Plotting the estimated mean phenotype for each DGRP line
Last updated: 2021-10-01
Checks: 7 0
Knit directory: fitnessGWAS/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20180914) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 01226ab. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rapp.history
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: .httr-oauth
Ignored: .pversion
Ignored: analysis/.DS_Store
Ignored: analysis/correlations_SNP_effects_cache/
Ignored: code/.DS_Store
Ignored: code/Drosophila_GWAS.Rmd
Ignored: data/.DS_Store
Ignored: data/derived/
Ignored: data/input/.DS_Store
Ignored: data/input/.pversion
Ignored: data/input/dgrp.fb557.annot.txt
Ignored: data/input/dgrp2.bed
Ignored: data/input/dgrp2.bim
Ignored: data/input/dgrp2.fam
Ignored: data/input/huang_transcriptome/
Ignored: figures/.DS_Store
Ignored: figures/fig1_inkscape.svg
Ignored: figures/figure1a.pdf
Ignored: figures/figure1b.pdf
Untracked files:
Untracked: big_model.rds
Untracked: code/quant_gen_1.R
Untracked: data/input/genomic_relatedness_matrix.rds
Untracked: old_analyses/
Unstaged changes:
Modified: .gitignore
Modified: figures/GWAS_stats_figure.pdf
Modified: figures/SNP_effect_ED.pdf
Modified: figures/TWAS_stats_figure.pdf
Modified: figures/antagonism_ratios.pdf
Modified: figures/boyle_plot.pdf
Modified: figures/composite_mixture_figure.pdf
Modified: figures/eff_size_histos.pdf
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/plot_line_means.Rmd) and HTML (docs/plot_line_means.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 01226ab | lukeholman | 2021-10-01 | wflow_publish("analysis/*") |
| html | 8d14298 | lukeholman | 2021-09-26 | Build site. |
| Rmd | af15dd6 | lukeholman | 2021-09-26 | Commit Sept 2021 |
| html | 871ae81 | lukeholman | 2021-03-04 | Build site. |
| Rmd | a16e751 | lukeholman | 2021-03-04 | big first commit 2021 |
| Rmd | 8d54ea5 | Luke Holman | 2018-12-23 | Initial commit |
| html | 8d54ea5 | Luke Holman | 2018-12-23 | Initial commit |
library(tidyverse)
library(ggExtra)
library(grid)
library(gridExtra)
library(RColorBrewer)
library(showtext) # For fancy Google font in figures
font_add_google(name = "Raleway", family = "Raleway", regular.wt = 400, bold.wt = 700) # Install font from Google Fonts
showtext::showtext.auto()
# Load the predicted line means, as calculated by get_predicted_line_means
predicted_line_means <- read_csv("data/derived/predicted_line_means.csv")Variance and covariance in line mean phenotypes
Generally there is positive covariance between line means for different traits, and all 4 measures of fitness exhibit considerable phenotypic variance across lines.
lims <- c(1.1*min(apply(predicted_line_means[,2:5], 2, min)),
