Merge samples
Mechthild Lütge
14 May 2020
Last updated: 2022-05-09
Checks: 6 1
Knit directory: humanCardiacFibroblasts/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of the R Markdown file created these results, you’ll want to first commit it to the Git repo. If you’re still working on the analysis, you can ignore this warning. When you’re finished, you can run wflow_publish to commit the R Markdown file and build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210903) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 70e878c. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figure/
Ignored: data/humanFibroblast/
Unstaged changes:
Modified: analysis/Vis_plus_analyse_NormlaHFMyo.Rmd
Modified: analysis/Vis_plus_analyse_NormlaHFMyo_woECMO4.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/Vis_plus_analyse_NormlaHFMyo.Rmd) and HTML (docs/Vis_plus_analyse_NormlaHFMyo.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 70e878c | mluetge | 2022-05-02 | update grand application plots |
| html | 70e878c | mluetge | 2022-05-02 | update grand application plots |
load packages
suppressPackageStartupMessages({
library(SingleCellExperiment)
library(tidyverse)
library(Seurat)
library(magrittr)
library(dplyr)
library(purrr)
library(ggplot2)
library(here)
library(runSeurat3)
library(ggsci)
library(ggpubr)
library(pheatmap)
library(viridis)
library(sctransform)
})sign plot funct
## adapted from CellMixS
visGroup_adapt <- function (sce,group,dim_red = "TSNE",col_group=pal_nejm()(8))
{
if (!is(sce, "SingleCellExperiment")) {
stop("Error:'sce' must be a 'SingleCellExperiment' object.")
}
if (!group %in% names(colData(sce))) {
stop("Error: 'group' variable must be in 'colData(sce)'")
}
cell_names <- colnames(sce)
if (!dim_red %in% "TSNE") {
if (!dim_red %in% reducedDimNames(sce)) {
stop("Please provide a dim_red method listed in reducedDims of sce")
}
red_dim <- as.data.frame(reducedDim(sce, dim_red))
}
else {
if (!"TSNE" %in% reducedDimNames(sce)) {
if ("logcounts" %in% names(assays(sce))) {
sce <- runTSNE(sce)
}
else {
sce <- runTSNE(sce, exprs_values = "counts")
}
}
red_dim <- as.data.frame(reducedDim(sce, "TSNE"))
}
colnames(red_dim) <- c("red_dim1", "red_dim2")
