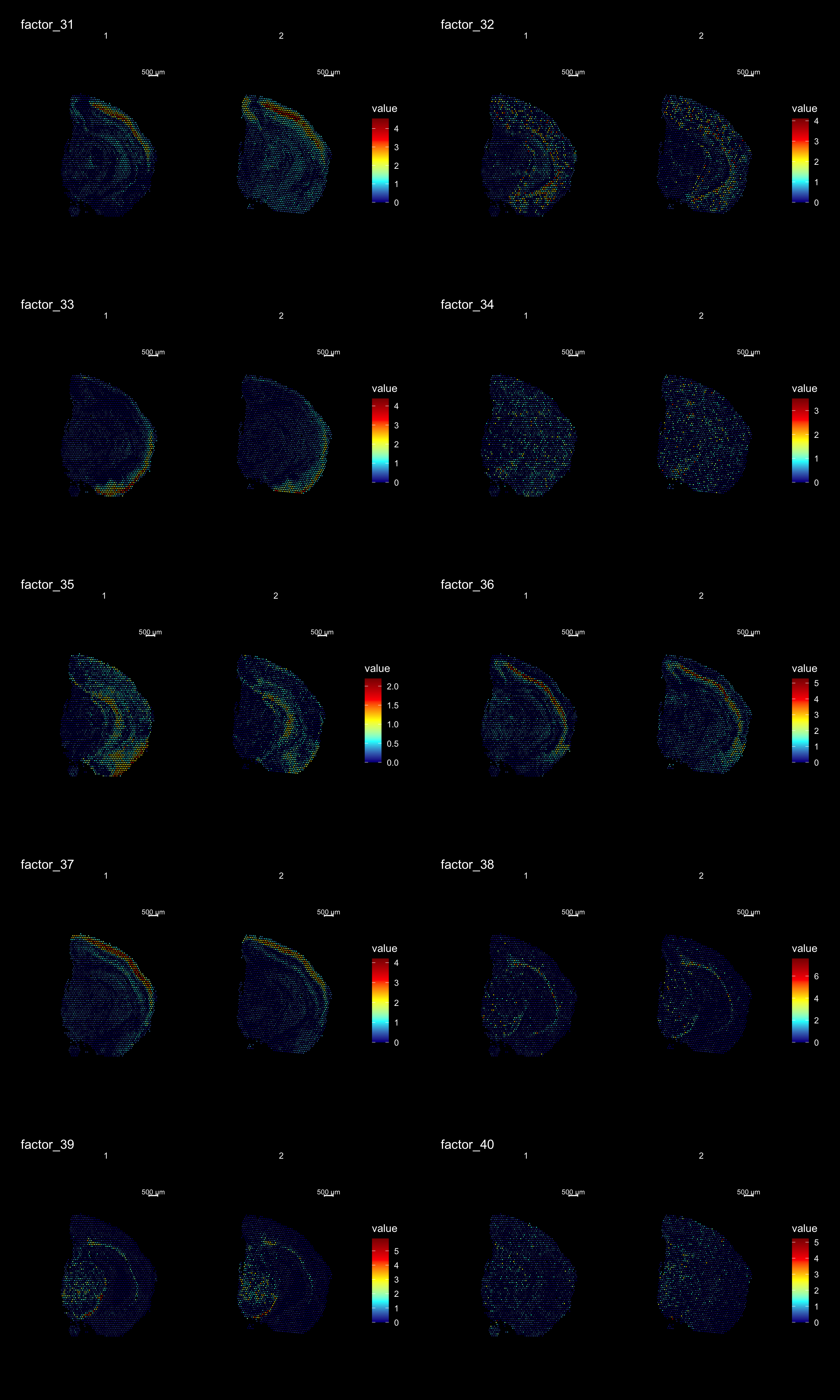
We can also print a summary of the genes that contribute most to the dimensionality reduction vectors.
For NMF output which is not centered at 0 looking at the “negative” side of the distribution doesn’t really add any valuable information, instead you can aget a barplot summarizing the top most contributing genes using FactorGeneLoadingPlot.
print(se[["NMF"]])factor_ 1
Positive: Pvalb, Gad1, Spp1, Slc32a1, Six3, Sparc, Lsm6, Ndufb8, Nsg1, Agt
Enho, Ldhb, Gabra1, Cst3, Cox6c, Ndrg2, Cox5a, Ckb, Lgi2, Nefh
Negative: Rgs20, C1qtnf2, Lyn, Nid2, St6galnac2, Rbm20, Pdzd2, Mndal, Emx2, Sp9
Gcnt2, Gm19410, Irak2, Tbx2, Gm11627, Nfatc1, Bambi, Sorcs1, Pam, Arhgap45
factor_ 2
Positive: Vamp1, Pvalb, Bend6, Nat8l, Cox5a, Pcp4l1, Stmn3, Nefm, Syt2, Snrpn
Pcsk1n, Ndufa4, Ctxn3, Slc17a6, Cend1, Kcnab3, Cox4i1, Mdh1, Scn1b, Camk2n2
Negative: Plxnc1, Cdhr1, C1qtnf2, Evc, Klf11, Nid2, Ly6g6f, Hist1h4h, Ppp1r18, St6galnac2
Fxyd2, Blnk, Fam89a, Dock8, Emx2, Cyp20a1, Sp9, Ginm1, Acacb, Gm10561
factor_ 3
Positive: mt-Nd3, Rps29, Rps21, Rpl39, Rplp1, mt-Co3, Cnot3, Rpl37, Rps19, Rps27
mt-Nd5, Rpl35a, Rps28, mt-Nd4l, Rpl37a, Tatdn1, Rpl26, Nnat, Uba52, mt-Co1
Negative: Otx1, Rgs20, Evc, Pkd2, Nid2, Ppp1r18, St6galnac2, Tnxb, Atf4, Rbm20
Slc25a45, Pdzd2, Mndal, Amt, Blnk, Agtrap, Grik1, Fam89a, Dock8, Pcdh18
factor_ 4
Positive: Th, Slc6a3, Slc18a2, Ddc, Sncg, Slc10a4, Ret, Dlk1, En1, Chrna6
Drd2, Cplx1, Sv2c, Aldh1a1, Gch1, Uchl1, Gap43, Chrnb3, Tagln3, Foxa1
Negative: Cdhr1, Evc, Nid2, St6galnac2, Slc25a45, Blnk, C530008M17Rik, Dock8, Emx2, Sp9
Bin2, Wnt5b, Nfatc1, Bambi, Sorcs1, Phactr4, Masp1, Rapgef3, Kdr, Epha8
factor_ 5
Positive: Spink8, Tmsb4x, Fibcd1, Hpca, Fkbp1a, Itpka, Cnih2, Calm2, Tspan13, Lefty1