1.1*max(apply(predicted_line_means[,2:5], 2, max)))
fix.title <- function(x){
x[x == "female.fitness.early" | x == "femalefitnessearly"] <- "Female early-life fitness"
x[x == "male.fitness.early" | x == "malefitnessearly"] <- "Male early-life fitness"
x[x == "female.fitness.late" | x == "femalefitnesslate"] <- "Female late-life fitness"
x[x == "male.fitness.late" | x == "malefitnesslate"] <- "Male late-life fitness"
x
}
make_figure_1 <- function(){
nice.plot <- function(df, v1, v2){
formula <- as.formula(paste(v2, "~", v1))
model <- summary(lm(formula, data = df))
r2 <- format(model$r.squared %>% round(2), nsmall = 2)
slope <- format(model$coefficients[2,1] %>% round(2), nsmall = 2)
se <- format(model$coefficients[2,2] %>% round(2), nsmall = 2)
# print(model$coefficients[2,4]) # print p-value of the correlation
text1 <- paste("R^2 == ", r2, sep = "")
text2 <- paste("β = ", slope, " \u00B1 ", se, sep = "")
pp <- df %>%
ggplot(aes_string(x = v1, y = v2)) +
annotate("text", x=min(lims) + 0.1, y=max(lims), label = text1, parse = TRUE, hjust= 0) +
annotate("text", x=min(lims) + 0.1, y=max(lims)-0.4, label = text2, hjust= 0) +
geom_point(alpha = 0.7) +
stat_smooth(method = "lm", level = 0, colour = "tomato") +
xlab(fix.title(v1)) + ylab(fix.title(v2)) +
theme_classic() +
theme(text = element_text(family = "Raleway")) +
scale_x_continuous(limits = lims) +
scale_y_continuous(limits = lims)
if(v1 == "male.fitness.early" & v2 == "female.fitness.early") cols <- c("lightblue", "pink")
if(v1 == "male.fitness.late" & v2 == "female.fitness.late") cols <- c("steelblue", "deeppink2")
if(v1 == "male.fitness.early" & v2 == "male.fitness.late") cols <- c("lightblue", "steelblue")
if(v1 == "female.fitness.early" & v2 == "female.fitness.late") cols <- c("pink", "deeppink2")
ggExtra::ggMarginal(pp, type = "histogram", bins = 15, xparams = list(fill = cols[1]), yparams = list(fill = cols[2]))
}
p1 <- nice.plot(predicted_line_means, "male.fitness.early", "female.fitness.early")
p2 <- nice.plot(predicted_line_means, "male.fitness.late", "female.fitness.late")
p3 <- nice.plot(predicted_line_means, "male.fitness.early", "male.fitness.late")
p4 <- nice.plot(predicted_line_means, "female.fitness.early", "female.fitness.late")
full_plot <- grid.arrange(p1, p2, p3, p4)
# Saving does not work (ggmarginal + showtext issue?), so get it from the HTML output
# svg("figures/figure1.svg", height = 9, width = 9)
# full_plot
# invisible(dev.off())
}
make_figure_1()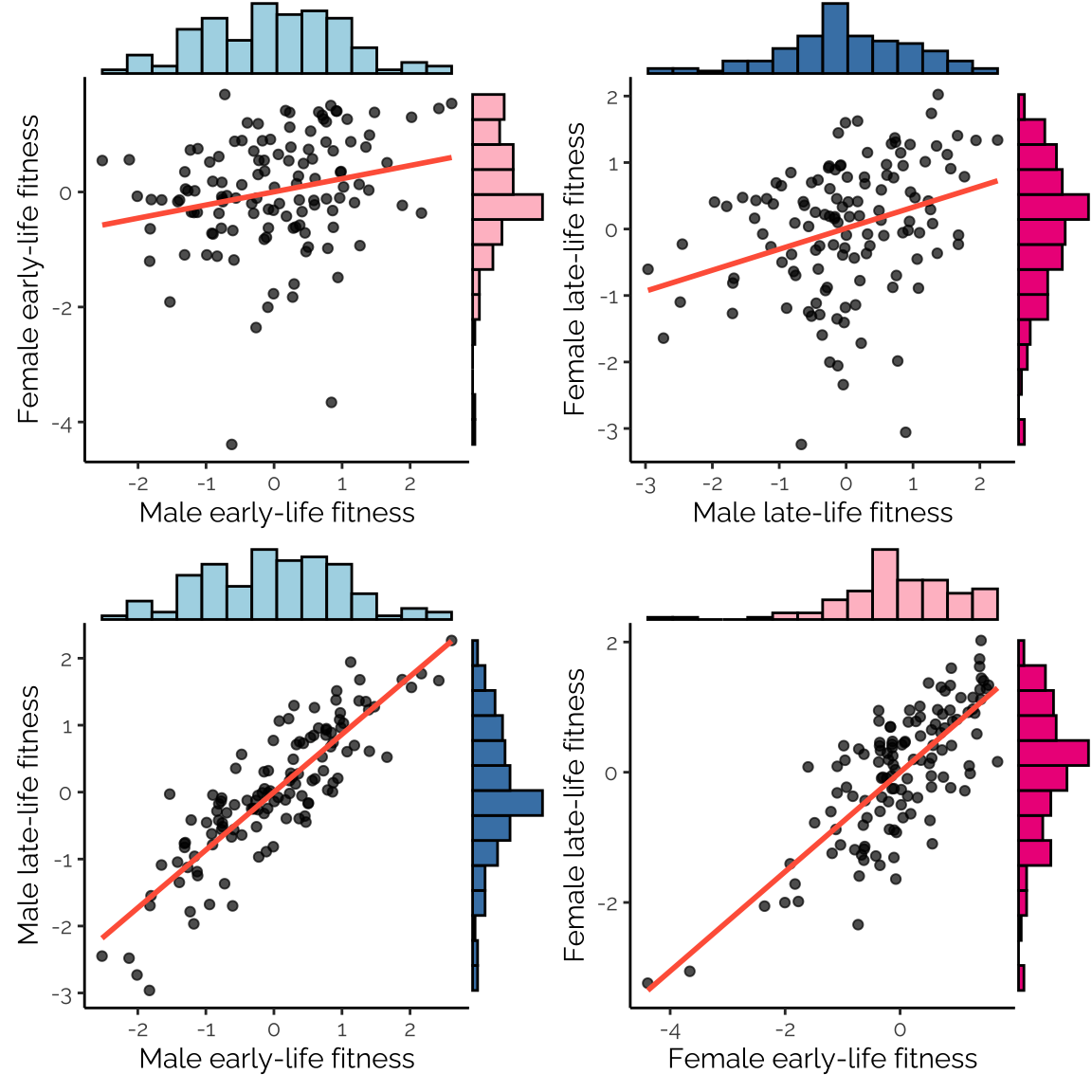
Figure 1: Correlations among estimated line means for the four fitness components. The line means were estimated from Bayesian mixed models that account for block effects, and the non-independence of our early- and late-life fitness measurements.