df <- data.frame(sample_id = cell_names, group_var = colData(sce)[,
group], red_Dim1 = red_dim$red_dim1, red_Dim2 = red_dim$red_dim2)
t <- ggplot(df, aes_string(x = "red_Dim1", y = "red_Dim2")) +
xlab(paste0(dim_red, "_1")) + ylab(paste0(dim_red, "_2")) +
theme_void() + theme(aspect.ratio = 1,
panel.grid.minor = element_blank(),
panel.grid.major = element_line(color = "grey", size = 0.3))
t_group <- t + geom_point(size = 1.5, alpha = 0.8,
aes_string(color = "group_var")) +
guides(color = guide_legend(override.aes = list(size = 1),
title = group)) + ggtitle(group)
if (is.numeric(df$group_var)) {
t_group <- t_group + scale_color_viridis(option = "D")
}
else {
t_group <- t_group + scale_color_manual(values = col_group)
}
t_group
}set dir
basedir <- here()
seurat <- readRDS(file = paste0(basedir,
"/data/humanHearts_merged_seurat.rds"))
seurat$ID[which(seurat$ID == "ID23_25")] <- "ID2325"
## subset on sel patients
selPat <- c("ID2325", "ID28", "ID30", "ID31", "ID21", "ID26", "ECMO4", "ID29")
seurat <- subset(seurat, ID %in% selPat)
#seurat <- rerunSeurat3(seurat)
seurat$grp <- "normal"
seurat$grp[which(seurat$ID %in% c("ID21", "ID26"))] <- "HF"
seurat$grp[which(seurat$ID %in% c("ID30", "ID31", "ID29"))] <- "Myocarditis"
#Idents(seurat) <- seurat$RNA_snn_res.0.25
## integrate data across patients
Idents(seurat) <- seurat$ID
seurat.list <- SplitObject(object = seurat, split.by = "ID")
for (i in 1:length(x = seurat.list)) {
seurat.list[[i]] <- NormalizeData(object = seurat.list[[i]],
verbose = FALSE)
seurat.list[[i]] <- FindVariableFeatures(object = seurat.list[[i]],
selection.method = "vst", nfeatures = 2000, verbose = FALSE)
}
seurat.anchors <- FindIntegrationAnchors(object.list = seurat.list, dims = 1:15)
seurat.int <- IntegrateData(anchorset = seurat.anchors, dims = 1:15)
DefaultAssay(object = seurat.int) <- "integrated"
# rerun seurat
seurat.int <- ScaleData(object = seurat.int, verbose = FALSE,
features = rownames(seurat.int))
seurat.int <- RunPCA(object = seurat.int, npcs = 20, verbose = FALSE)
seurat.int <- RunTSNE(object = seurat.int, reduction = "pca", dims = 1:20)
seurat.int <- RunUMAP(object = seurat.int, reduction = "pca", dims = 1:20)