Crym, Prnp, Dynll1, Rprml, Cpne6, Arpc5, Mpped1, Cpne7, Neurod6, Ociad2
Negative: Cdh9, Otx1, Spsb1, Cdhr1, Rgs20, Nid2, Ly6g6f, Ppp1r18, Rbm20, Slc25a45
Pdzd2, Mndal, Atp2a3, Grik1, Fam89a, Cux1, Tex9, Dock8, Msi1, Sp9 FactorGeneLoadingPlot(se, factor = 1, dark.theme = TRUE)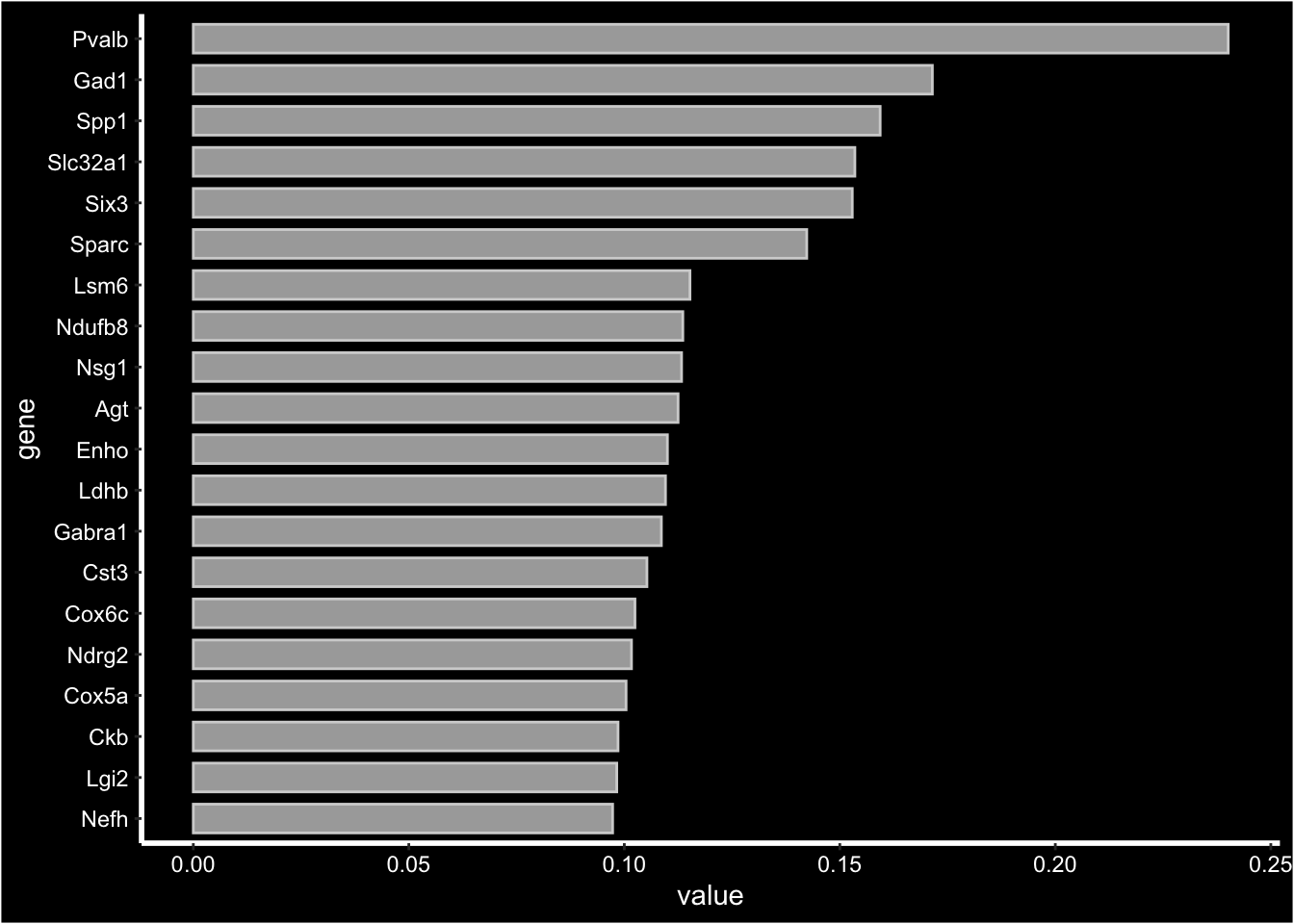
| Version | Author | Date |
|---|---|---|
| 4f42429 | Ludvig Larsson | 2020-06-04 |
Clustering
Clustering is a standard procedure in genomic analysis, and the methods for doing so are numerous. Here we demonstrate an example where we use the result of the factor analysis the previous section. Going through the list of factors (e.g. via ST:DimPlot(se, dims = [dims you want to look at])), we can notice dimensions that are “spatially active”, i.e. that seems to confer a spatial pattern along their axis. We can extract these dimensions and use as input to e.g. clustering functions. Here, we use all dimensions from the NMF and construct a Shared Nearest Neighbor (SSN) Graph.
se <- FindNeighbors(object = se, verbose = FALSE, reduction = "NMF", dims = 1:40)
Followed by clustering using a modularity optimizer
se <- FindClusters(object = se, verbose = FALSE)
And plotting of the clusters spatially
library(RColorBrewer)
n <- 19
qual_col_pals = brewer.pal.info[brewer.pal.info$category == 'qual',]
col_vector = unlist(mapply(brewer.pal, qual_col_pals$maxcolors, rownames(qual_col_pals)))
ST.FeaturePlot(object = se, features = "seurat_clusters", dark.theme = T, cols = col_vector, pt.size = 0.5)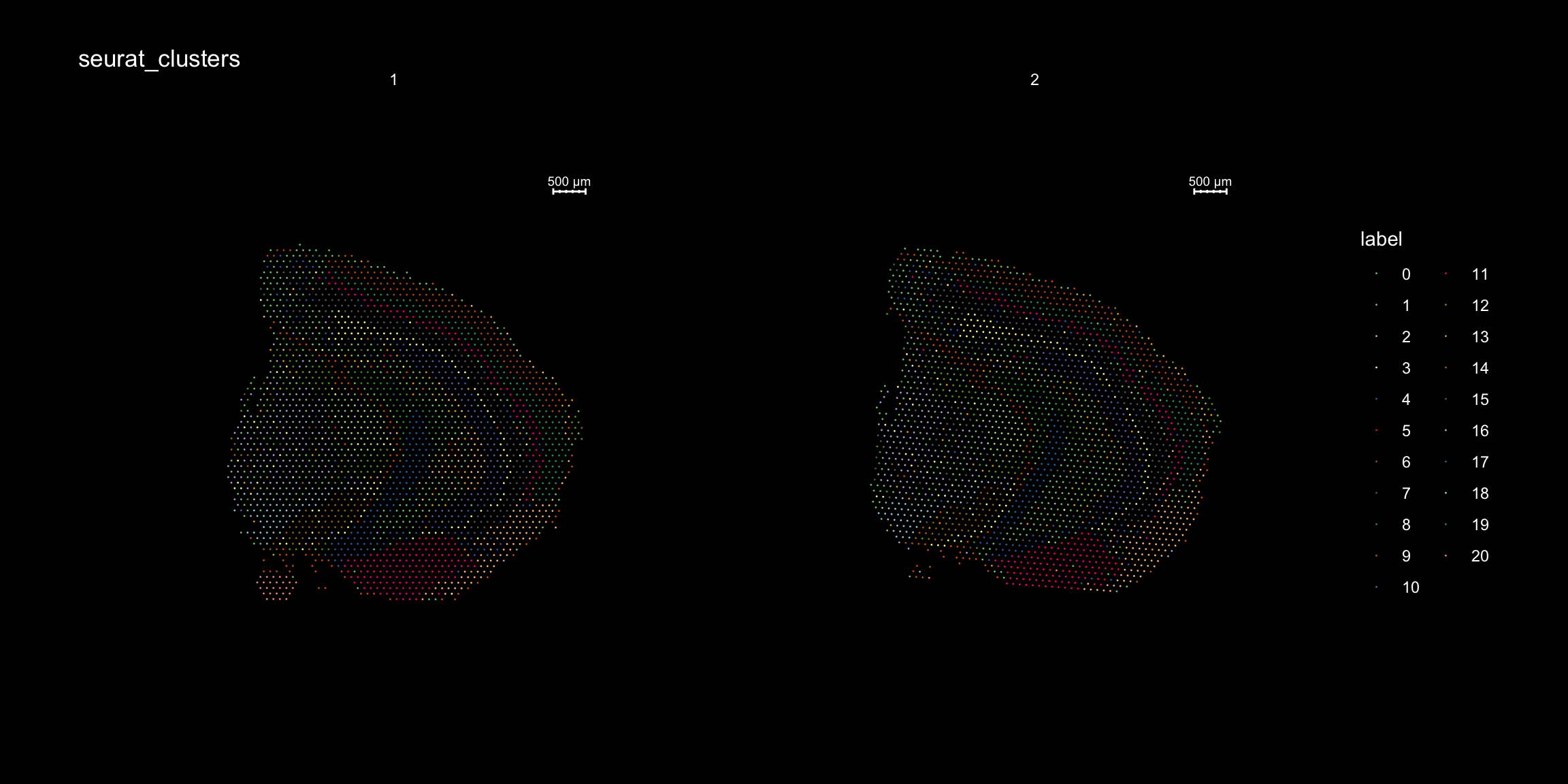
If you think that the distribution of clusters gets too cluttered, you can also split the view so that only one cluster at the time gets colored, just note that you can only do this for one section at the time (set ìndex).