Interaction plot showing trait covariance across lines
All possible types of lines were observed: some lines are uniformly bad, or uniformly good, or good in one sex or age class but bad in the other.
make_bonus_figure <- function(){
interaction.plot <- function(predicted_line_means, x1, x2, title, sex.or.age){
if(sex.or.age == "sex"){
x.labs <- c("Female", "Male")
cols <- c("steelblue", "darkgrey", "deeppink2")
} else {
x.labs <- c("Early life", "Late life")
cols <- c("green", "darkgrey", "purple")
}
df <- predicted_line_means %>% select(!!x1, !!x2)
df$rank.x1 <- rank(df[,1]) / max(abs(rank(df[,1])))
df$rank.x2 <- rank(df[,2]) / max(abs(rank(df[,2])))
df %>% mutate(slope = rank.x1 - rank.x2,
line = 1:length(rank.x1)) %>%
gather(key = sex_or_age, value = fitness, rank.x1, rank.x2) %>%
mutate(fitness = fitness / max(fitness),
title = title) %>%
ggplot(aes(x = sex_or_age, y = fitness, group = line, colour = slope)) +
geom_line(size = 0.4, alpha = 0.7) +
scale_color_gradient2(low = cols[1], mid = cols[2], high = cols[3]) +
scale_x_discrete(expand = c(0.1,0.1), labels = x.labs) +
theme_classic(15) +
theme(strip.background = element_blank(),
text = element_text(family = "Raleway")) +
xlab(NULL) + ylab(NULL) +
facet_wrap(~title) +
theme(legend.position = "none")
}
full_plot <- grid.arrange(
interaction.plot(predicted_line_means, "female.fitness.early", "male.fitness.early", "Early-life fitness", "sex"),
interaction.plot(predicted_line_means, "female.fitness.late", "male.fitness.late", "Late-life fitness", "sex"),
interaction.plot(predicted_line_means, "female.fitness.early", "female.fitness.late", "Females", "age"),
interaction.plot(predicted_line_means, "male.fitness.early", "male.fitness.late", "Males", "age"),
ncol = 2, left = "Fitness rank among the 125 lines", bottom = "Sex or age category"
)
}