seurat.int <- FindNeighbors(object = seurat.int, reduction = "pca", dims = 1:20)
res <- c(0.6,0.8,0.4,0.25)
for(i in 1:length(res)){
seurat.int <- FindClusters(object = seurat.int, resolution = res[i],
random.seed = 1234)
}Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11281
Number of edges: 505870
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9194
Number of communities: 17
Elapsed time: 1 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11281
Number of edges: 505870
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9017
Number of communities: 19
Elapsed time: 1 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11281
Number of edges: 505870
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9402
Number of communities: 14
Elapsed time: 1 seconds
Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
Number of nodes: 11281
Number of edges: 505870
Running Louvain algorithm...
Maximum modularity in 10 random starts: 0.9587
Number of communities: 12
Elapsed time: 1 secondsDefaultAssay(object = seurat.int) <- "RNA"
seurat <- seurat.int
remove(seurat.int)color vectors
colPal <- pal_igv()(length(levels(seurat)))
colTec <- pal_jama()(length(unique(seurat$technique)))
colSmp <- c(pal_uchicago()(8), pal_npg()(8), pal_aaas()(10))[1:length(unique(seurat$dataset))]
colLoc <- pal_npg()(length(unique(seurat$location)))
colBatch <- c(pal_jco()(10), pal_npg()(10))[1:length(unique(seurat$ID))]
colOrig <- pal_futurama()(length(unique(seurat$origin)))
colIso <- pal_nejm()(length(unique(seurat$isolation)))
colGrp <- c("#b6bcbb", "#a32d25", "#2544a3")
names(colPal) <- levels(seurat)
names(colTec) <- unique(seurat$technique)
names(colSmp) <- unique(seurat$dataset)
names(colLoc) <- unique(seurat$location)
names(colBatch) <- unique(seurat$ID)
names(colOrig) <- unique(seurat$origin)
names(colIso) <- unique(seurat$isolation)
names(colGrp) <- c("normal", "Myocarditis", "HF")vis data
clusters
DimPlot(seurat, reduction = "umap", cols=colPal)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")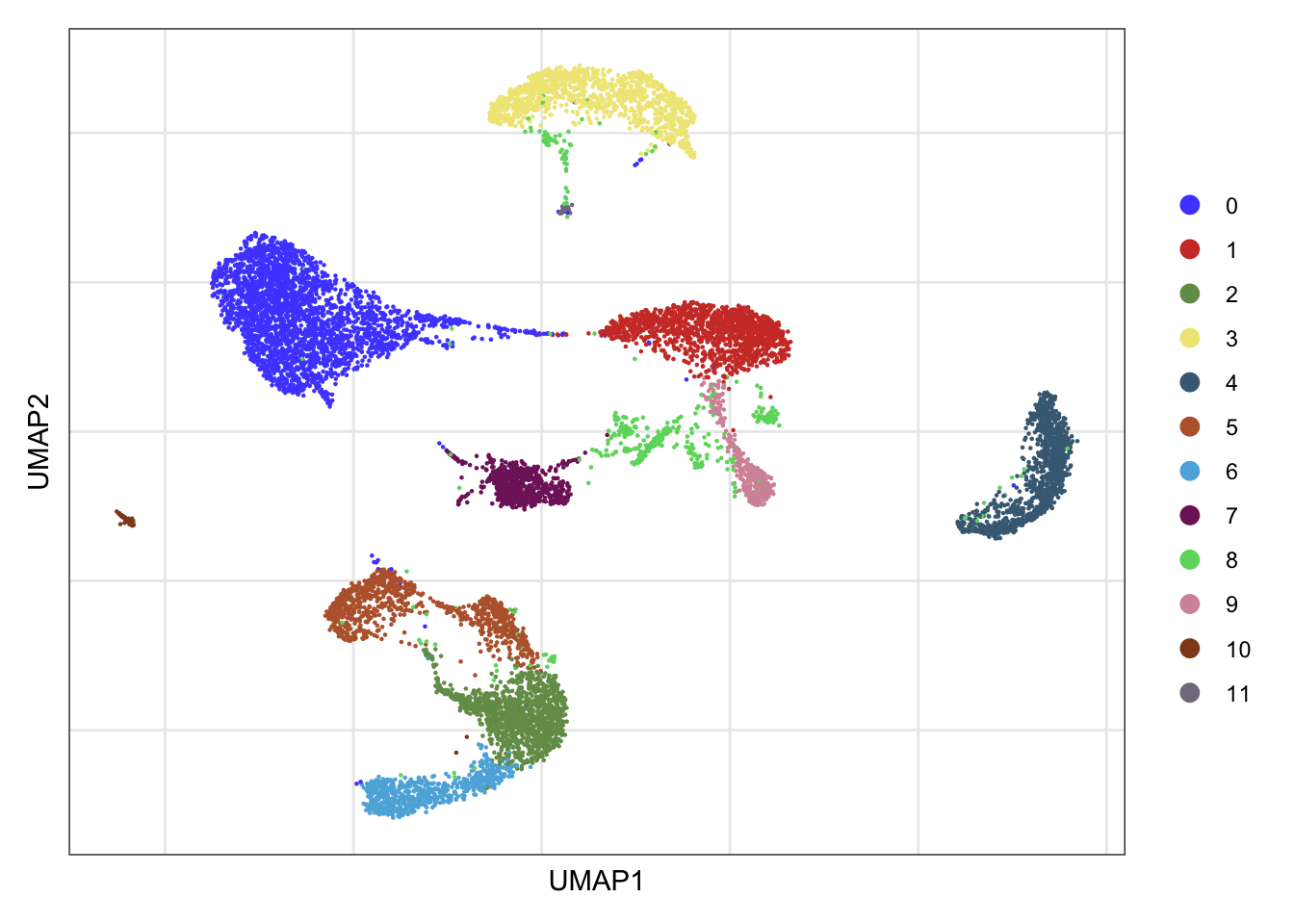
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
DimPlot(seurat, reduction = "umap", cols=colPal,
pt.size=0.6)+
theme_void()