ST.FeaturePlot(object = se, features = "seurat_clusters", dark.theme = T, pt.size = 1, split.labels = T, indices = 1, show.sb = FALSE)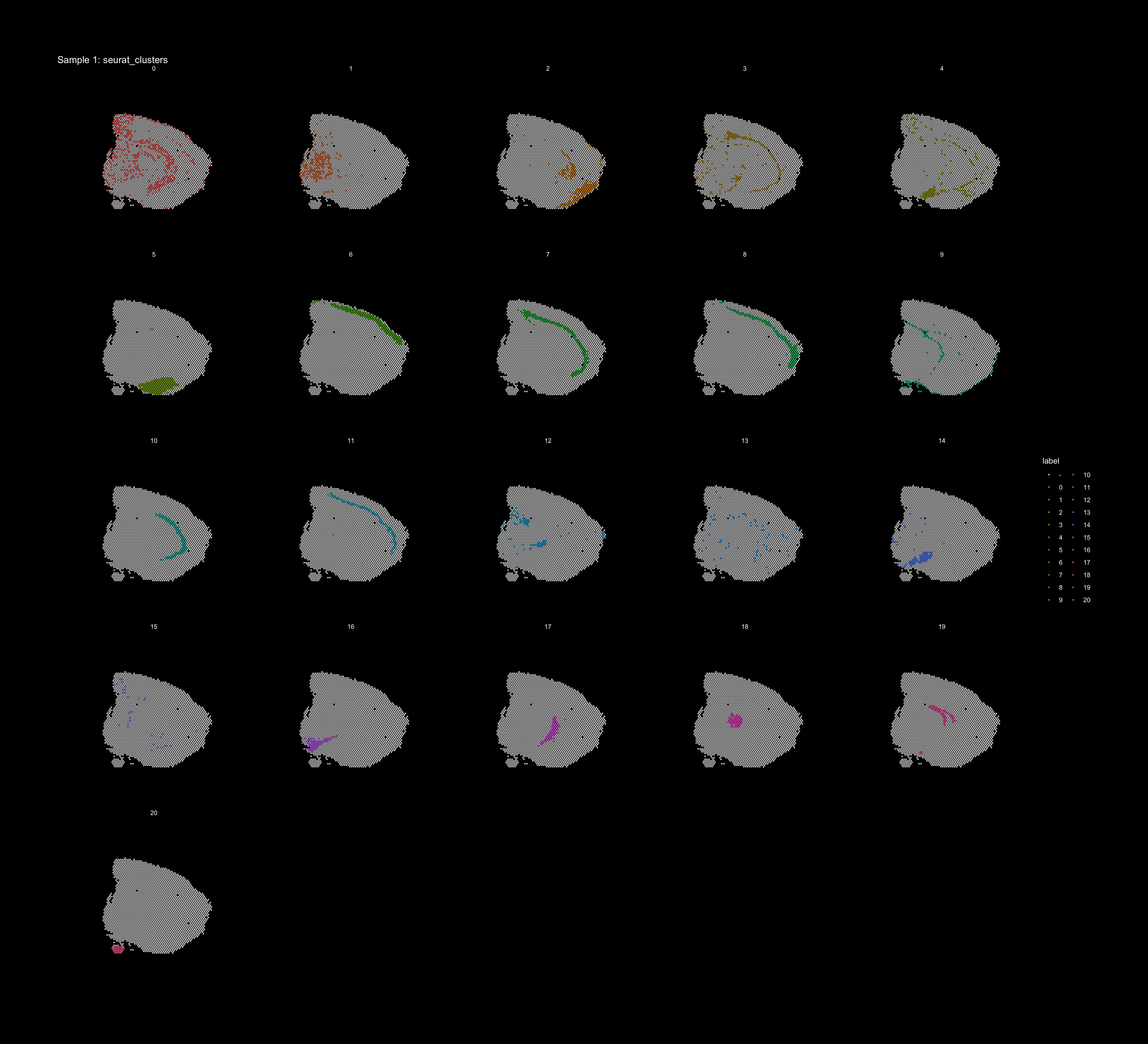
ST.FeaturePlot(object = se, features = "seurat_clusters", dark.theme = T, pt.size = 1, split.labels = T, indices = 2, show.sb = FALSE)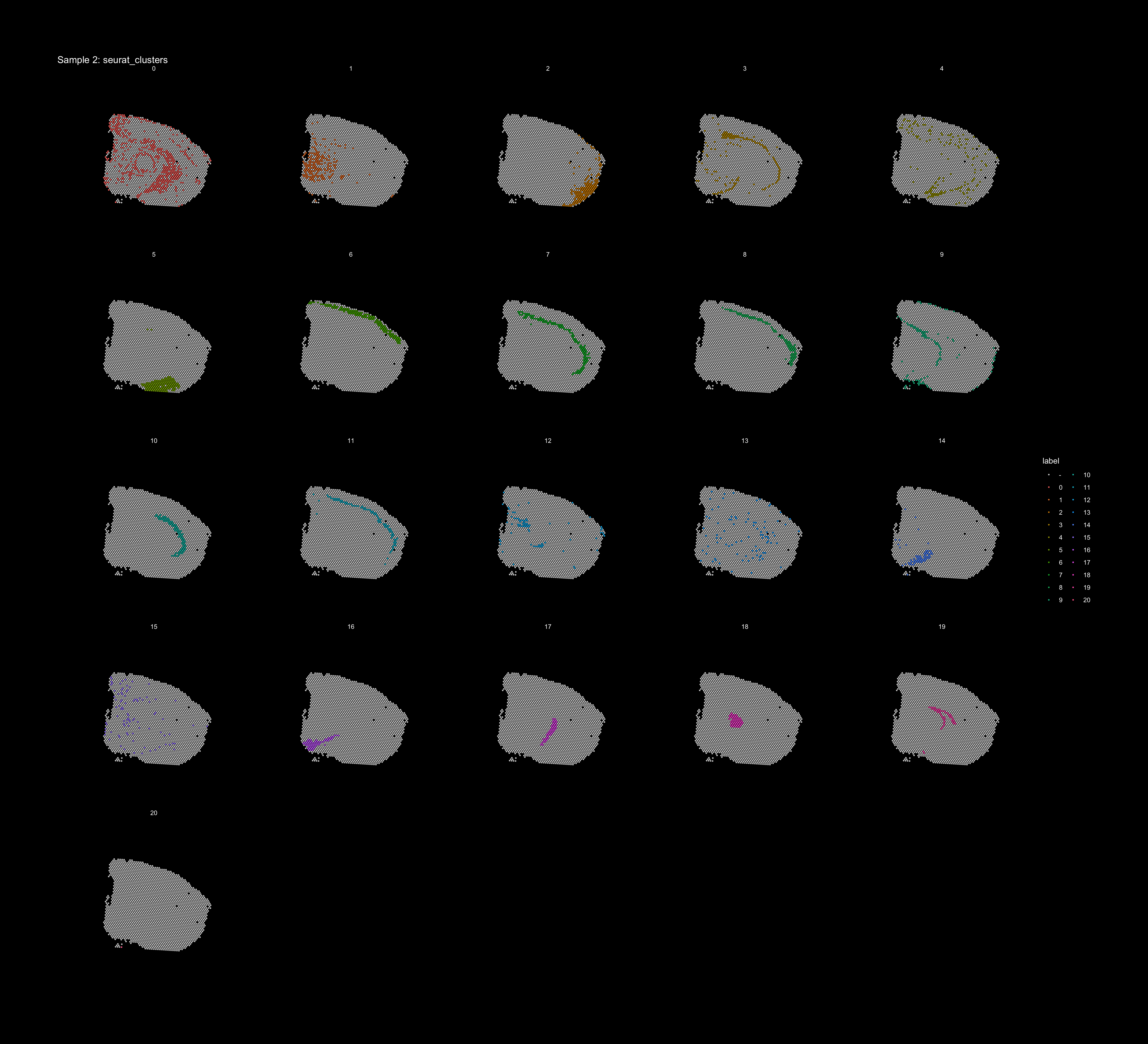
Most variable features