make_bonus_figure()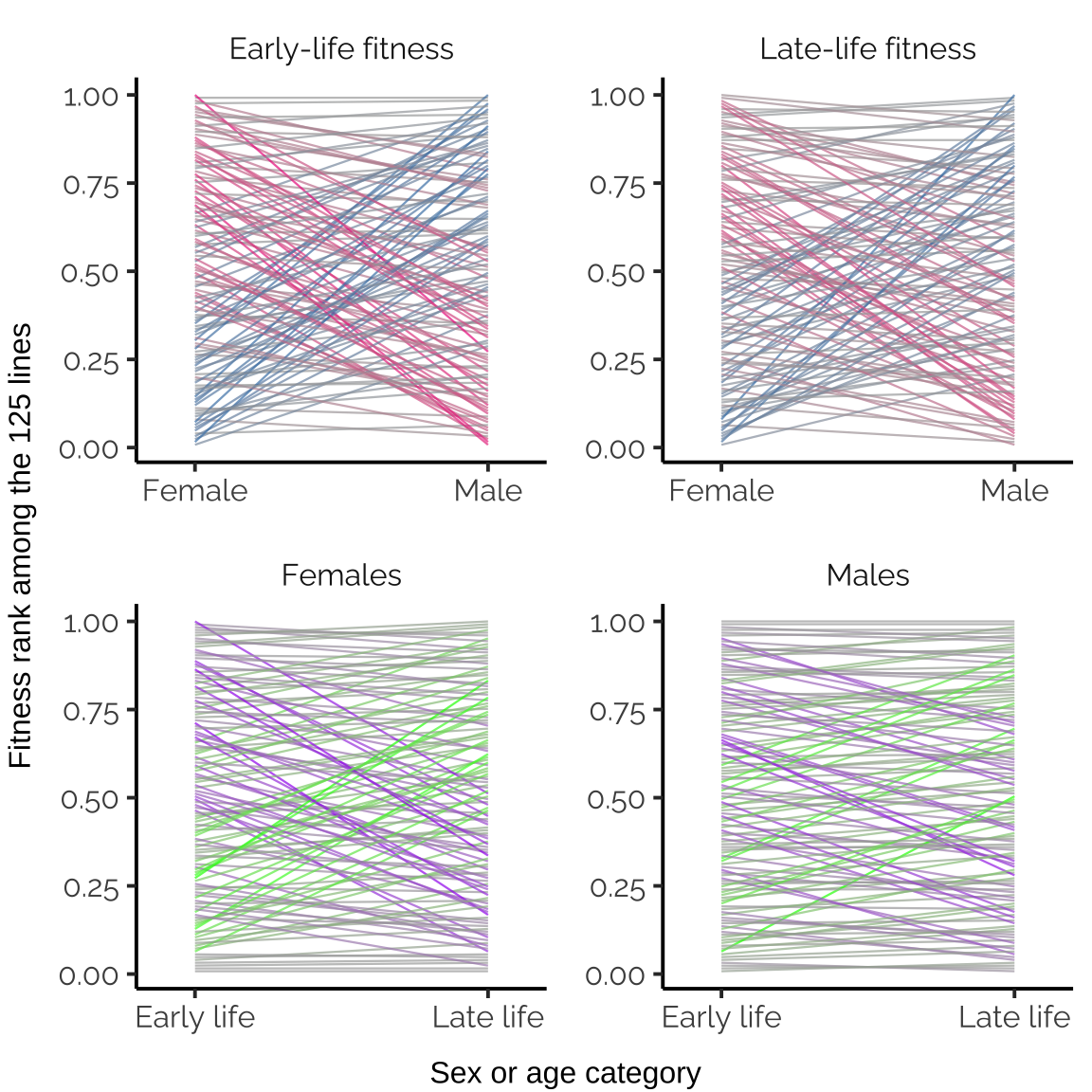
| Version | Author | Date |
|---|---|---|
| 8d14298 | lukeholman | 2021-09-26 |
Bonus figure: The relative fitness ranks for each line, for four pairs of fitness traits. The y-axis was calculated by taking the adjusted line mean fitnesses, ranking them, and then dividing by the number of lines. The intensity and hue of the colour helps highlight genotypes that rank highly for one fitness component but not the other.
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] showtext_0.9-2 showtextdb_3.0 sysfonts_0.8.3 RColorBrewer_1.1-2
[5] gridExtra_2.3 ggExtra_0.9 forcats_0.5.0 stringr_1.4.0
[9] dplyr_1.0.0 purrr_0.3.4 readr_2.0.0 tidyr_1.1.0
[13] tibble_3.0.1 ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] nlme_3.1-149 fs_1.4.1 lubridate_1.7.10 bit64_0.9-7
[5] httr_1.4.1 rprojroot_1.3-2 tools_4.0.3 backports_1.1.7
[9] R6_2.4.1 DBI_1.1.0 mgcv_1.8-33 colorspace_1.4-1
[13] withr_2.2.0 tidyselect_1.1.0 bit_1.1-15.2 curl_4.3
[17] compiler_4.0.3 git2r_0.27.1 cli_2.0.2 rvest_0.3.5
[21] xml2_1.3.2 labeling_0.3 scales_1.1.1 digest_0.6.25
[25] rmarkdown_2.5 pkgconfig_2.0.3 htmltools_0.5.0 dbplyr_1.4.4
[29] fastmap_1.0.1 highr_0.8 rlang_0.4.6 readxl_1.3.1
[33] rstudioapi_0.11 shiny_1.4.0.2 generics_0.0.2 farver_2.0.3
[37] jsonlite_1.7.0 vroom_1.5.3 magrittr_2.0.1 Matrix_1.2-18
[41] Rcpp_1.0.4.6 munsell_0.5.0 fansi_0.4.1 lifecycle_0.2.0
[45] stringi_1.5.3 whisker_0.4 yaml_2.2.1 blob_1.2.1
[49] parallel_4.0.3 promises_1.1.0 crayon_1.3.4 miniUI_0.1.1.1
[53] lattice_0.20-41 haven_2.3.1 splines_4.0.3 hms_0.5.3
[57] knitr_1.32 pillar_1.4.4 reprex_0.3.0 glue_1.4.2
[61] evaluate_0.14 modelr_0.1.8 vctrs_0.3.0 tzdb_0.1.2
[65] httpuv_1.5.3.1 cellranger_1.1.0 gtable_0.3.0 assertthat_0.2.1
[69] xfun_0.22 mime_0.9 xtable_1.8-4 broom_0.5.6
[73] later_1.0.0 ellipsis_0.3.1