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
technique
DimPlot(seurat, reduction = "umap", group.by = "technique", cols=colTec)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")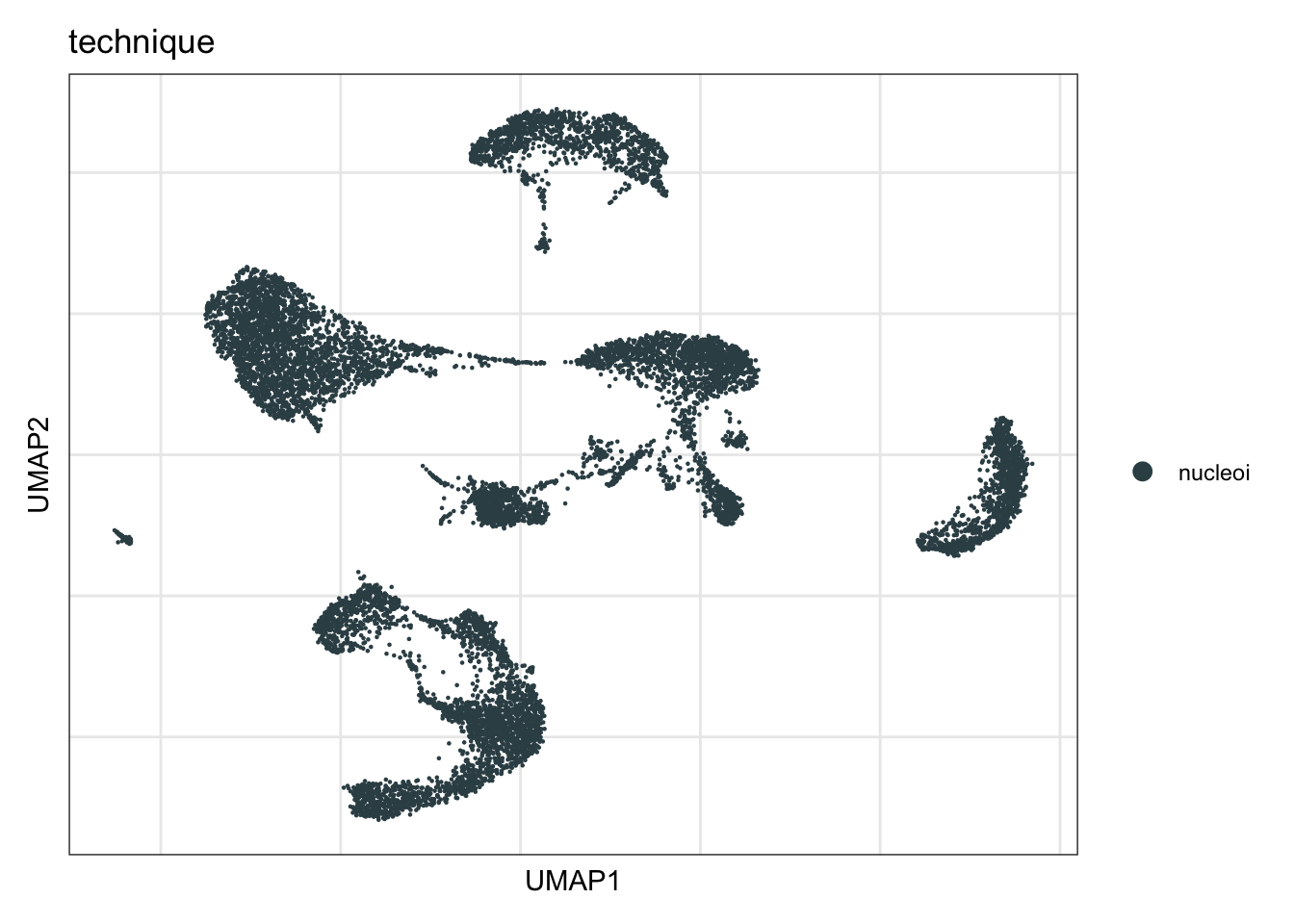
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
Sample
DimPlot(seurat, reduction = "umap", group.by = "dataset", cols=colSmp)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
ID
DimPlot(seurat, reduction = "umap", group.by = "ID", cols=colBatch)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")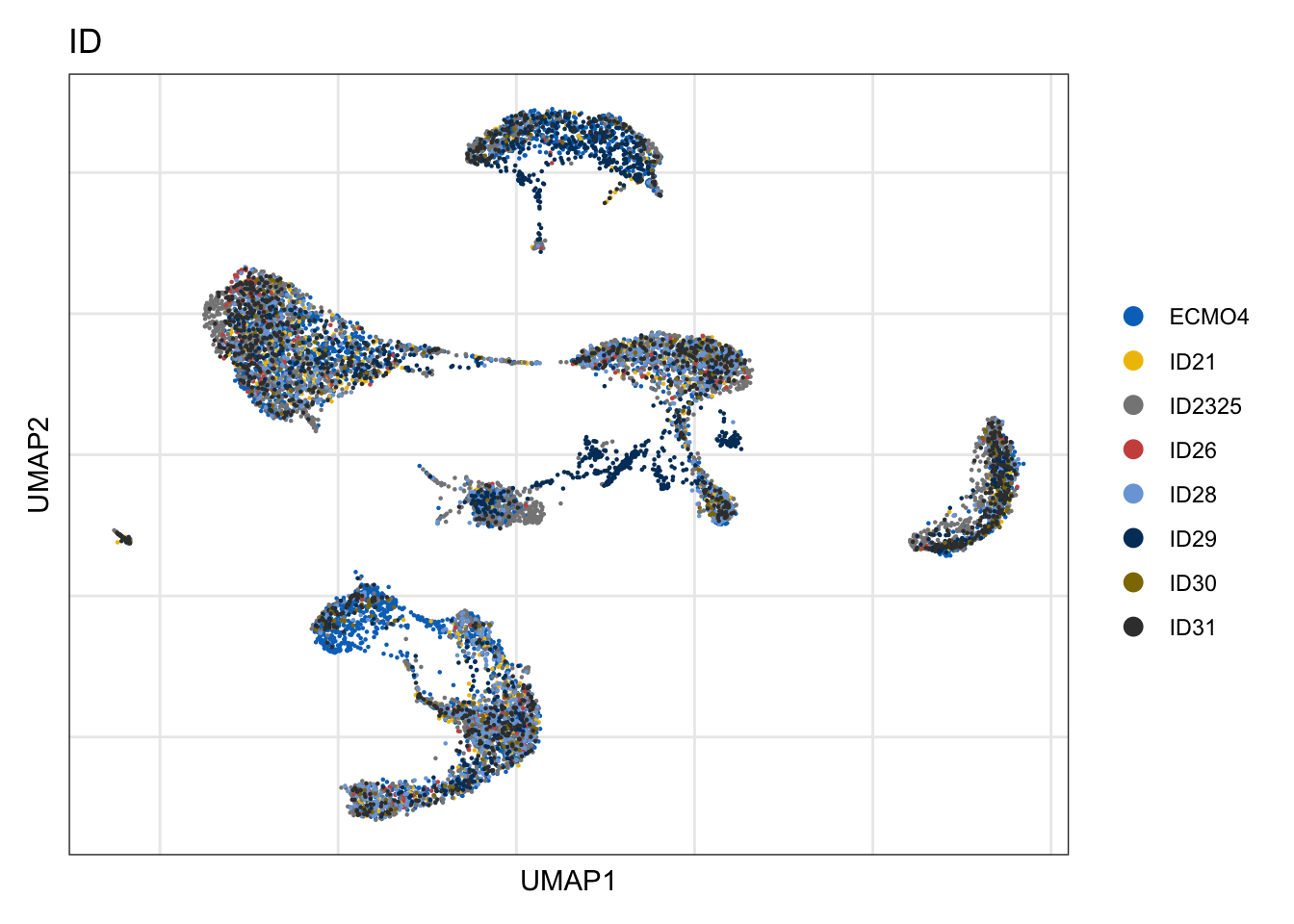
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
DimPlot(seurat, reduction = "umap", group.by = "ID", cols=colBatch,
pt.size=0.6, shuffle = T)+
theme_void()
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
Origin
DimPlot(seurat, reduction = "umap", group.by = "origin", cols=colOrig)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")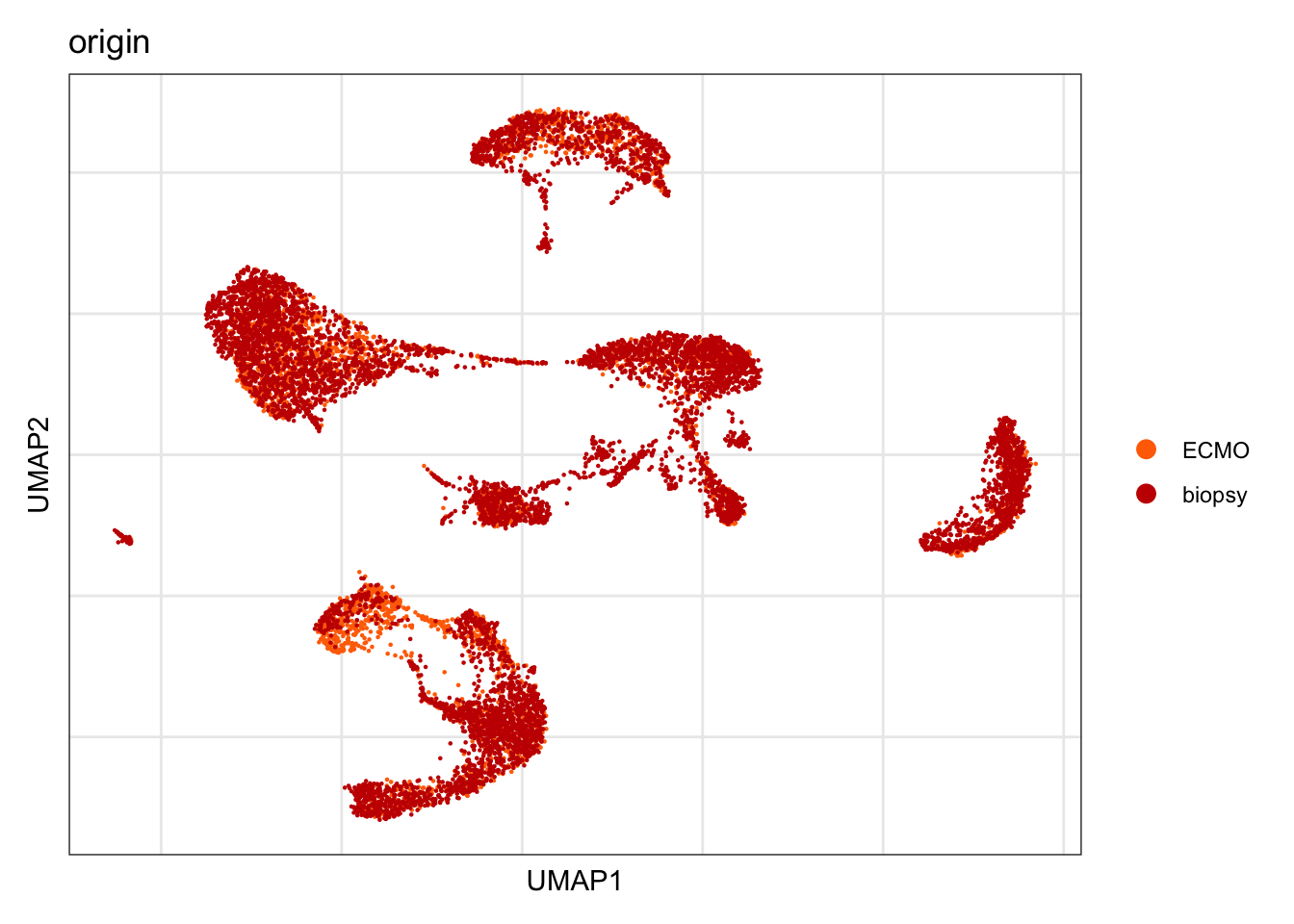
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
isolation
DimPlot(seurat, reduction = "umap", group.by = "isolation", cols=colIso)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")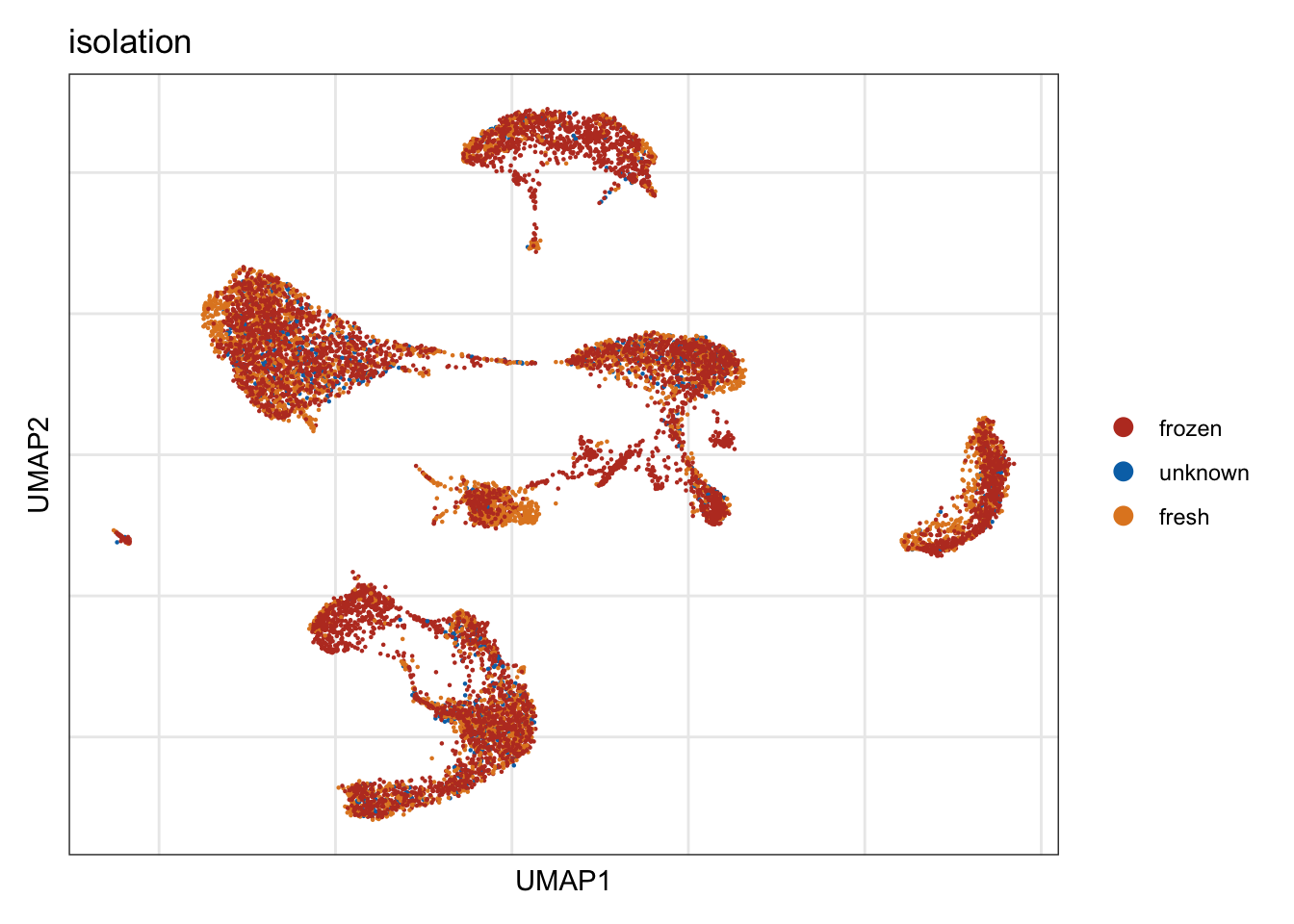
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
location
DimPlot(seurat, reduction = "umap", group.by = "location", cols=colLoc)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")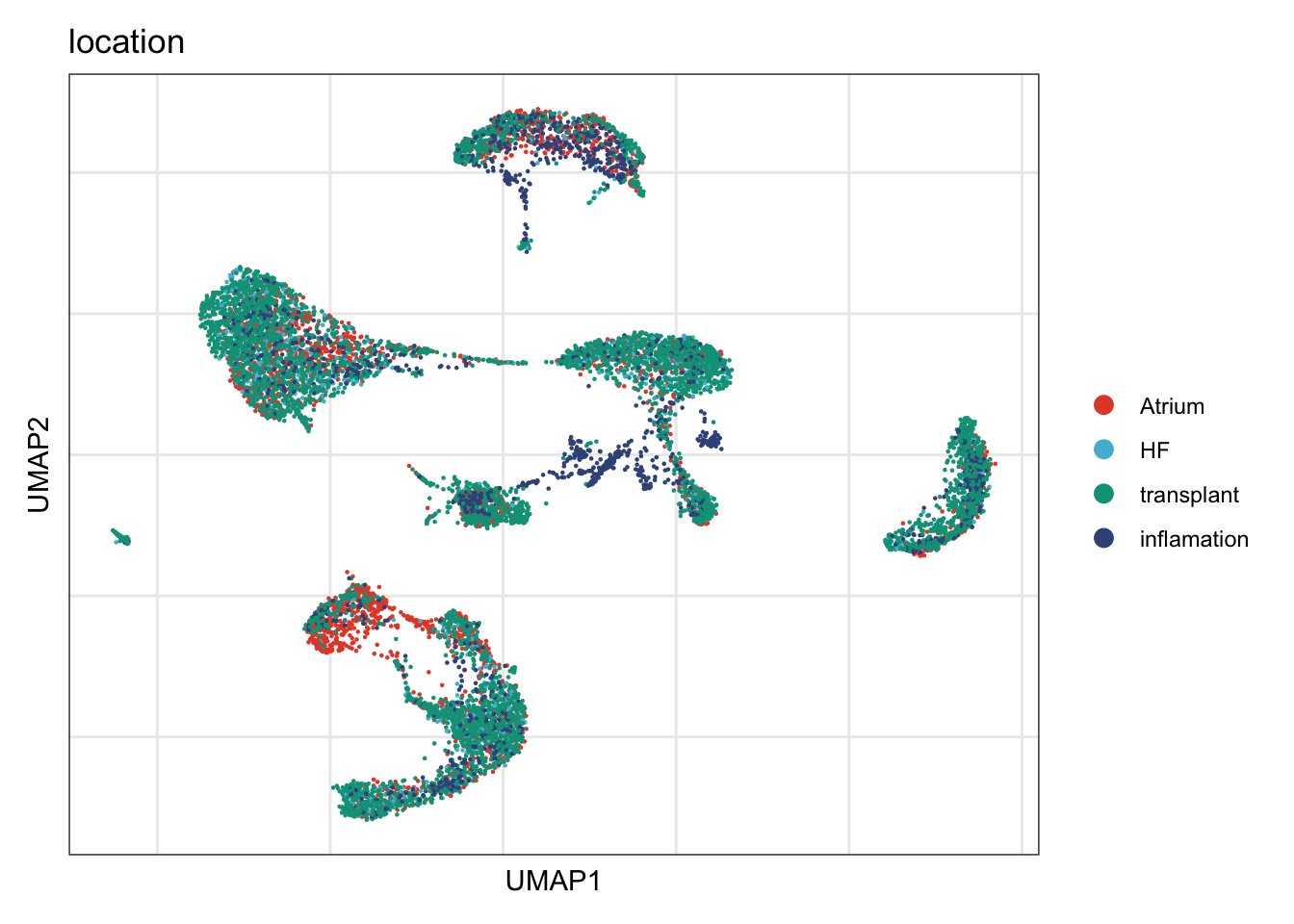
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
grp
DimPlot(seurat, reduction = "umap", group.by = "grp", cols=colGrp)+
theme_bw() +
theme(axis.text = element_blank(), axis.ticks = element_blank(),
panel.grid.minor = element_blank()) +
xlab("UMAP1") +
ylab("UMAP2")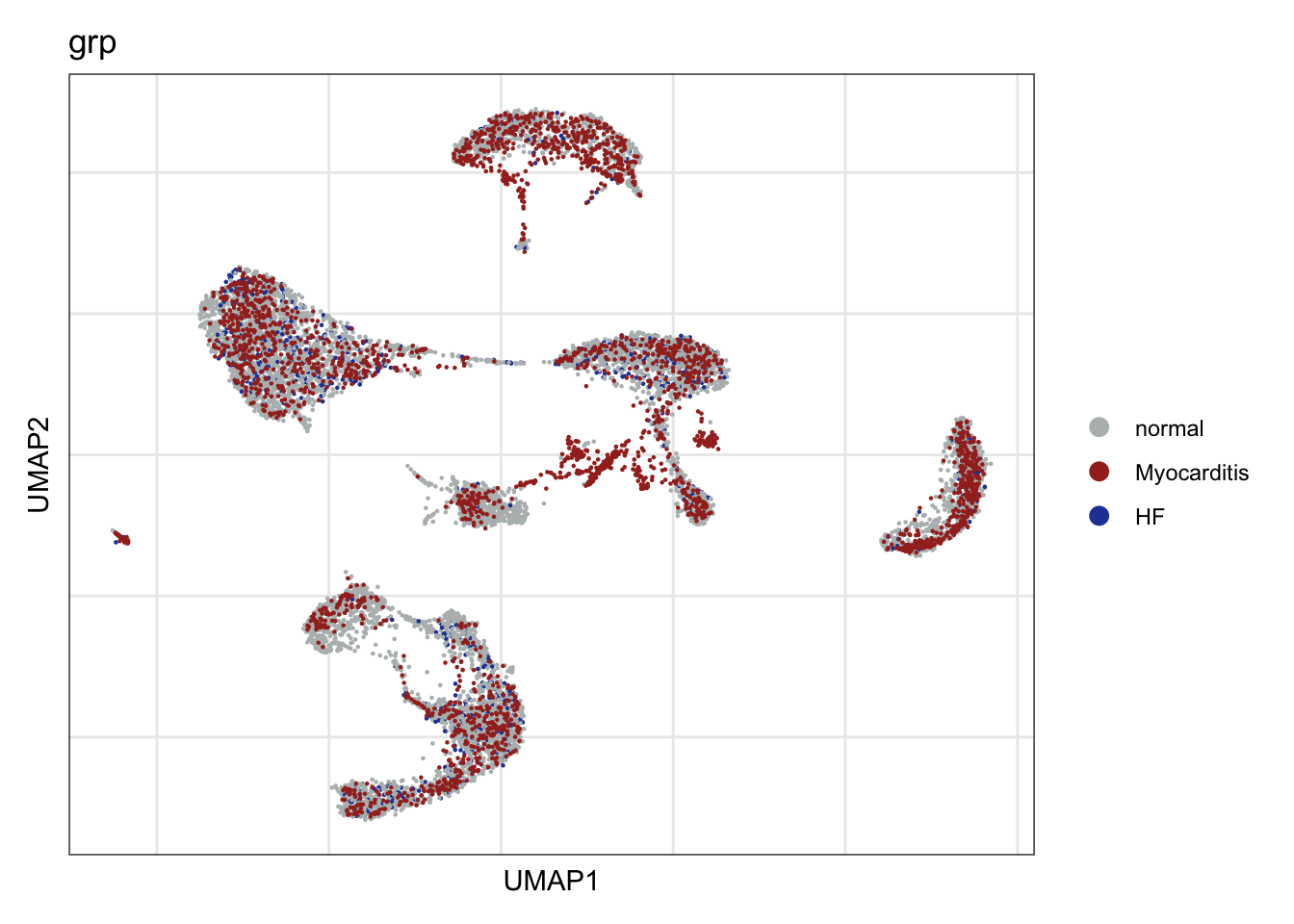
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
DimPlot(seurat, reduction = "umap", group.by = "grp", cols=colGrp,
pt.size=0.6)+
theme_void()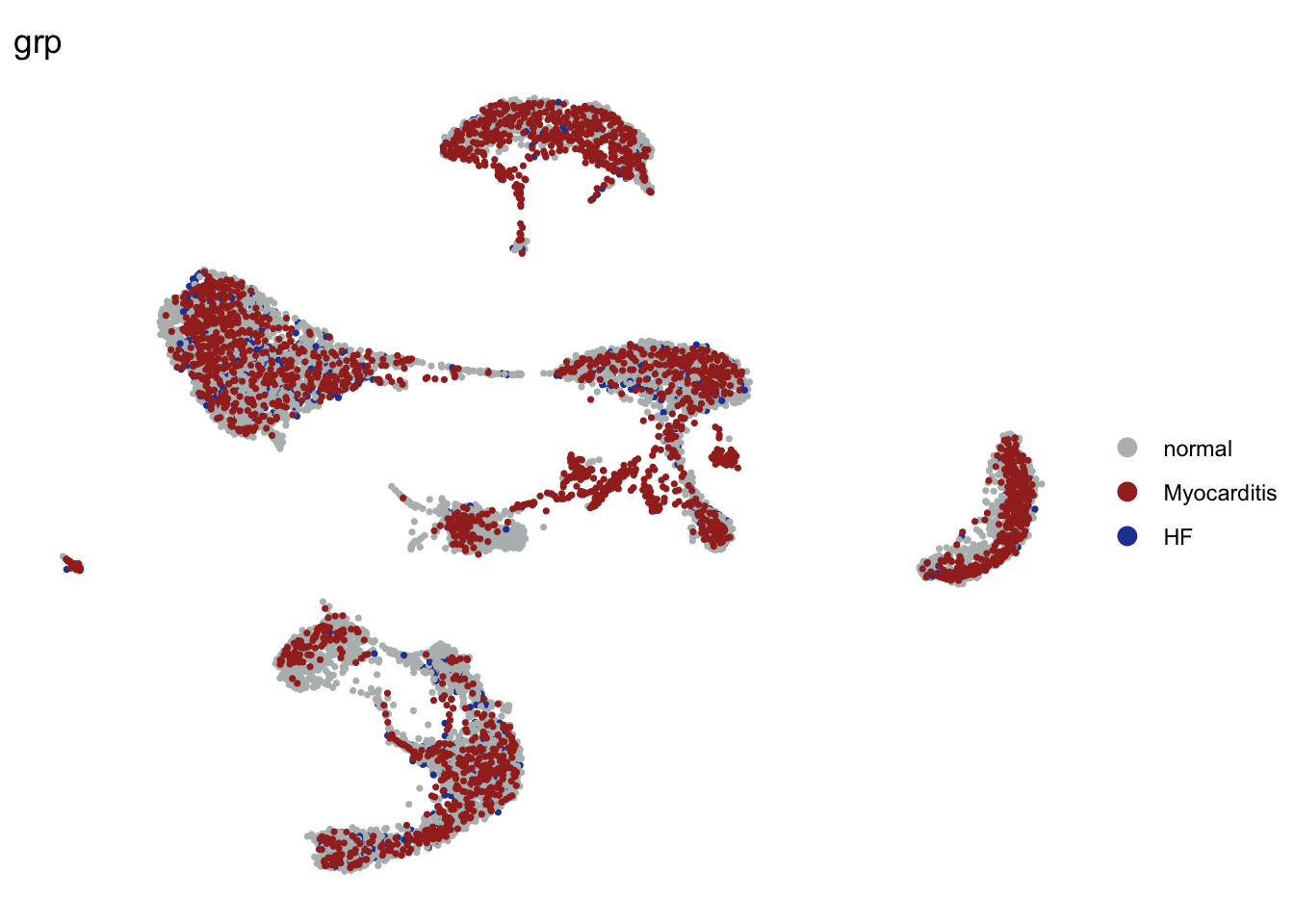
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
grp without HF
seuratSub <- subset(seurat, grp == "HF", invert=T)
DimPlot(seuratSub, reduction = "umap", group.by = "grp", cols=colGrp,
pt.size=0.6, order = "Myocarditis")+
theme_void()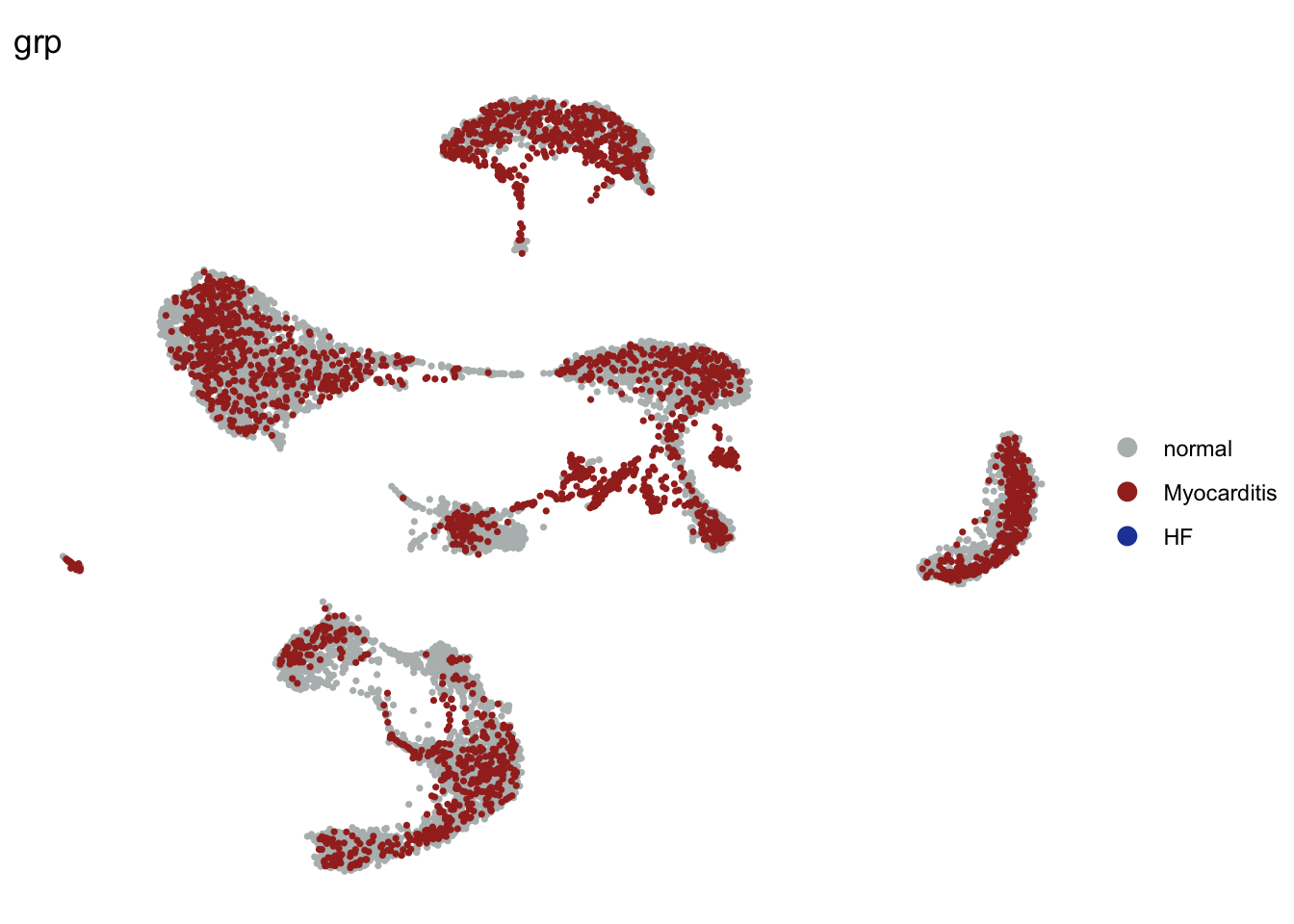