We can take a specific look at some of the most variable features defined during the normalization step.
head(se@assays$SCT@var.features, 20) [1] "Hbb-bs" "Hba-a1" "Hba-a2" "Plp1" "Mbp" "Ptgds" "Hbb-bt"
[8] "Slc6a3" "Sst" "Th" "Ddc" "Npy" "Slc18a2" "Mobp"
[15] "Nrgn" "Mal" "Pcp4" "Prkcd" "Apod" "Myoc" top <- se@assays$SCT@var.features
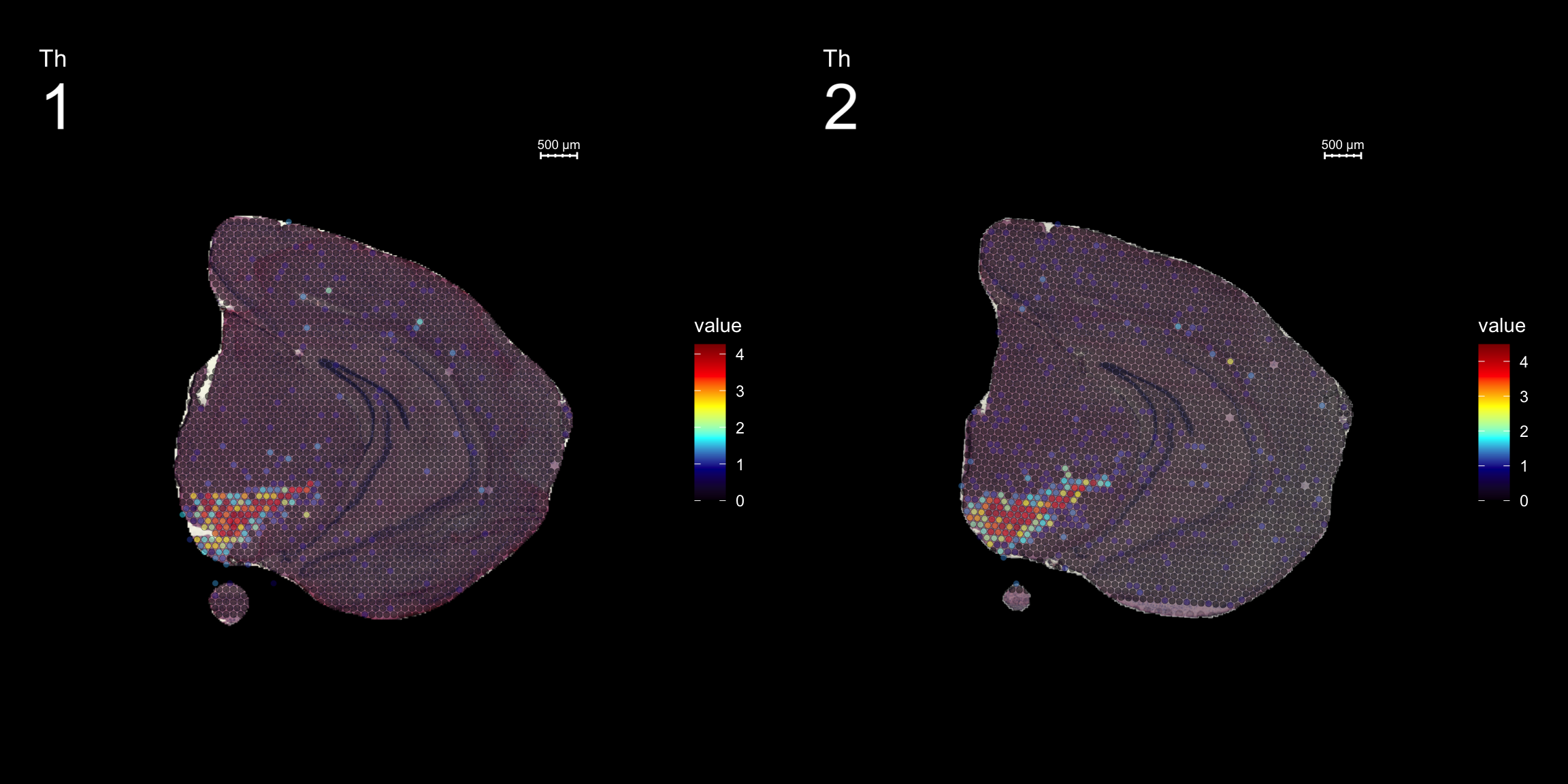
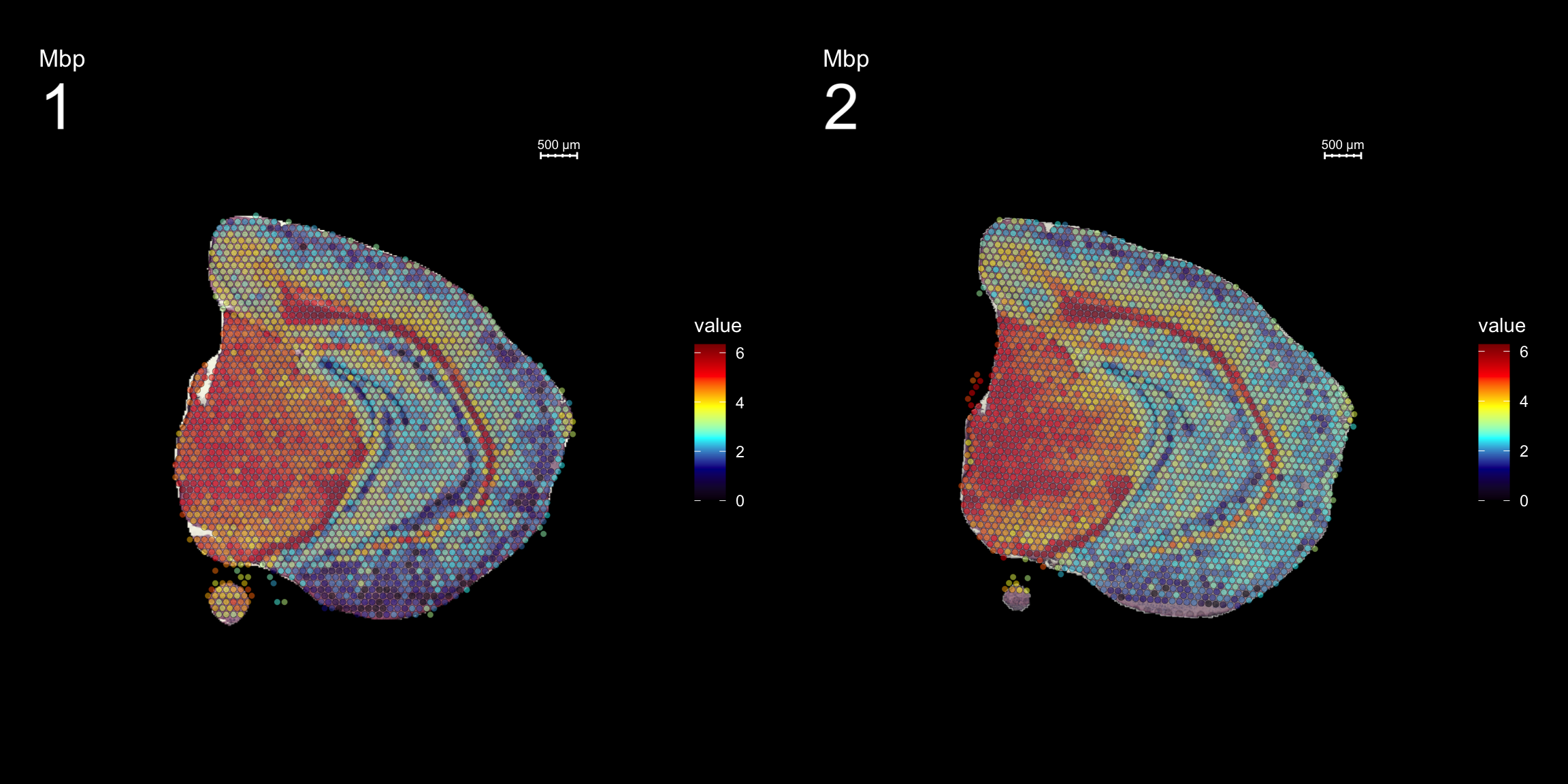
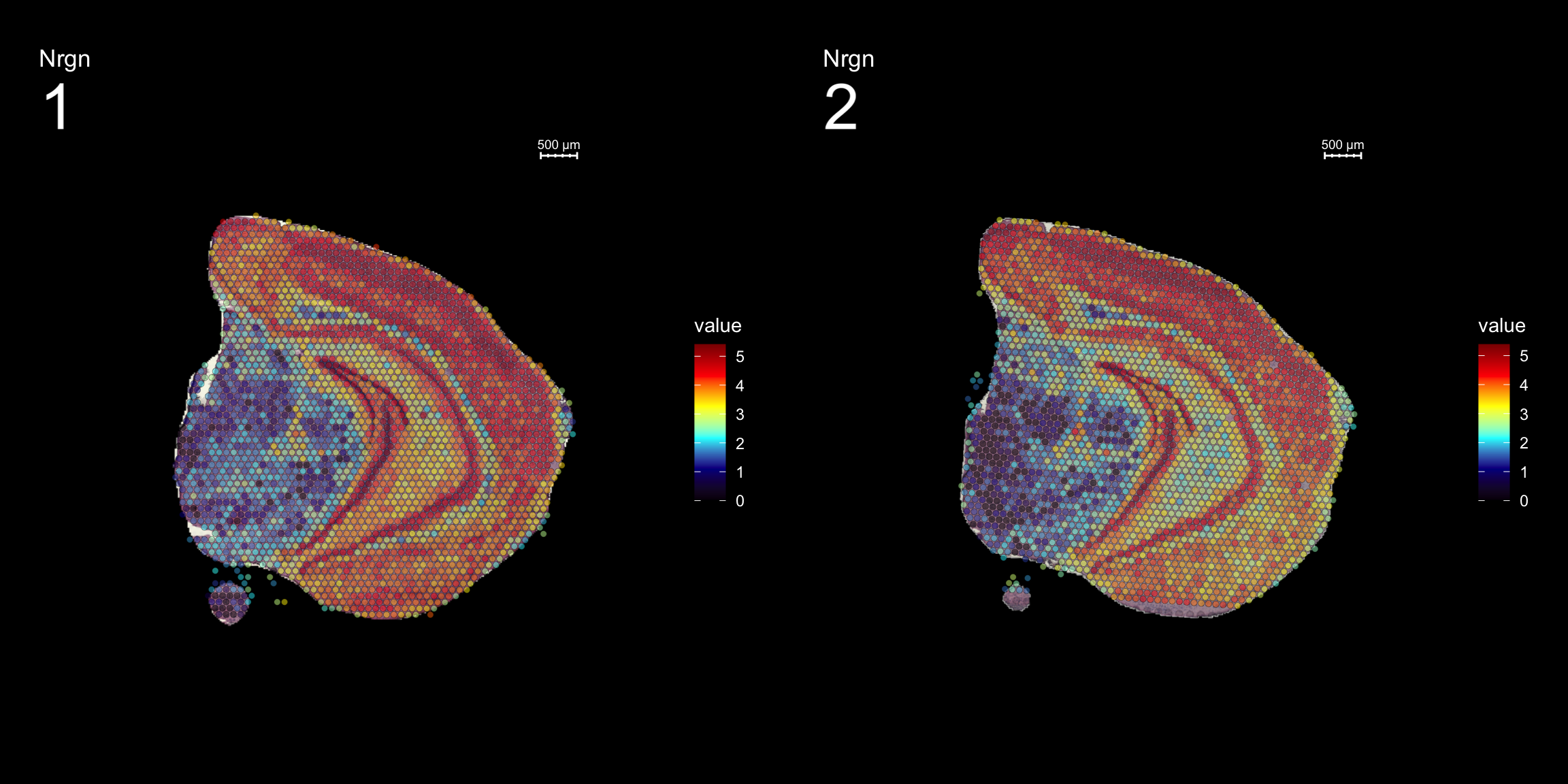
fts <- c("Th", "Mbp", "Nrgn")
for (ftr in fts) {
p <- FeatureOverlay(se,
features = ftr,
sampleids = 1:2,
cols = c("black", "darkblue", "cyan", "yellow", "red", "darkred"),
pt.size = 1.5,
pt.alpha = 0.5,
dark.theme = T,
ncols.samples = 2)
print(p)
}
Compare graph embeddings
Another useful feature is that you can now compare the spatial distribution of a gene with the typical “graph embeddings” s.a. UMAP and t-SNE.