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
grp without M
seuratSub2 <- subset(seurat, grp == "Myocarditis", invert=T)
DimPlot(seuratSub2, reduction = "umap", group.by = "grp", cols=colGrp,
pt.size=0.6, order = "HF")+
theme_void()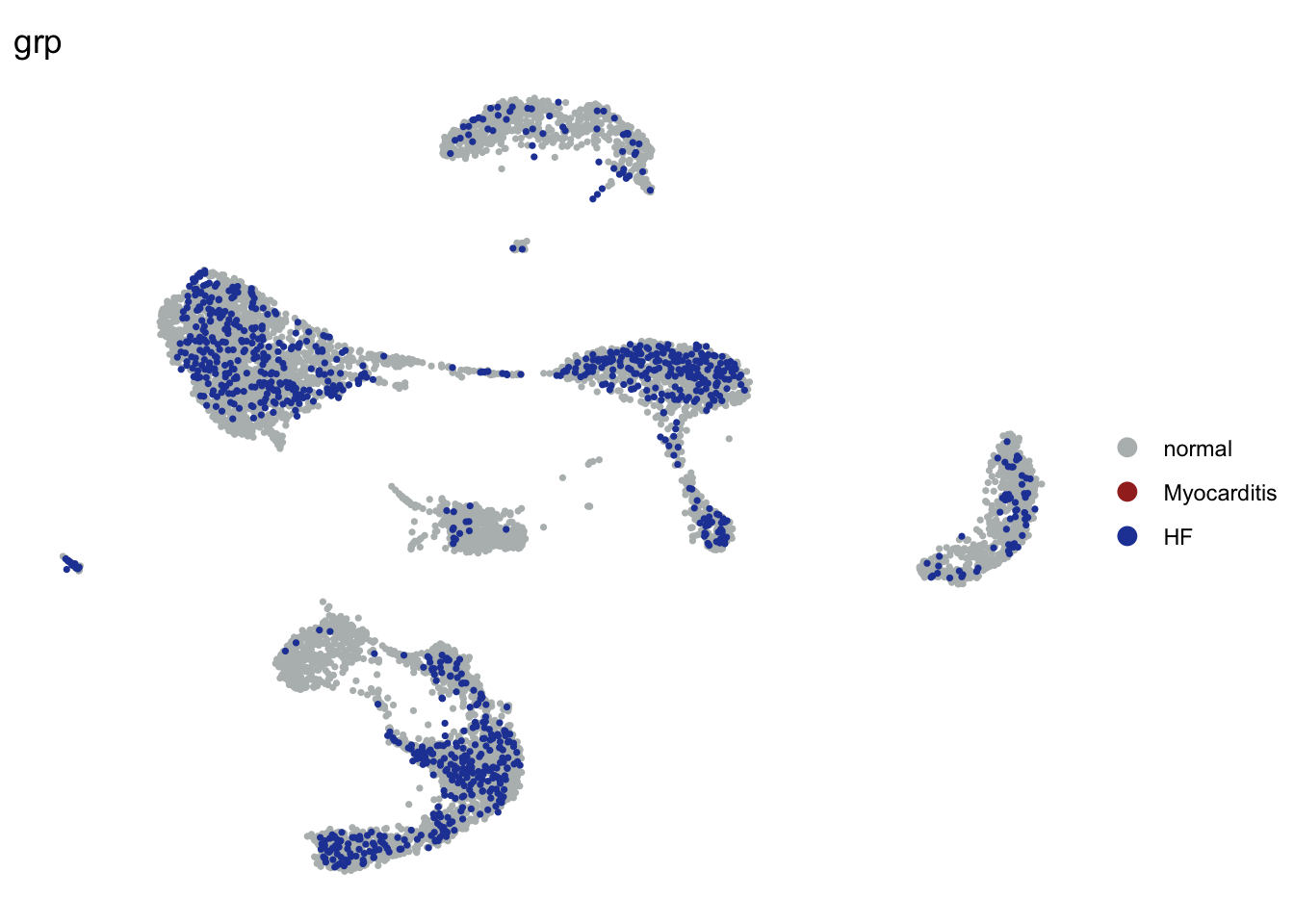
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
DE genes grp
Idents(seurat) <- seurat$grp
DEgenes <- FindAllMarkers(object = seurat, assay ="RNA",
only.pos = TRUE, min.pct = 0.25,
logfc.threshold = 0.25,
test.use = "wilcox")top 20 marker genes per grp
cluster <- levels(seurat)
selGenesAll <- DEgenes %>% group_by(cluster) %>%
top_n(-20, p_val_adj) %>%
top_n(20, avg_log2FC)
selGenesAll <- selGenesAll %>% mutate(geneIDval=gsub("^.*\\.", "", gene)) %>% filter(nchar(geneIDval)>1)
Idents(seurat) <- seurat$grp
pOut <- avgHeatmap(seurat = seurat, selGenes = selGenesAll,
colVecIdent = colGrp,
ordVec=levels(seurat),
gapVecR=NULL, gapVecC=NULL,cc=FALSE,
cr=T, condCol=F)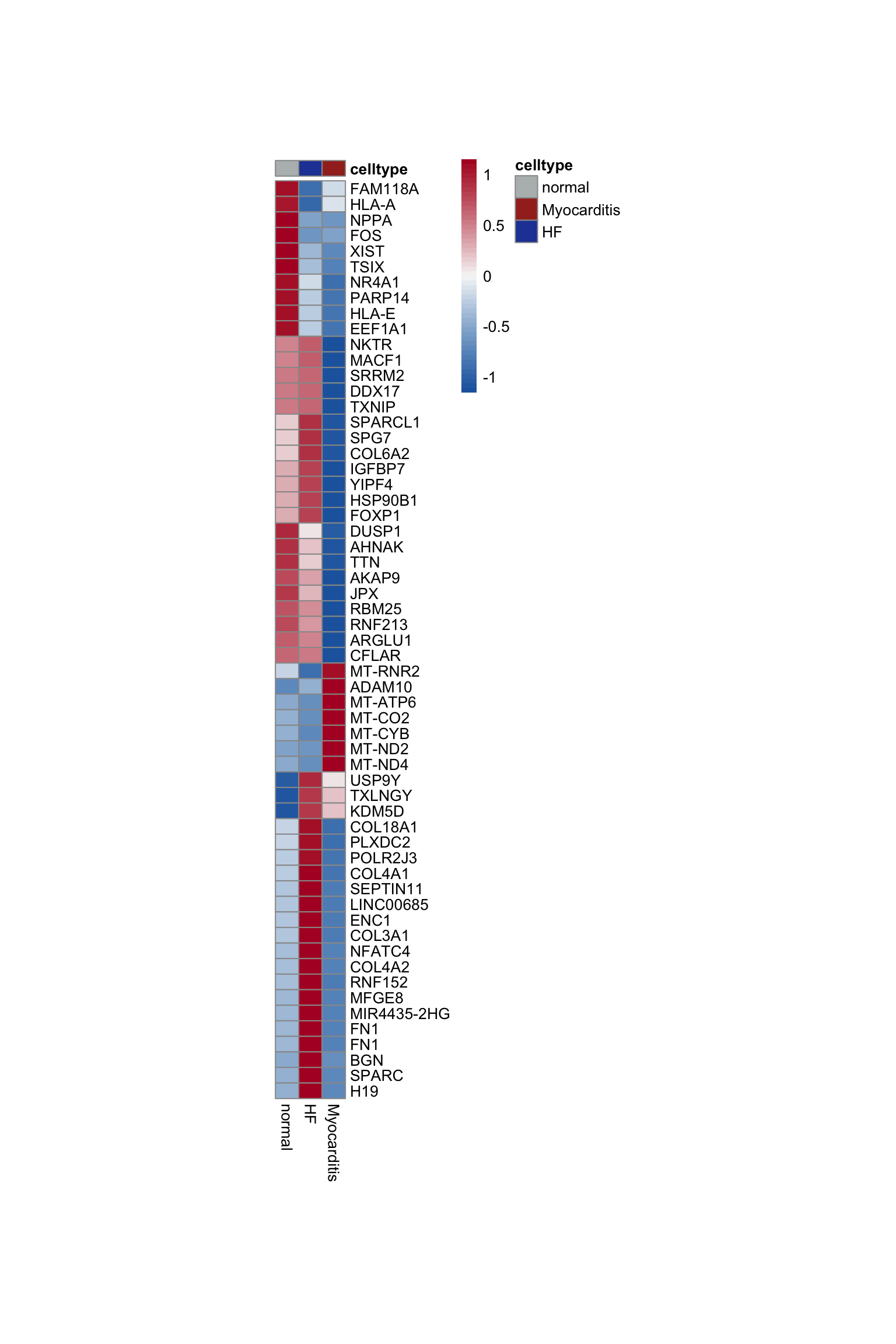
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
Idents(seurat) <- seurat$ID
pOut <- avgHeatmap(seurat = seurat, selGenes = selGenesAll,
colVecIdent = colBatch,
ordVec=levels(seurat),
gapVecR=NULL, gapVecC=NULL,cc=FALSE,
cr=T, condCol=F)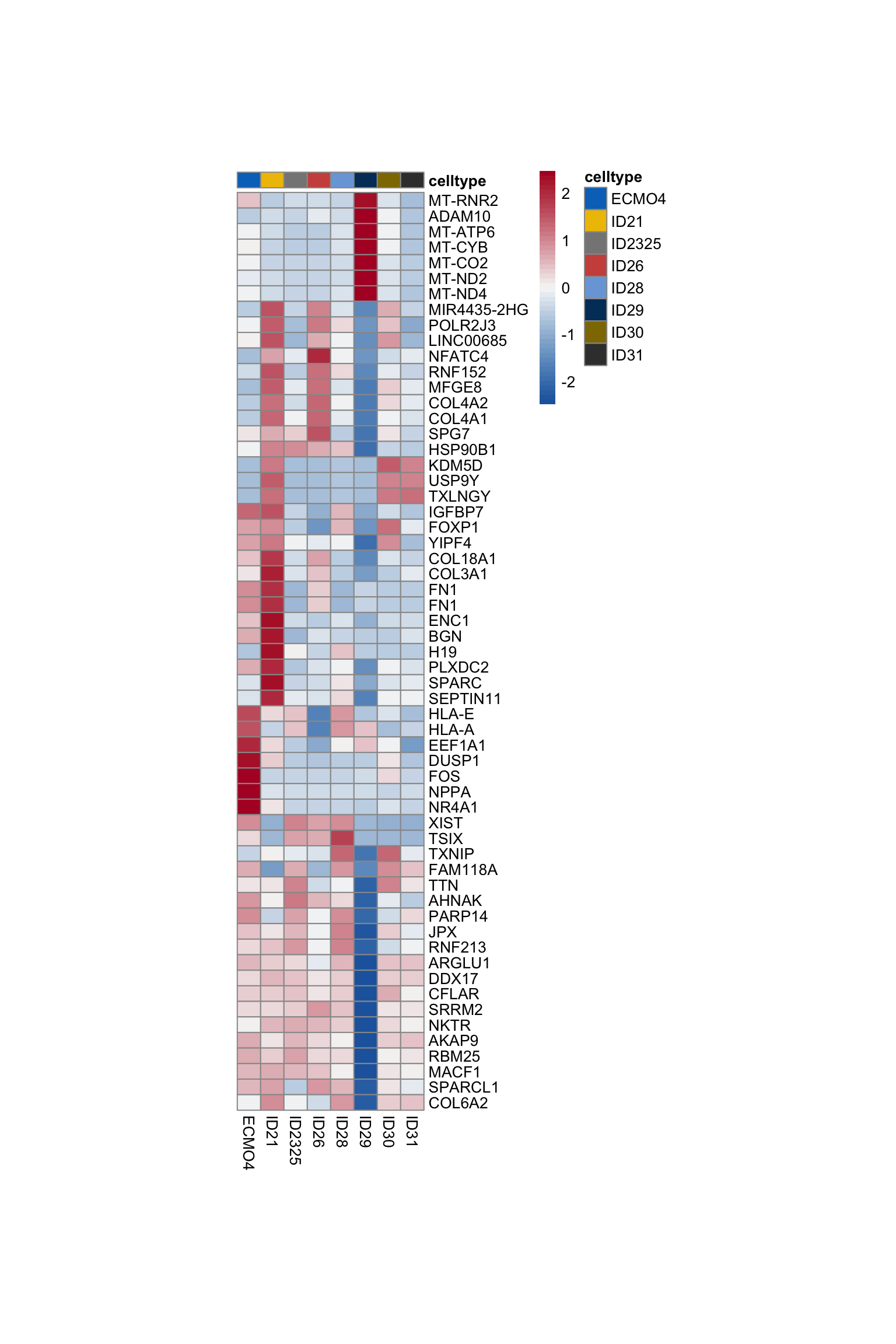
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
cnt Tab
table(seurat$grp)
HF Myocarditis normal
1064 2670 7547 table(seurat$ID)
ECMO4 ID21 ID2325 ID26 ID28 ID29 ID30 ID31
3162 826 3131 238 1254 1242 236 1192 table(seurat$ID, seurat$grp)
HF Myocarditis normal
ECMO4 0 0 3162
ID21 826 0 0
ID2325 0 0 3131
ID26 238 0 0
ID28 0 0 1254
ID29 0 1242 0
ID30 0 236 0
ID31 0 1192 0signature cut 1.5
split by grp
signDat <- read_delim(file = paste0(basedir,
"/data/SelSignaturesTreat.txt"),
delim = "\t")
genes <- data.frame(geneID=rownames(seurat)) %>%
mutate(gene=gsub("^.*\\.", "", geneID))
signDat <- signDat %>% left_join(.,genes, by="gene")
allSign <- unique(signDat$signature)
DefaultAssay(object = seurat) <- "integrated"
sce2 <- as.SingleCellExperiment(seurat)
DefaultAssay(object = seurat) <- "RNA"
sce <- as.SingleCellExperiment(seurat)
reducedDims(sce) <- list(PCA=reducedDim(sce2, "PCA"),
TSNE=reducedDim(sce2, "TSNE"),