# Run UMAP
se <- RunUMAP(se, reduction = "NMF", dims = 1:40, n.neighbors = 10)# Define colors for heatmap
heatmap.colors <- viridis::viridis(n = 9)
fts <- c("Prkcd", "Opalin", "Lamp5")
# plot transformed features expression on UMAP embedding
p.fts <- lapply(fts, function(ftr) {
FeaturePlot(se, features = ftr, reduction = "umap", order = TRUE, cols = heatmap.colors) + DarkTheme()
})
# plot transformed features expression on Visium coordinates
p3 <- ST.FeaturePlot(se, features = fts, ncol = 2, grid.ncol = 1, cols = heatmap.colors, pt.size = 1, dark.theme = T, show.sb = FALSE)
# Construct final plot
cowplot::plot_grid(cowplot::plot_grid(plotlist = p.fts, ncol = 1), p3, ncol = 2, rel_widths = c(1, 1.3))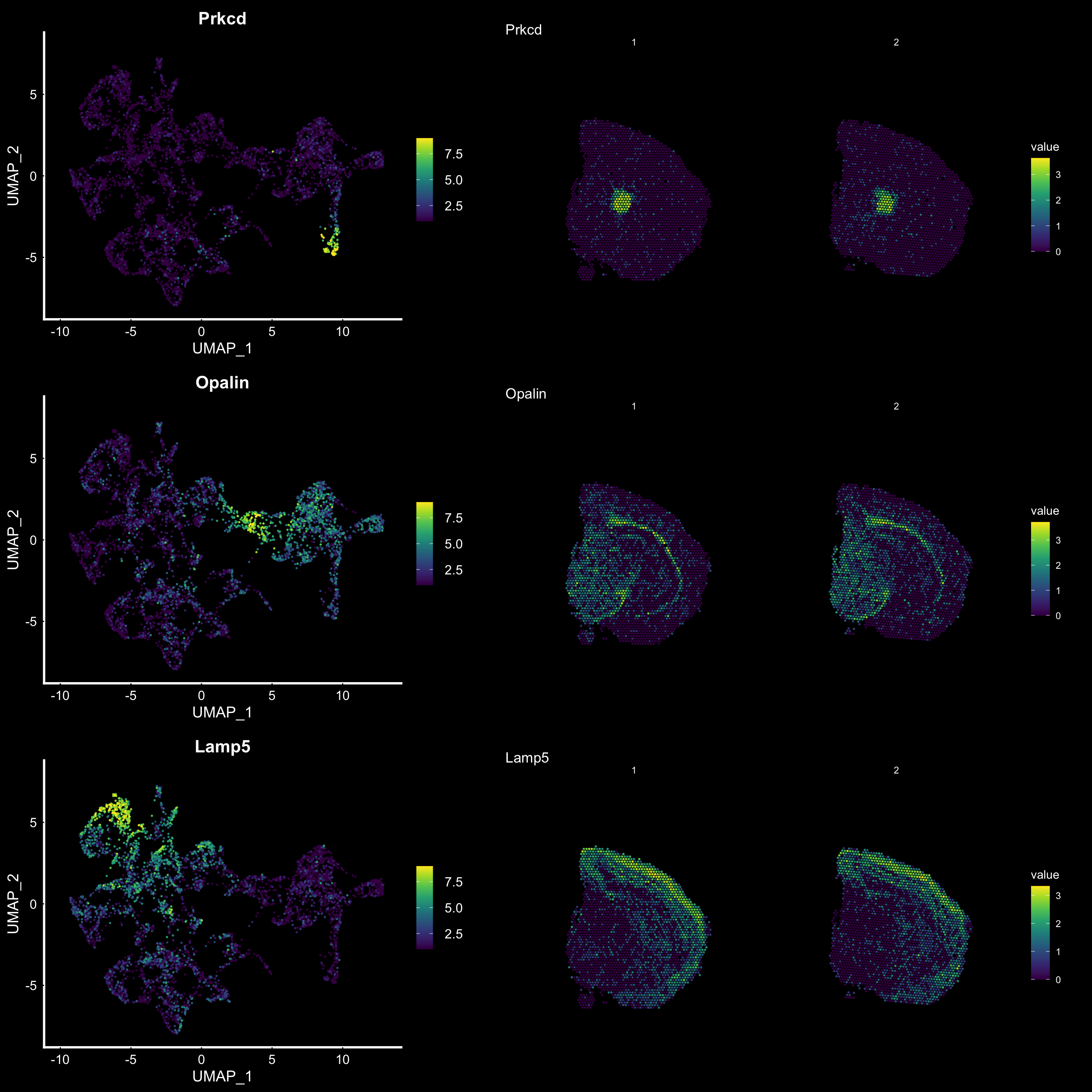
RGB dimensionality reduction plots
One approach to visualize the result of dimensionality reduction is to use the first three dimensions and transform the values into RGB color space. This 3 dimensional space can then be utilized for spatial visualization. We demonstrate the technique with UMAP, using our factors as input:
se <- RunUMAP(object = se, dims = 1:40, verbose = FALSE, n.components = 3, reduction = "NMF", reduction.name = "umap.3d")
We use the first three dimensions for plotting:
ST.DimPlot(object = se, dims = 1:3, reduction = "umap.3d", blend = T, dark.theme = T, pt.size = 1.5)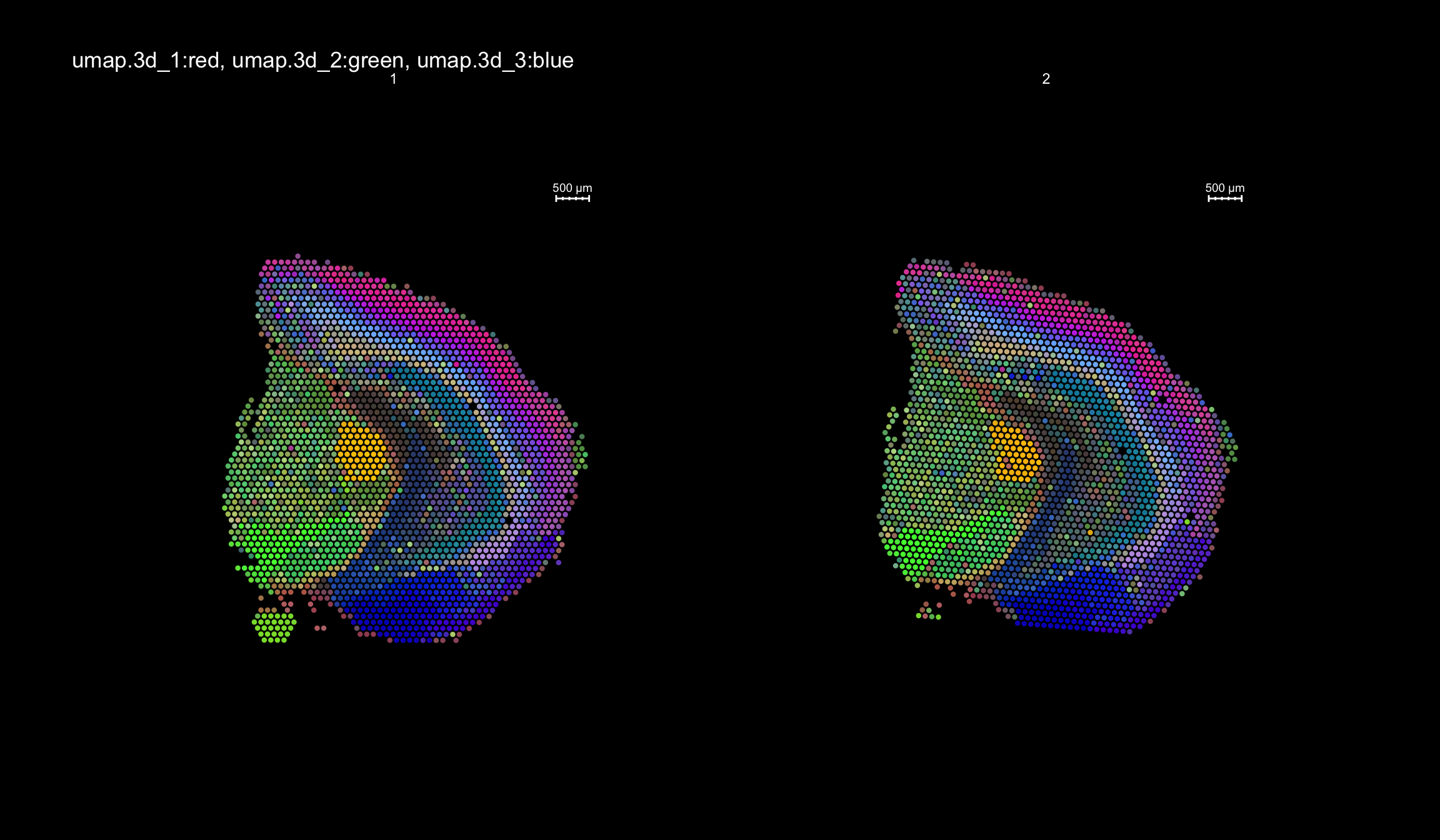
DEA
Lets try this out by an example. Looking at , lets say we are interested in cluster 19, and want to answer - “Which genes are significantly up-regulated in this region compared to the overall expression across the tissue?”
markers <- FindMarkers(se, ident.1 = "19")
head(markers) p_val avg_logFC pct.1 pct.2 p_val_adj
Dsp 0.000000e+00 1.2427413 0.818 0.015 0.000000e+00
Lct 0.000000e+00 0.9157160 0.768 0.021 0.000000e+00
Tdo2 3.125802e-267 0.7143539 0.707 0.026 4.200140e-263
Capn3 4.582401e-158 1.1263876 0.859 0.084 6.157372e-154
Prox1 6.644757e-139 1.1988020 0.919 0.117 8.928560e-135
C1ql2 1.183283e-134 1.7382051 1.000 0.169 1.589977e-130Note that the clusters were already set as the Seurat objects levels. Type levels(se) to see the current levels of your object. If other clusters, annotations etc are of interest, set this before by specifying Idents(se) <-
Note also, if we are interested in comparing two levels against each other, and not just “one against the rest”, we simply add a ident.2 = parameter to the above.
FeatureOverlay(se, features = "Dsp",
sampleids = 1:2,
cols = c("darkblue", "cyan", "yellow", "red", "darkred"),
pt.size = 1.5,
pt.alpha = 0.5,
ncols.samples = 2,
dark.theme = T)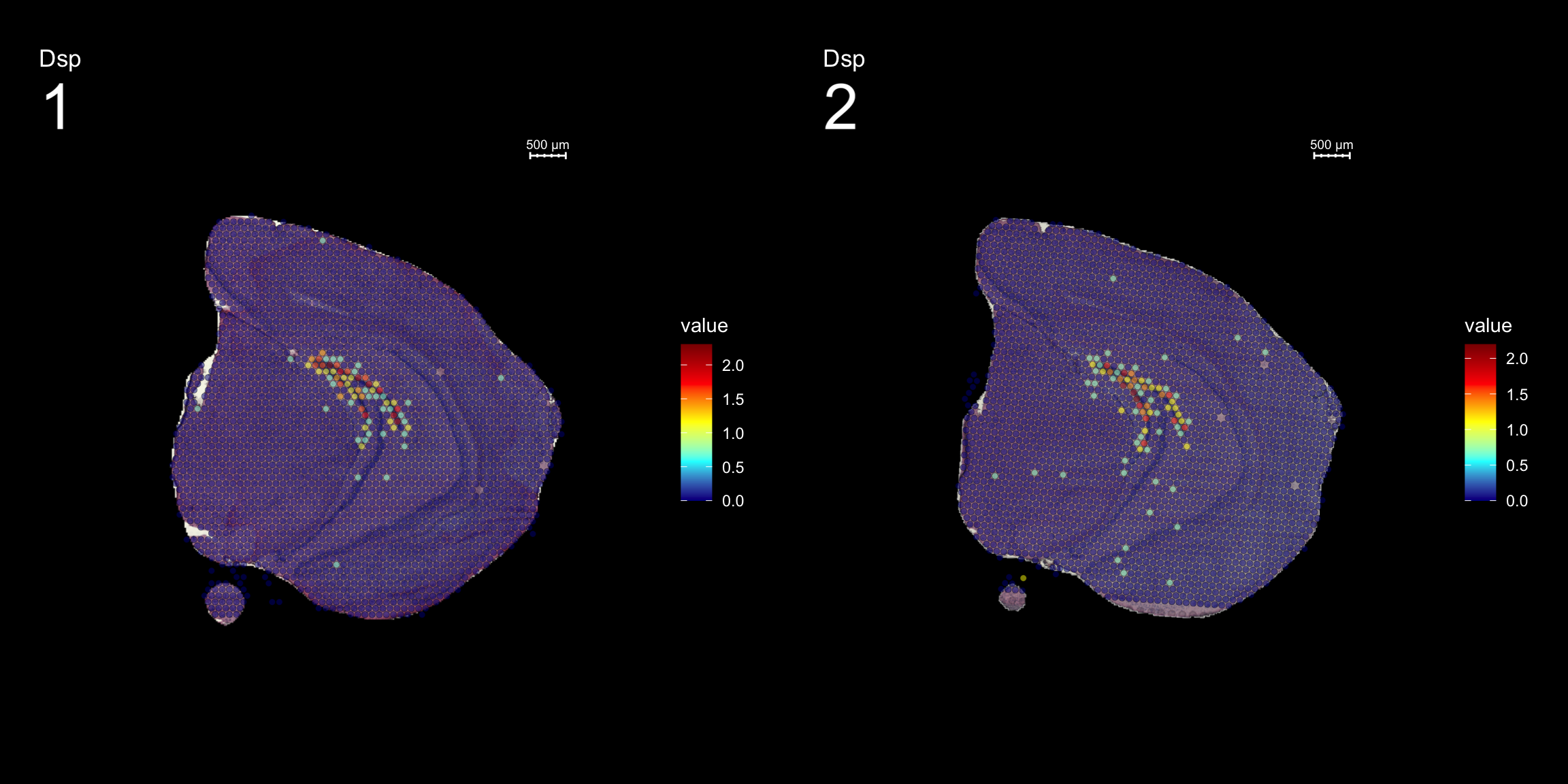
| Version | Author | Date |
|---|---|---|
| 4f42429 | Ludvig Larsson | 2020-06-04 |
Spatial Auto-correlation
STUtility also includes an additional method for finding genes with spatial patterns across the tissue. The ranking method makes use neighborhood networks to compute the spatial lag for each gene, here defined as the summed expression of that gene in neighboring spots. Each gene is then ranked by the correlation between the lag vector and the original expression vector. The output is data.frame genes ranked by correlation between the two vectors.