UMAP=reducedDim(sce2, "UMAP"))
treatGrps <- unique(sce$grp)
cutOff <- 1.5
pal = viridis(100)
sc <- scale_colour_gradientn(colours = pal, limits=c(0, cutOff))
lapply(unique(signDat$signature), function(sign){
signGenes <- signDat %>% dplyr::filter(signature == sign)
sceSub <- sce[which(rownames(sce) %in% signGenes$geneID),]
cntMat <- rowSums(t(as.matrix(sceSub@assays@data$logcounts)))/nrow(signGenes)
sceSub$sign <- cntMat
sceSub$sign[which(sceSub$sign > cutOff)] <- cutOff
sceSub$sign[which(sceSub$sign < 0)] <- 0
lapply(treatGrps, function(treat){
sceSubT <- sceSub[, which(sceSub$grp == treat)]
p <- visGroup_adapt(sceSubT, 'sign', dim_red = 'UMAP') +
sc +
guides(colour = guide_colourbar(title = '')) +
ggtitle(paste0(sign, ' signature - ', treat)) +
theme_classic() +
theme(axis.text = element_blank(),
axis.ticks = element_blank()) +
labs(x='Dimension 1', y='Dimension 2')
p
})
})[[1]]
[[1]][[1]]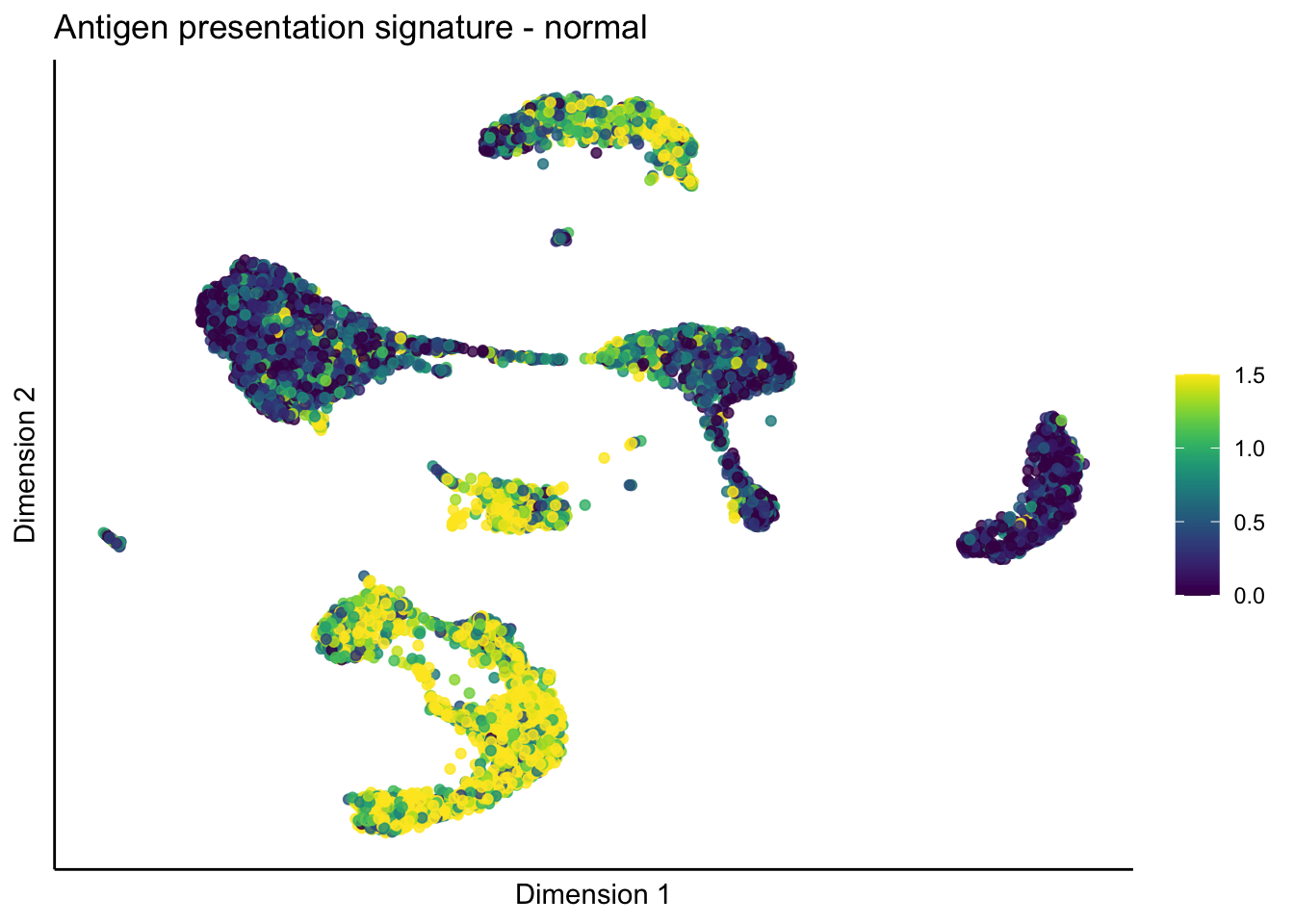
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[1]][[2]]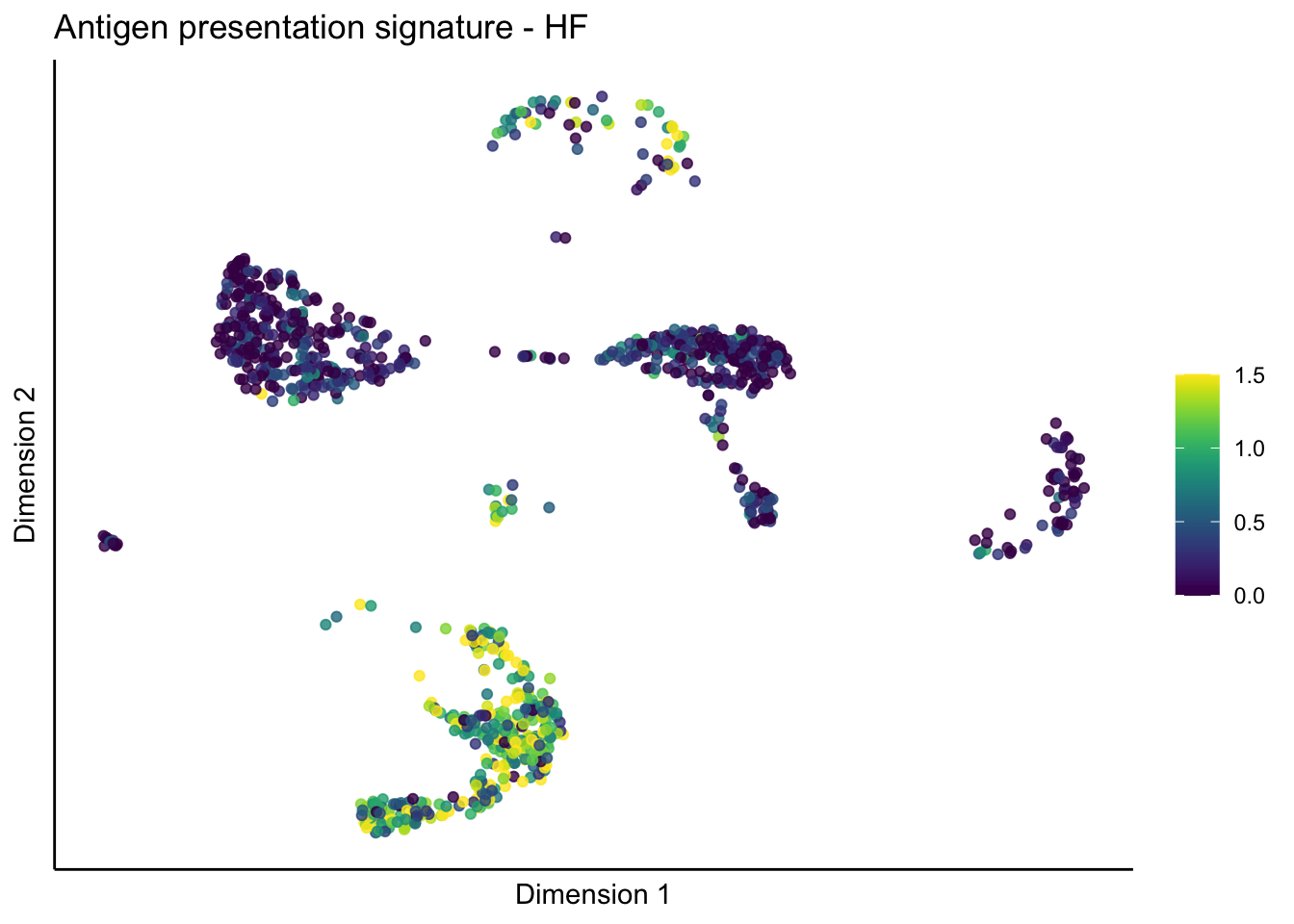
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[1]][[3]]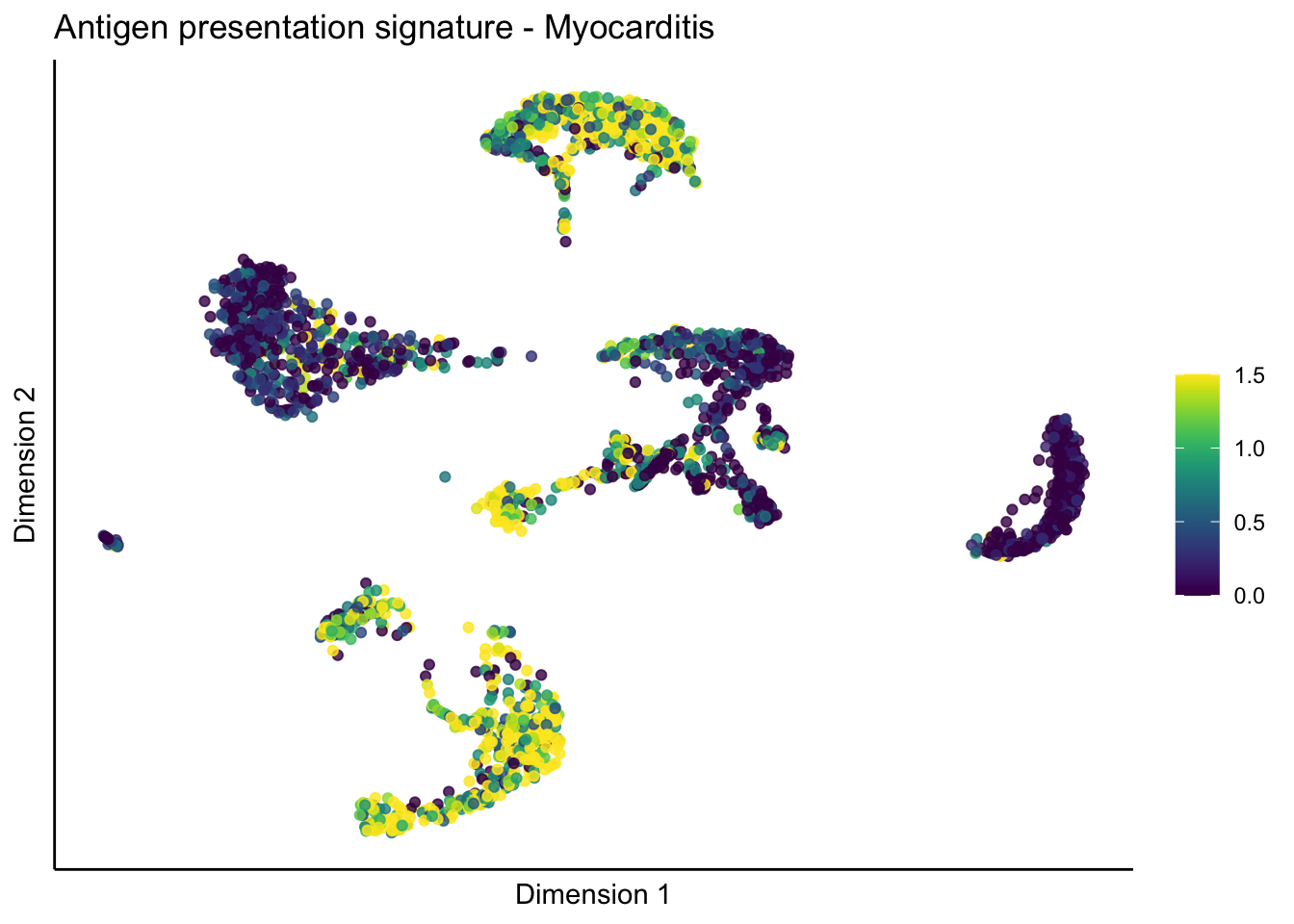
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[2]]
[[2]][[1]]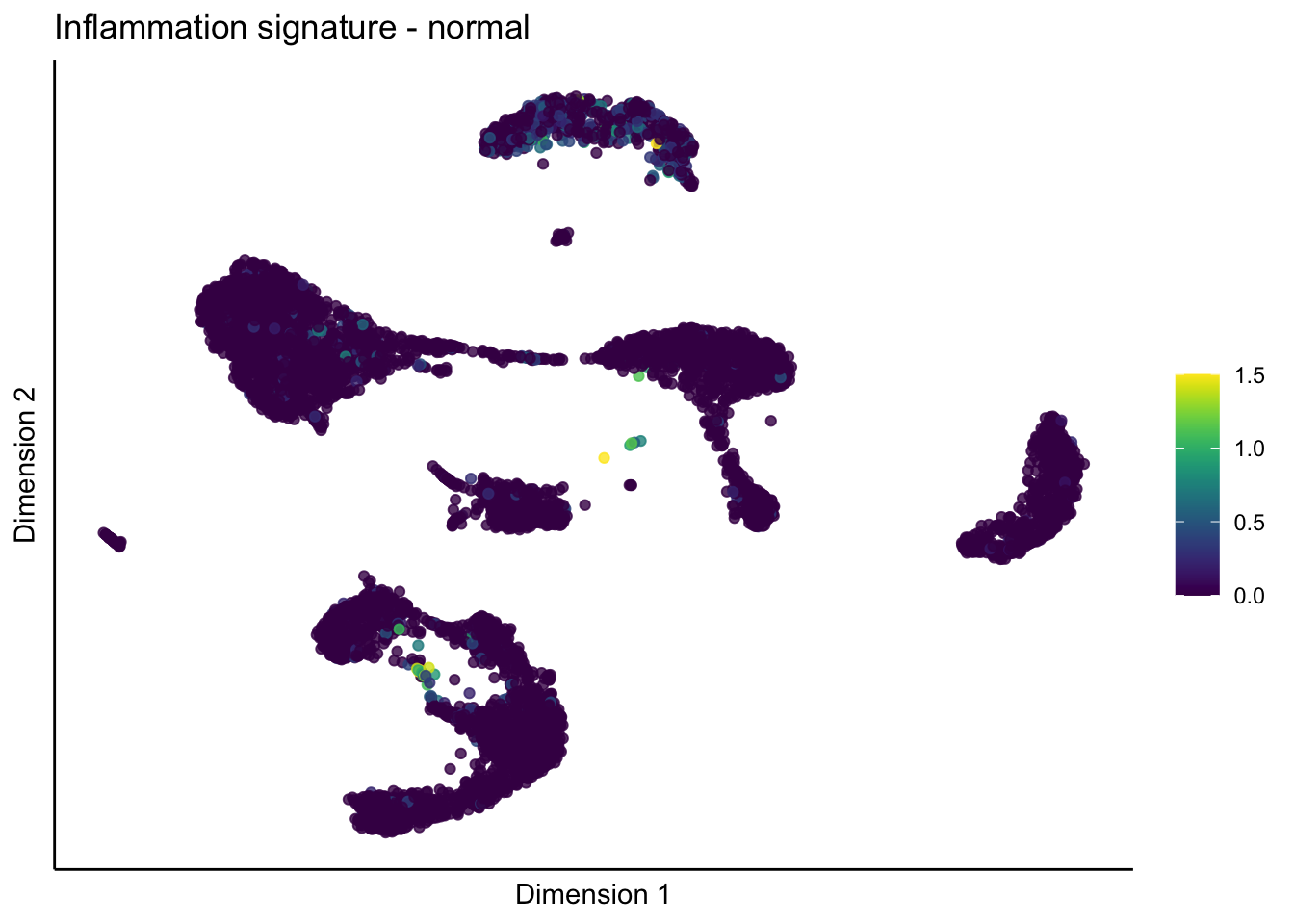
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[2]][[2]]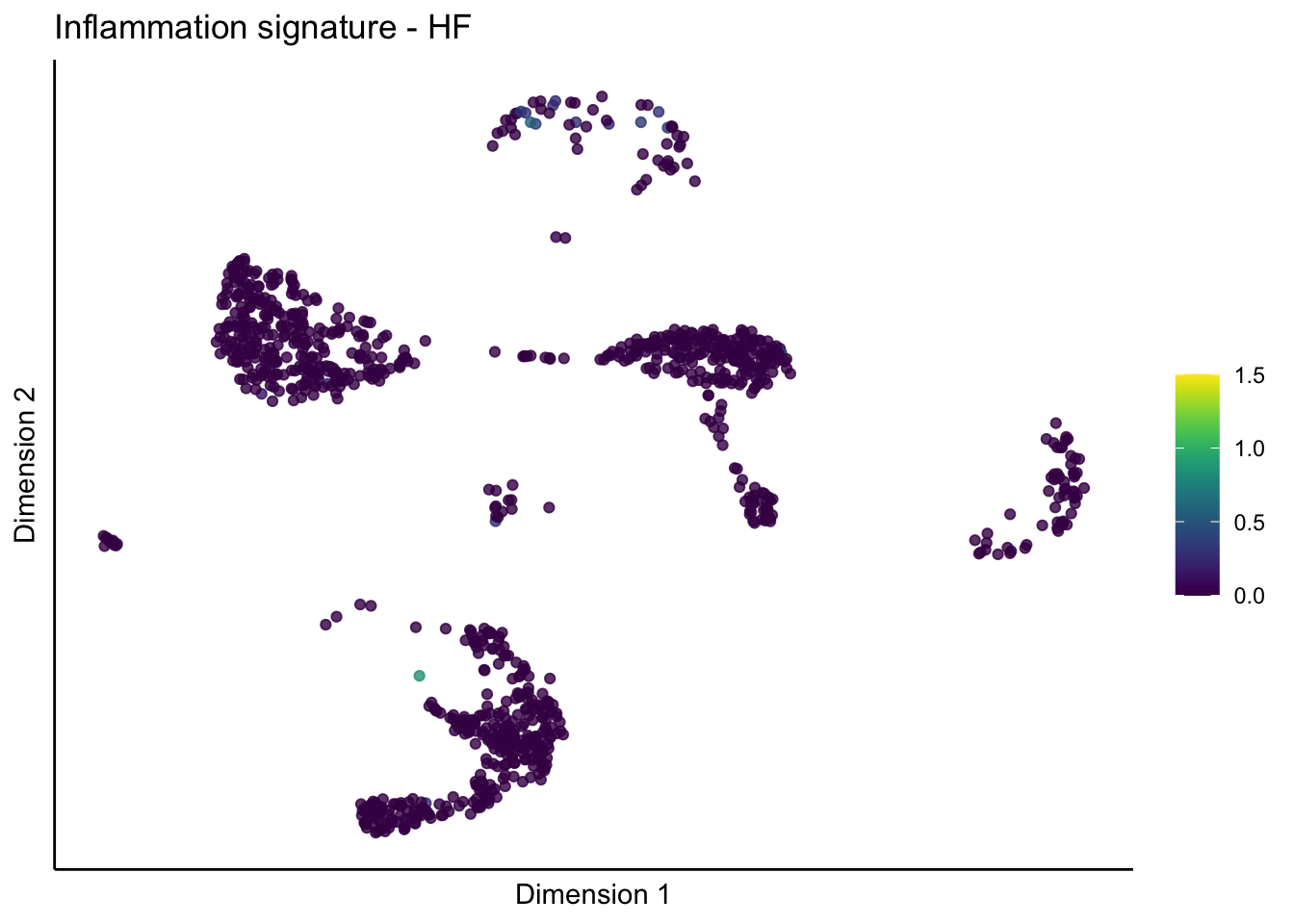
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[2]][[3]]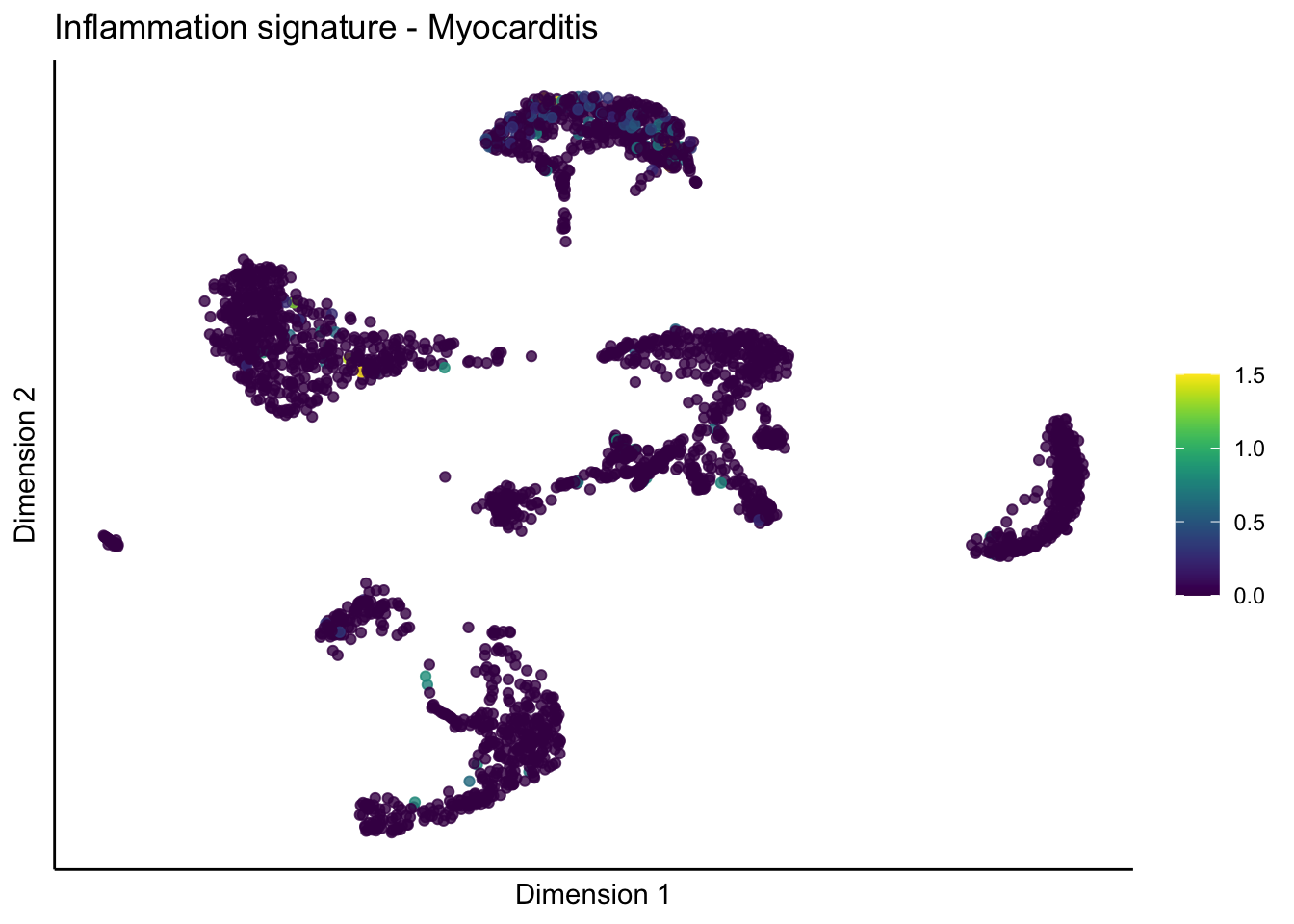
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[3]]
[[3]][[1]]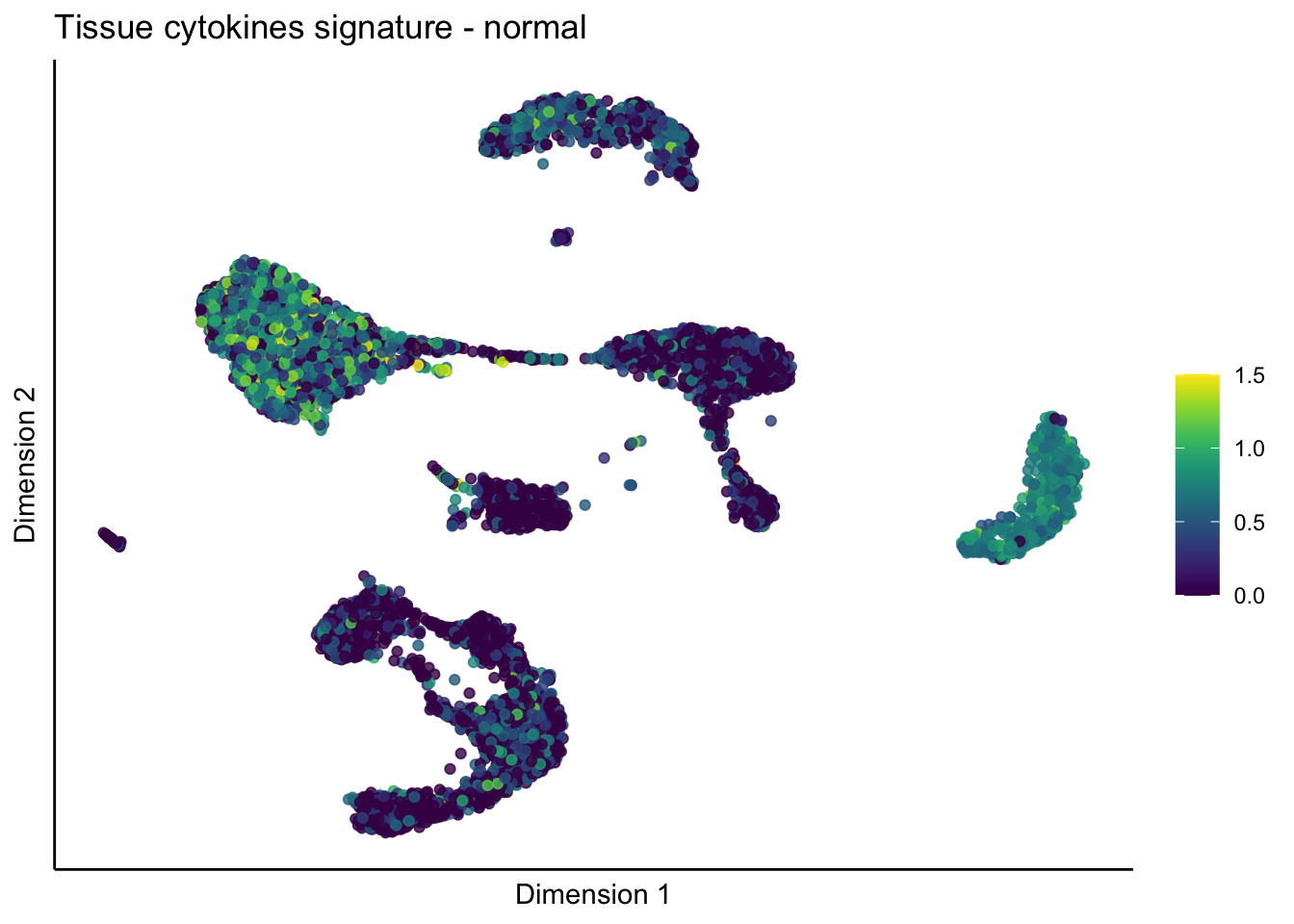
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[3]][[2]]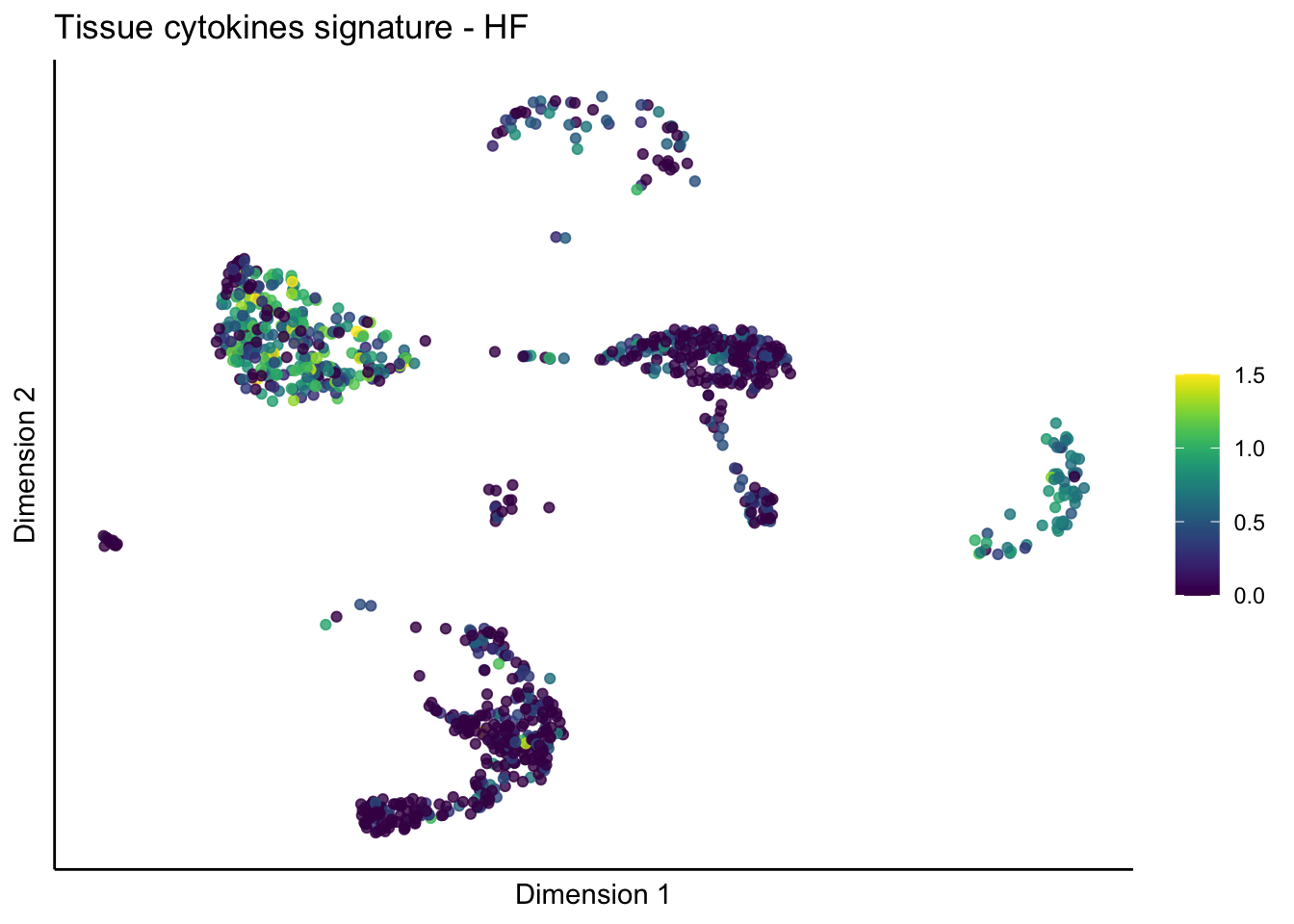
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[3]][[3]]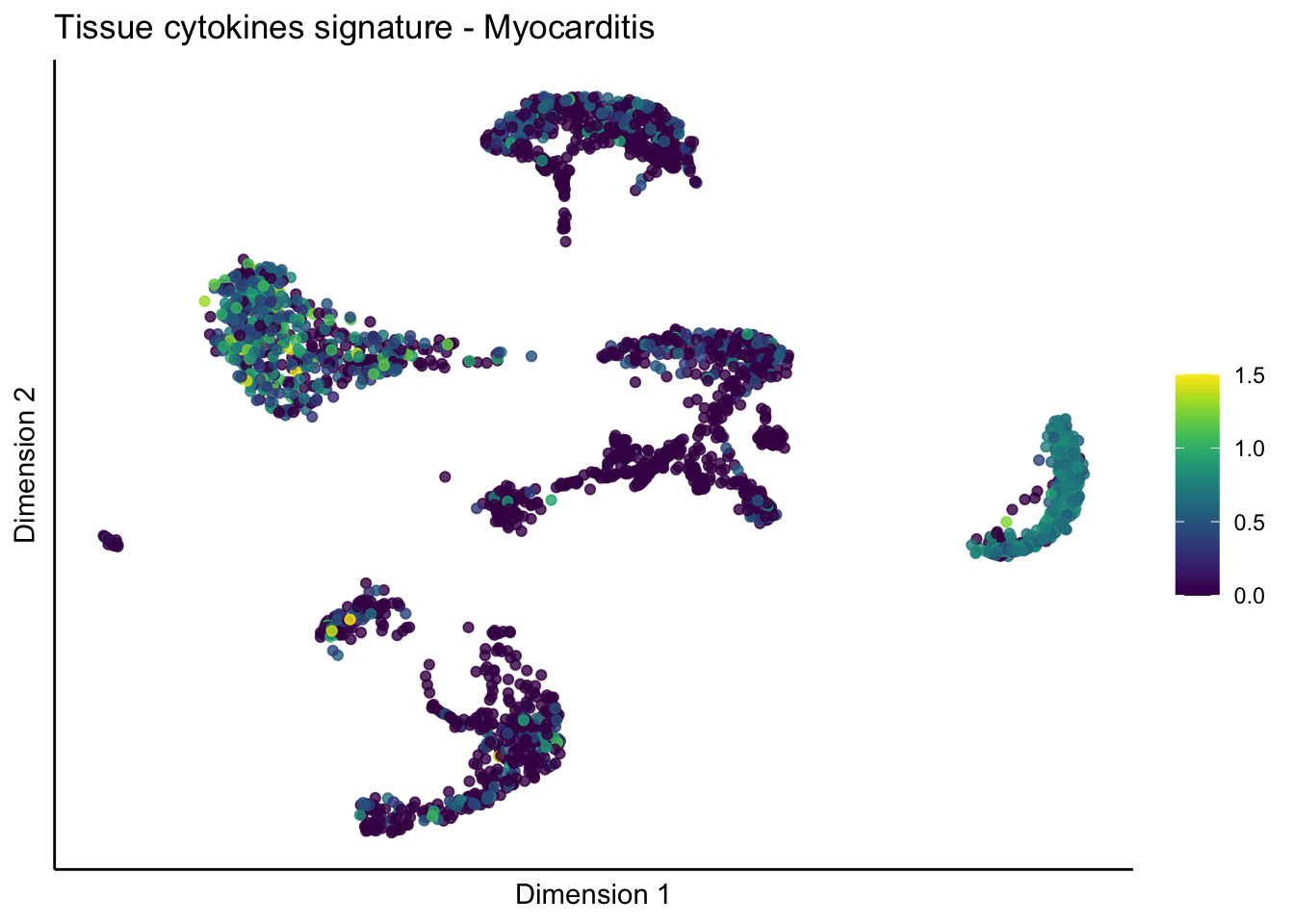
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[4]]
[[4]][[1]]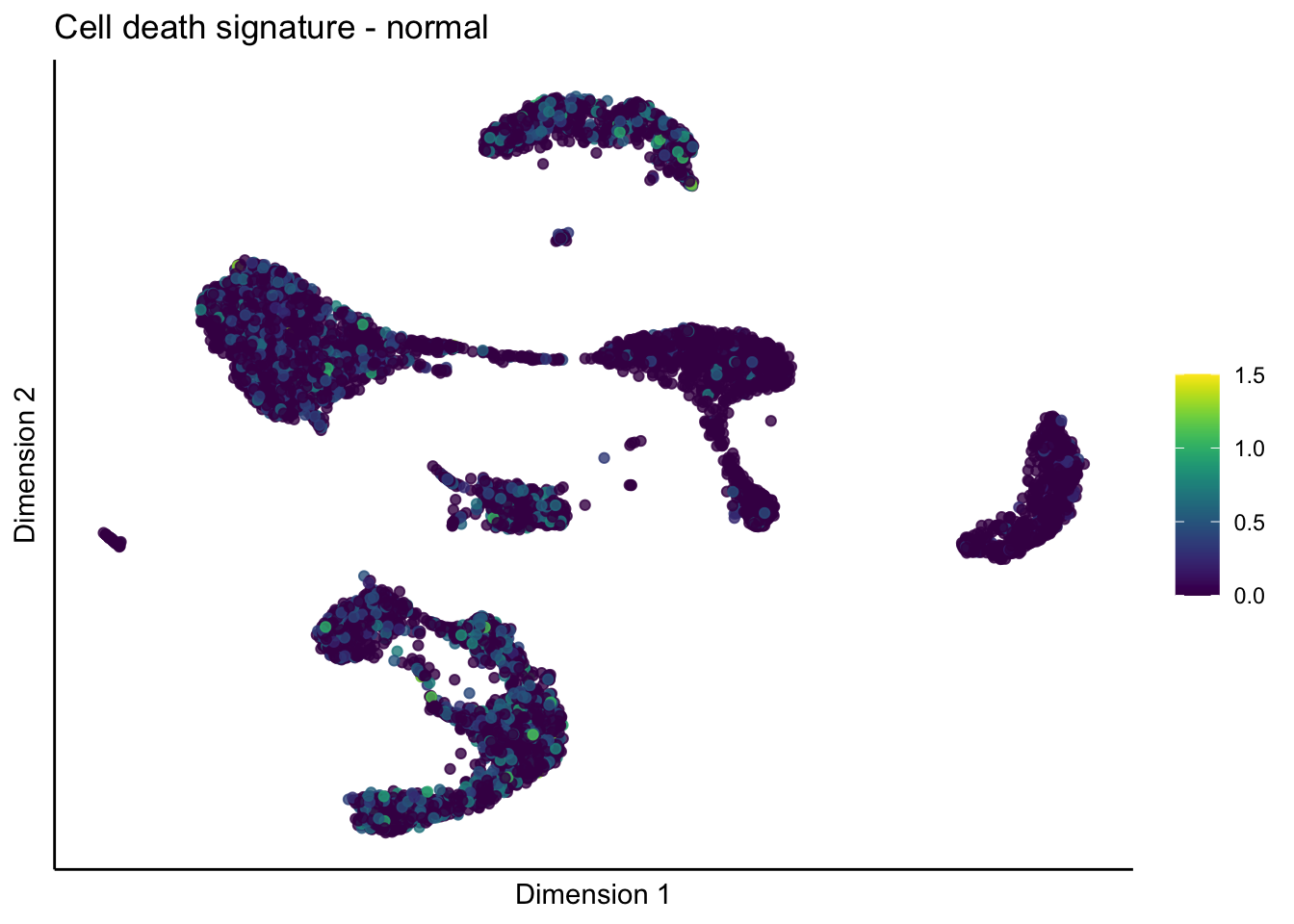
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[4]][[2]]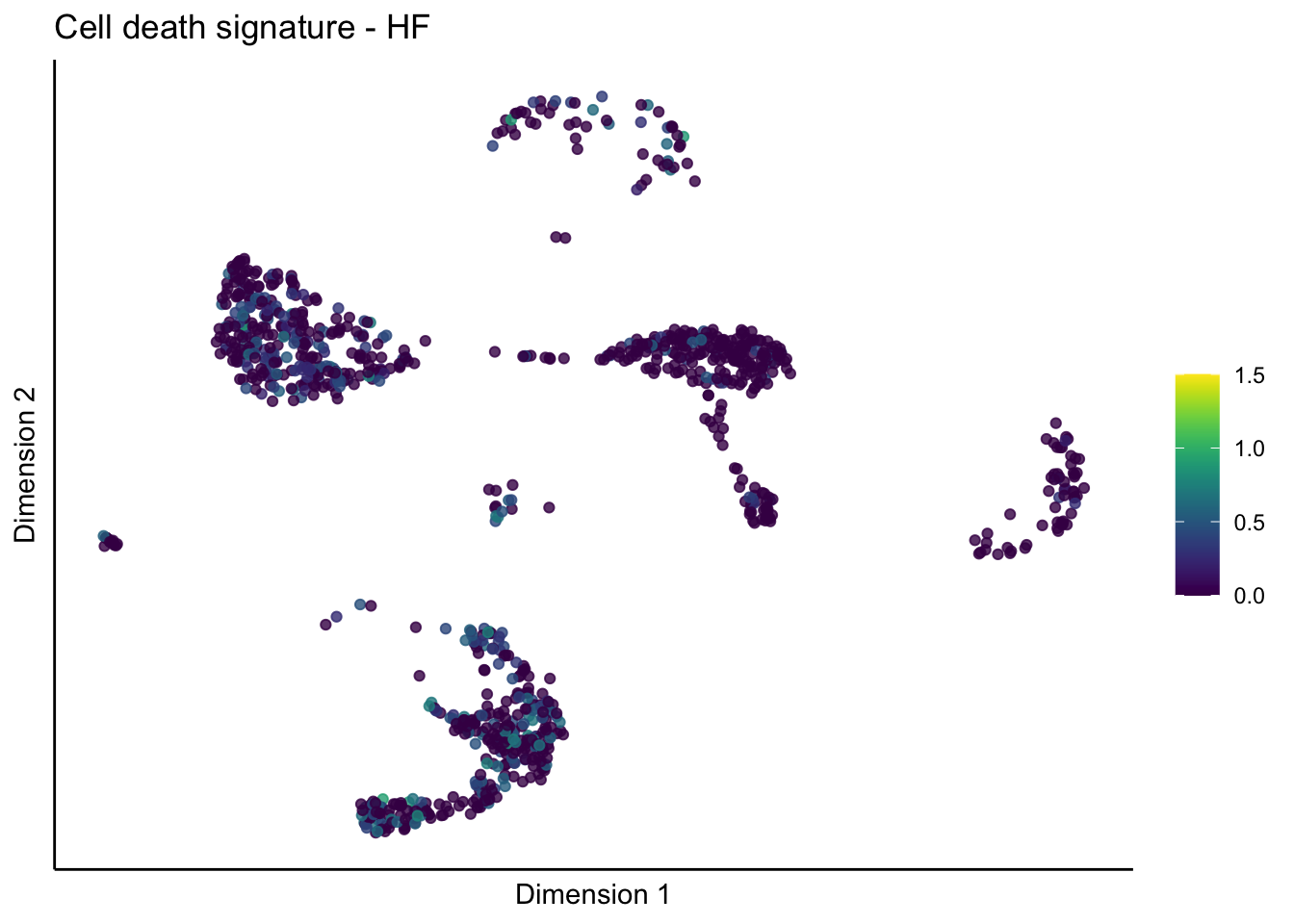
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[4]][[3]]
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[5]]
[[5]][[1]]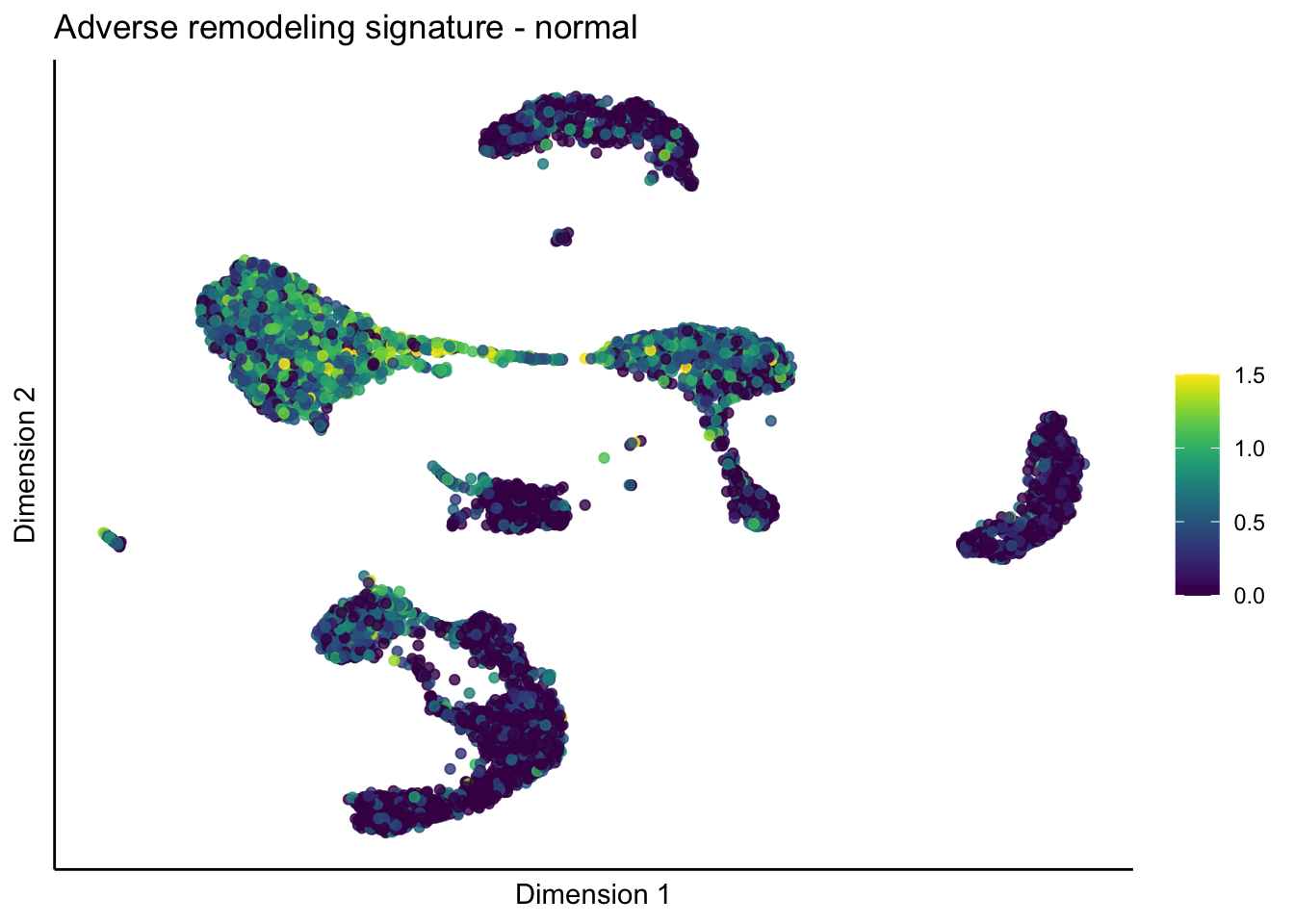
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[5]][[2]]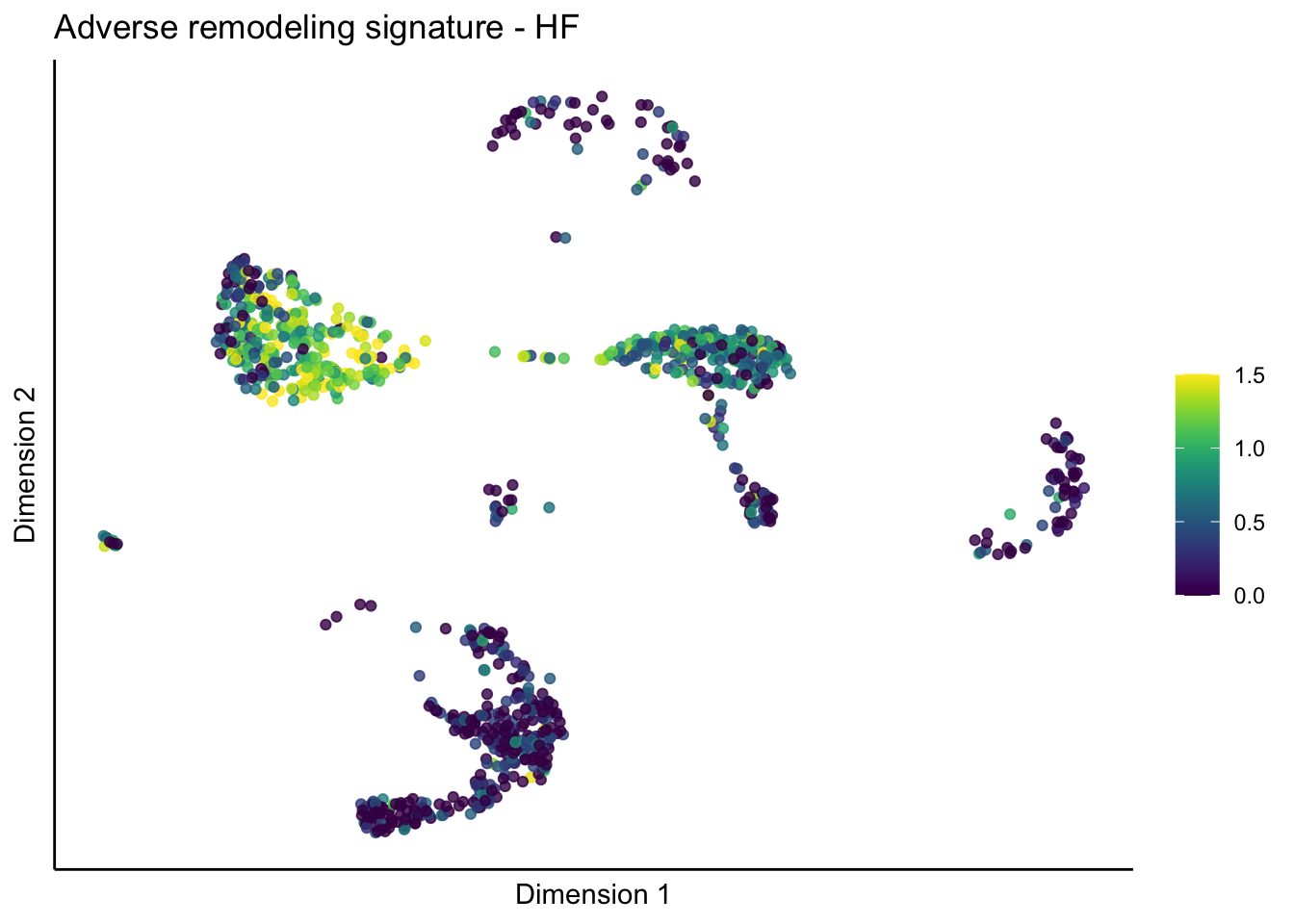
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[5]][[3]]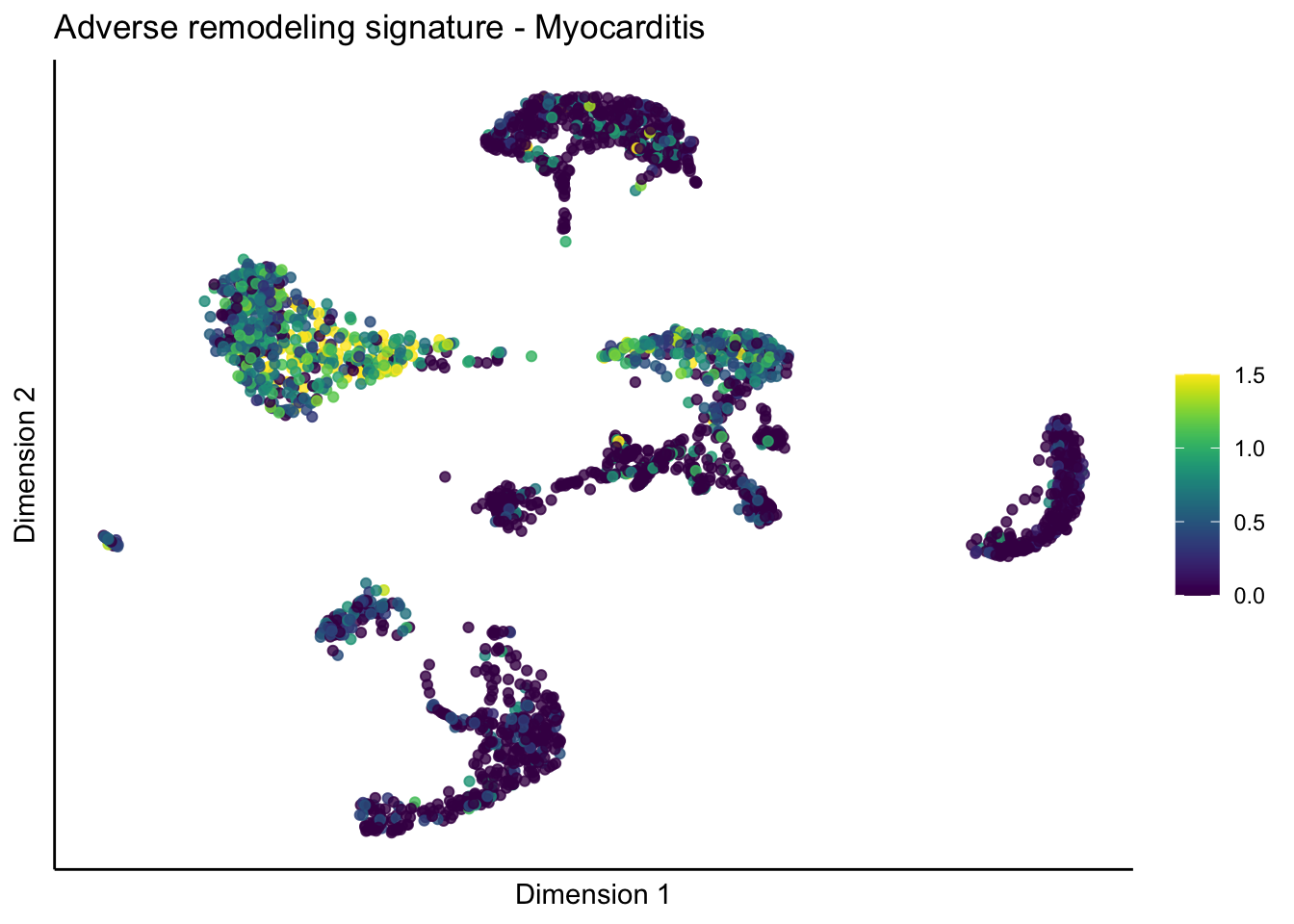
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
across all
#sce <- as.SingleCellExperiment(seurat)
cutOff <- 1.5
pal = viridis(100)
sc <- scale_colour_gradientn(colours = pal, limits=c(0, cutOff))
lapply(unique(signDat$signature), function(sign){
signGenes <- signDat %>% dplyr::filter(signature == sign)
sceSub <- sce[which(rownames(sce) %in% signGenes$geneID),]
cntMat <- rowSums(t(as.matrix(sceSub@assays@data$logcounts)))/nrow(signGenes)
sceSub$sign <- cntMat
sceSub$sign[which(sceSub$sign > cutOff)] <- cutOff
sceSub$sign[which(sceSub$sign < 0)] <- 0
p <- visGroup_adapt(sceSub, 'sign', dim_red = 'UMAP') +
sc +
guides(colour = guide_colourbar(title = '')) +
ggtitle(paste0(sign, ' signature - across all')) +
theme_classic() +
theme(axis.text = element_blank(),
axis.ticks = element_blank()) +
labs(x='Dimension 1', y='Dimension 2')
p
})[[1]]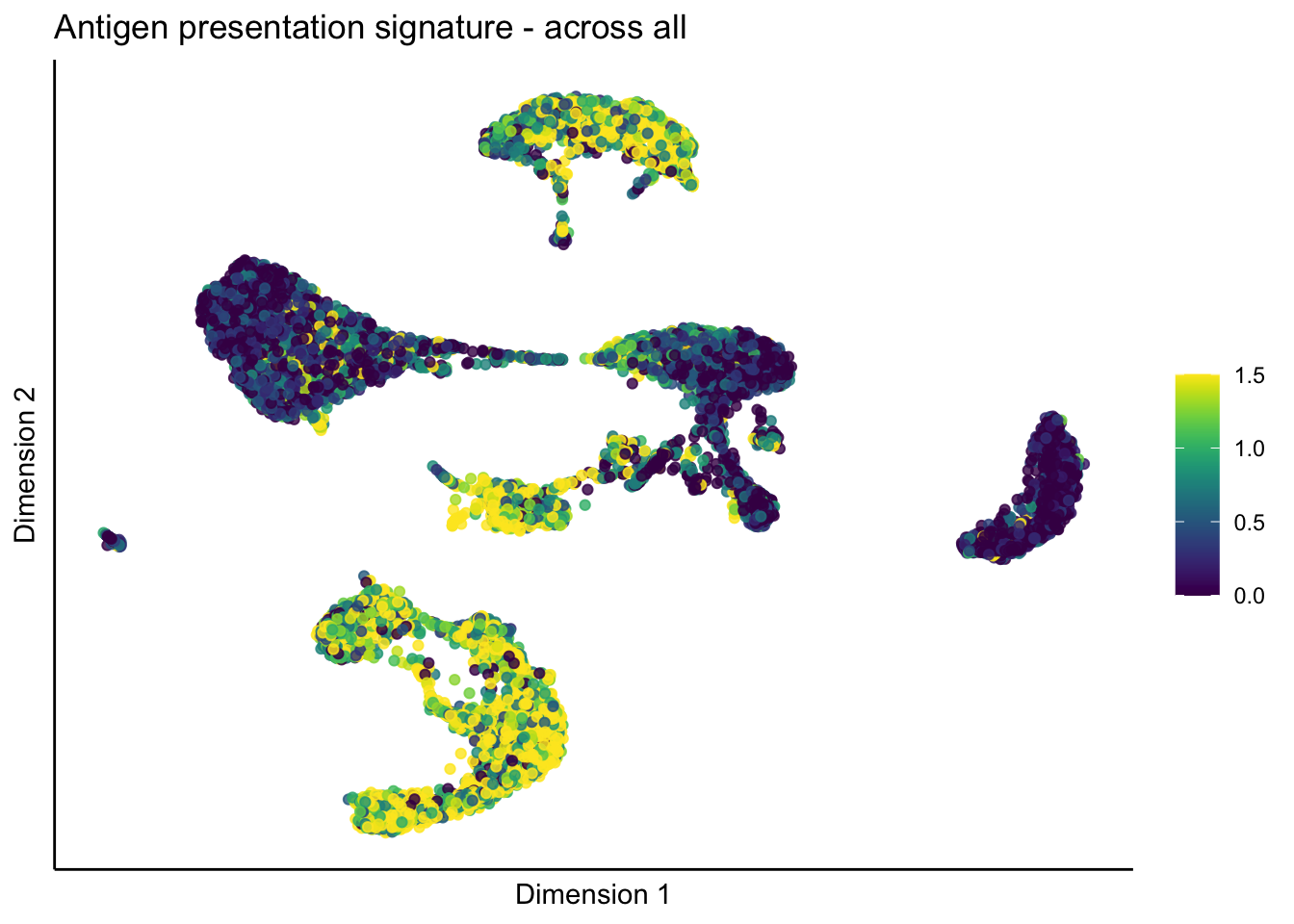
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[2]]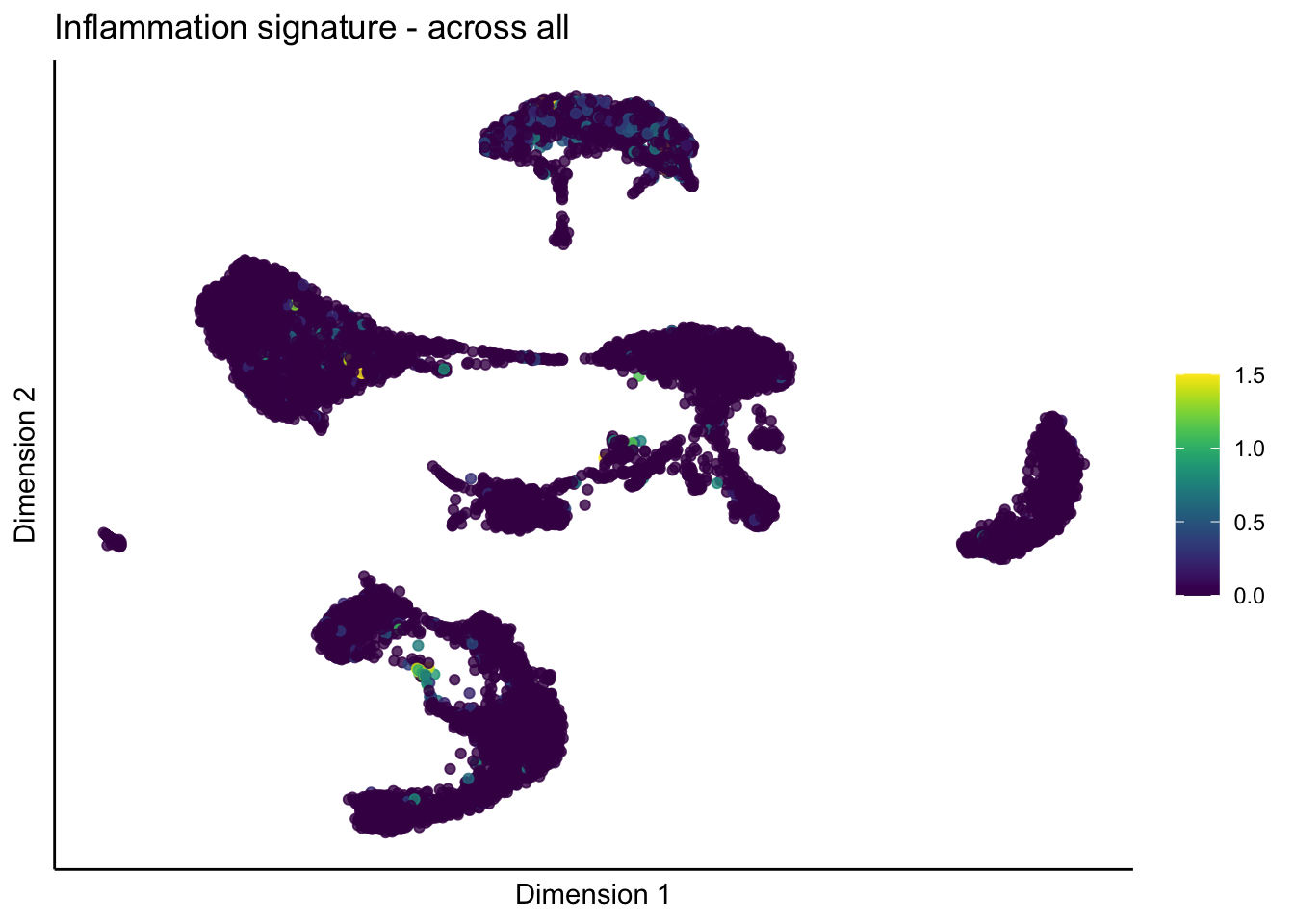
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[3]]
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[4]]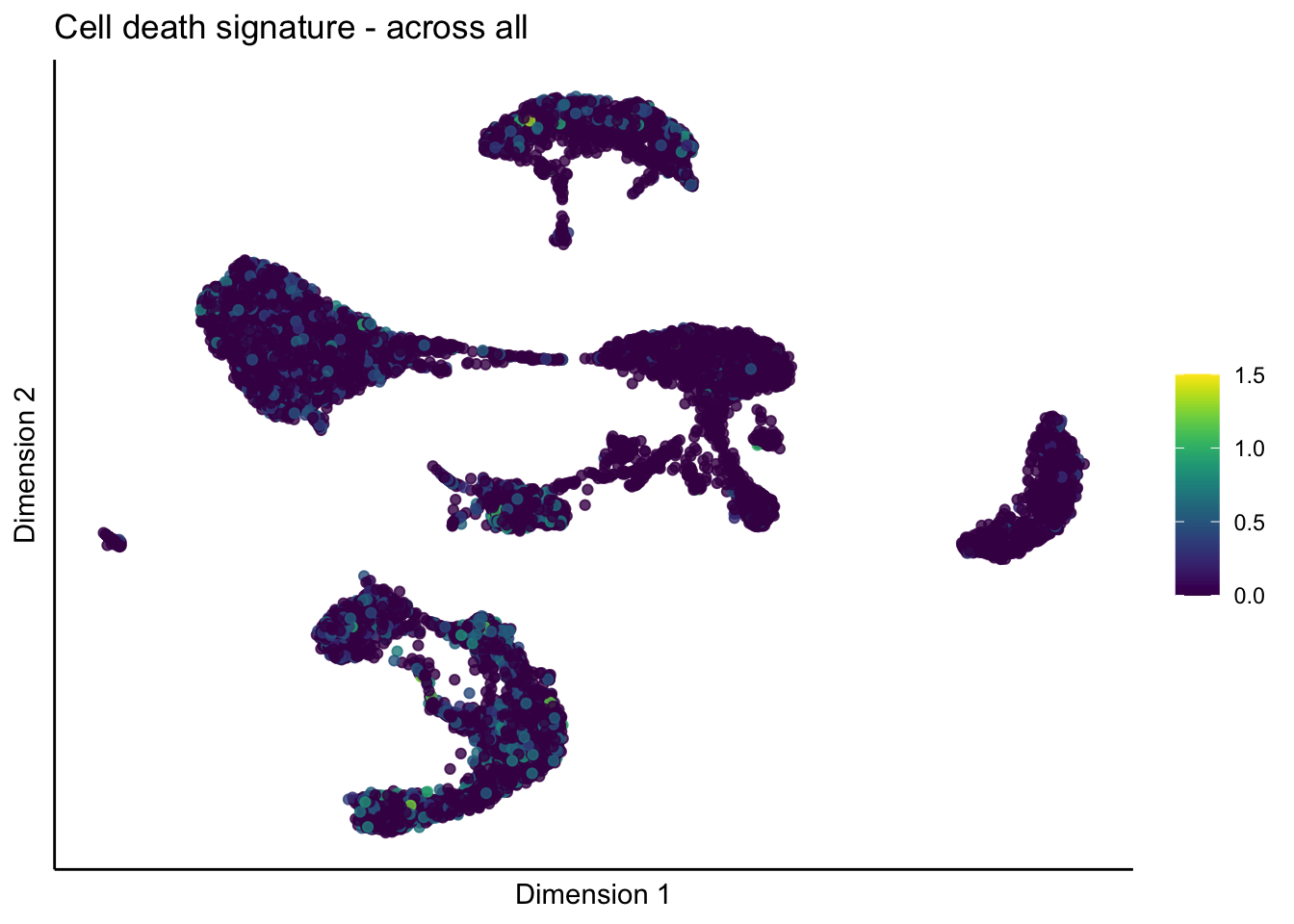
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
[[5]]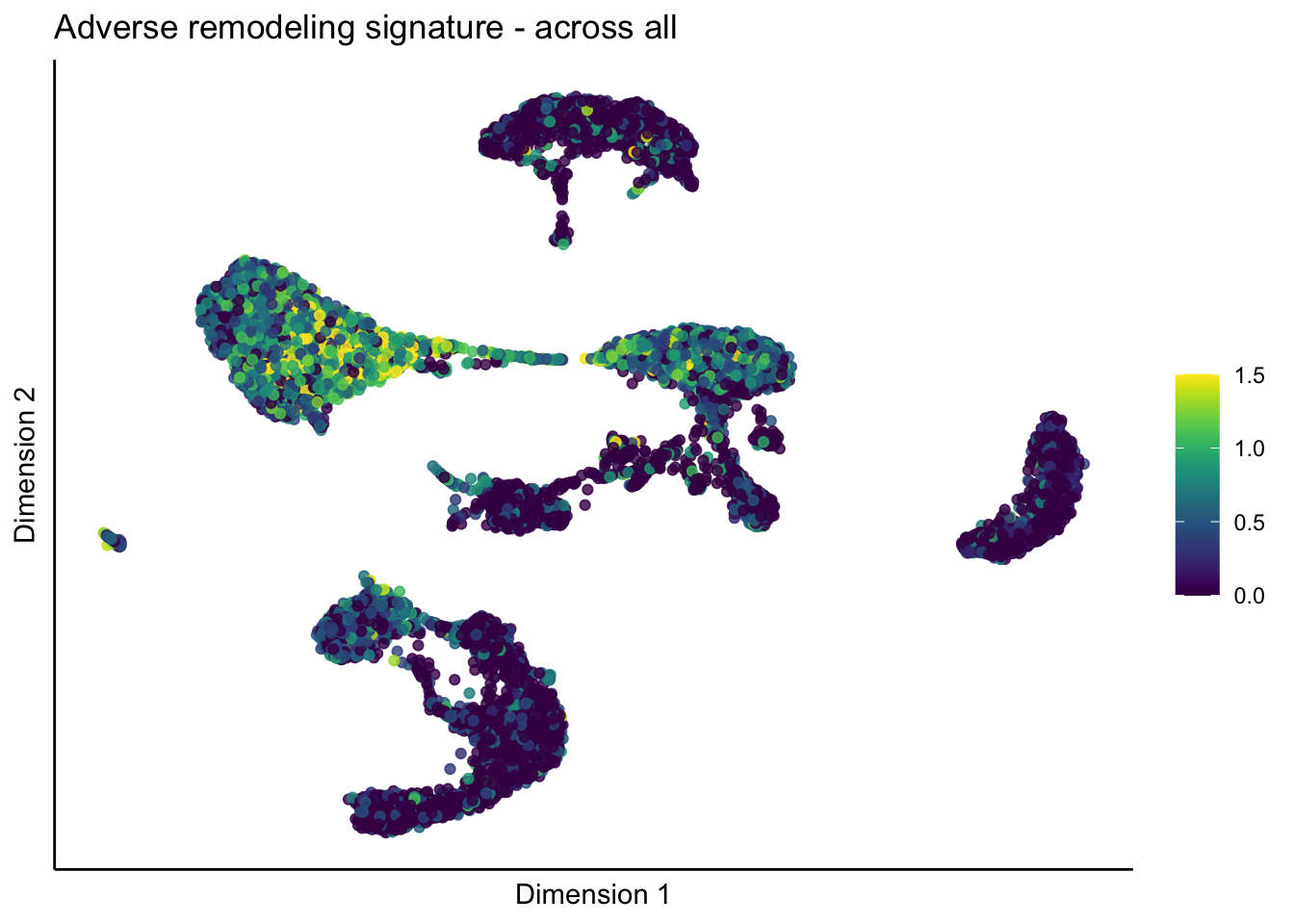
| Version | Author | Date |
|---|---|---|
| 70e878c | mluetge | 2022-05-02 |
save objects
Idents(seurat) <- Idents(seurat) <- seurat$integrated_snn_res.0.25
saveRDS(seurat, file = paste0(basedir,
"/data/humanHearts_intAcrossPat_Normal_HF_Myocarditis.rds"))
saveRDS(seuratSub, file = paste0(basedir,
"/data/humanHearts_intAcrossPat_Normal_Myocarditis.rds"))
saveRDS(seuratSub2, file = paste0(basedir,
"/data/humanHearts_intAcrossPat_Normal_HF.rds"))
write.table(DEgenes,
file=paste0(basedir,
"/data/humanHearts_intAcrossPat_NORMALvsHFvsMYO_overallDEGenes.txt"),
row.names = FALSE, col.names = TRUE, quote = FALSE, sep = "\t")session info
sessionInfo()R version 4.1.0 (2021-05-18)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] sctransform_0.3.3 viridis_0.6.2
[3] viridisLite_0.4.0 pheatmap_1.0.12