This method is partly inspired by work from the Giotto team and we reccomend you to check out their R package Giotto and their preprint; “Giotto, a pipeline for integrative analysis and visualization of single-cell spatial transcriptomic data” that is available on bioRxiv.
library(spdep)
spatgenes <- CorSpatialGenes(se)head(spatgenes) gene cor
Mbp Mbp 0.9203725
Camk2n1 Camk2n1 0.9054777
Slc6a3 Slc6a3 0.8917767
Th Th 0.8762578
Nrgn Nrgn 0.8744128
Tmsb4x Tmsb4x 0.8715944A work by Joseph Bergenstråhle and Ludvig Larsson
sessionInfo()R version 4.0.0 (2020-04-24)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] RColorBrewer_1.1-2 magrittr_1.5
[3] STutility_0.1.0 ggplot2_3.3.0
[5] SingleCellExperiment_1.10.1 SummarizedExperiment_1.18.1
[7] DelayedArray_0.14.0 matrixStats_0.56.0
[9] Biobase_2.48.0 GenomicRanges_1.40.0
[11] GenomeInfoDb_1.24.0 IRanges_2.22.1
[13] S4Vectors_0.26.0 BiocGenerics_0.34.0
[15] Seurat_3.1.5 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] reticulate_1.15 tidyselect_1.0.0 htmlwidgets_1.5.1
[4] grid_4.0.0 Rtsne_0.15 munsell_0.5.0
[7] codetools_0.2-16 ica_1.0-2 units_0.6-6
[10] future_1.17.0 miniUI_0.1.1.1 withr_2.2.0
[13] colorspace_1.4-1 knitr_1.28 uuid_0.1-4
[16] ROCR_1.0-11 tensor_1.5 listenv_0.8.0
[19] labeling_0.3 git2r_0.27.1 GenomeInfoDbData_1.2.3
[22] polyclip_1.10-0 farver_2.0.3 rprojroot_1.3-2
[25] coda_0.19-3 LearnBayes_2.15.1 vctrs_0.3.0
[28] xfun_0.13 R6_2.4.1 doParallel_1.0.15
[31] rsvd_1.0.3 Morpho_2.8 ggiraph_0.7.0
[34] manipulateWidget_0.10.1 bitops_1.0-6 spatstat.utils_1.17-0
[37] assertthat_0.2.1 promises_1.1.0 scales_1.1.0
[40] imager_0.42.1 gtable_0.3.0 npsurv_0.4-0.1
[43] globals_0.12.5 bmp_0.3 goftest_1.2-2
[46] rlang_0.4.6 zeallot_0.1.0 akima_0.6-2
[49] systemfonts_0.2.1 splines_4.0.0 lazyeval_0.2.2
[52] rgl_0.100.54 yaml_2.2.1 reshape2_1.4.4
[55] abind_1.4-5 crosstalk_1.1.0.1 backports_1.1.6
[58] httpuv_1.5.2 tools_4.0.0 spData_0.3.5
[61] ellipsis_0.3.0 raster_3.1-5 Rvcg_0.19.1
[64] ggridges_0.5.2 Rcpp_1.0.4.6 plyr_1.8.6
[67] zlibbioc_1.34.0 classInt_0.4-3 purrr_0.3.4
[70] RCurl_1.98-1.2 rpart_4.1-15 dbscan_1.1-5
[73] deldir_0.1-25 viridis_0.5.1 pbapply_1.4-2
[76] cowplot_1.0.0 zoo_1.8-8 ggrepel_0.8.2
[79] cluster_2.1.0 colorRamps_2.3 fs_1.4.1
[82] data.table_1.12.8 magick_2.3 readbitmap_0.1.5
[85] gmodels_2.18.1 lmtest_0.9-37 RANN_2.6.1
[88] whisker_0.4 fitdistrplus_1.0-14 patchwork_1.0.0
[91] shinyjs_1.1 lsei_1.2-0.1 mime_0.9
[94] evaluate_0.14 xtable_1.8-4 jpeg_0.1-8.1
[97] gridExtra_2.3 compiler_4.0.0 tibble_3.0.1
[100] KernSmooth_2.23-17 crayon_1.3.4 htmltools_0.4.0
[103] mgcv_1.8-31 later_1.0.0 spdep_1.1-3
[106] tiff_0.1-5 tidyr_1.0.3 expm_0.999-4
[109] DBI_1.1.0 MASS_7.3-51.6 sf_0.9-3
[112] boot_1.3-25 Matrix_1.2-18 gdata_2.18.0
[115] igraph_1.2.5 pkgconfig_2.0.3 sp_1.4-1
[118] plotly_4.9.2.1 xml2_1.3.2 foreach_1.5.0
[121] webshot_0.5.2 XVector_0.28.0 stringr_1.4.0
[124] digest_0.6.25 sctransform_0.2.1 RcppAnnoy_0.0.16
[127] tsne_0.1-3 spatstat.data_1.4-3 rmarkdown_2.1
[130] leiden_0.3.3 uwot_0.1.8 gdtools_0.2.2
[133] gtools_3.8.2 shiny_1.4.0.2 lifecycle_0.2.0
[136] nlme_3.1-147 jsonlite_1.6.1 limma_3.44.1
[139] viridisLite_0.3.0 pillar_1.4.4 lattice_0.20-41
[142] fastmap_1.0.1 httr_1.4.1 survival_3.1-12
[145] glue_1.4.0 spatstat_1.63-3 png_0.1-7
[148] iterators_1.0.12 class_7.3-17 stringi_1.4.6
[151] dplyr_0.8.5 irlba_2.3.3 e1071_1.7-3
[154] future.apply_1.5.0 ape_5.3