[5] ggpubr_0.4.0 ggsci_2.9
[7] runSeurat3_0.1.0 here_1.0.1
[9] magrittr_2.0.3 sp_1.4-7
[11] SeuratObject_4.1.0 Seurat_4.1.1
[13] forcats_0.5.1 stringr_1.4.0
[15] dplyr_1.0.9 purrr_0.3.4
[17] readr_2.1.2 tidyr_1.2.0
[19] tibble_3.1.7 ggplot2_3.3.6
[21] tidyverse_1.3.1 SingleCellExperiment_1.14.1
[23] SummarizedExperiment_1.22.0 Biobase_2.52.0
[25] GenomicRanges_1.44.0 GenomeInfoDb_1.28.4
[27] IRanges_2.26.0 S4Vectors_0.30.2
[29] BiocGenerics_0.38.0 MatrixGenerics_1.4.3
[31] matrixStats_0.62.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 reticulate_1.24 tidyselect_1.1.2
[4] htmlwidgets_1.5.4 grid_4.1.0 Rtsne_0.16
[7] munsell_0.5.0 codetools_0.2-18 ica_1.0-2
[10] future_1.25.0 miniUI_0.1.1.1 withr_2.5.0
[13] spatstat.random_2.2-0 colorspace_2.0-3 progressr_0.10.0
[16] highr_0.9 knitr_1.39 rstudioapi_0.13
[19] ROCR_1.0-11 ggsignif_0.6.3 tensor_1.5
[22] listenv_0.8.0 labeling_0.4.2 git2r_0.30.1
[25] GenomeInfoDbData_1.2.6 polyclip_1.10-0 bit64_4.0.5
[28] farver_2.1.0 rprojroot_2.0.3 parallelly_1.31.1
[31] vctrs_0.4.1 generics_0.1.2 xfun_0.30
[34] R6_2.5.1 bitops_1.0-7 spatstat.utils_2.3-1
[37] DelayedArray_0.18.0 assertthat_0.2.1 vroom_1.5.7
[40] promises_1.2.0.1 scales_1.2.0 rgeos_0.5-9
[43] gtable_0.3.0 globals_0.15.0 goftest_1.2-3
[46] workflowr_1.7.0 rlang_1.0.2 splines_4.1.0
[49] rstatix_0.7.0 lazyeval_0.2.2 spatstat.geom_2.4-0
[52] broom_0.8.0 yaml_2.3.5 reshape2_1.4.4
[55] abind_1.4-5 modelr_0.1.8 backports_1.4.1
[58] httpuv_1.6.5 tools_4.1.0 ellipsis_0.3.2
[61] spatstat.core_2.4-2 jquerylib_0.1.4 RColorBrewer_1.1-3
[64] ggridges_0.5.3 Rcpp_1.0.8.3 plyr_1.8.7
[67] zlibbioc_1.38.0 RCurl_1.98-1.6 rpart_4.1.16
[70] deldir_1.0-6 pbapply_1.5-0 cowplot_1.1.1
[73] zoo_1.8-10 haven_2.5.0 ggrepel_0.9.1
[76] cluster_2.1.3 fs_1.5.2 data.table_1.14.2
[79] RSpectra_0.16-1 scattermore_0.8 lmtest_0.9-40
[82] reprex_2.0.1 RANN_2.6.1 whisker_0.4
[85] fitdistrplus_1.1-8 hms_1.1.1 patchwork_1.1.1
[88] mime_0.12 evaluate_0.15 xtable_1.8-4
[91] readxl_1.4.0 gridExtra_2.3 compiler_4.1.0
[94] KernSmooth_2.23-20 crayon_1.5.1 htmltools_0.5.2
[97] mgcv_1.8-40 later_1.3.0 tzdb_0.3.0
[100] lubridate_1.8.0 DBI_1.1.2 dbplyr_2.1.1
[103] MASS_7.3-57 Matrix_1.4-1 car_3.0-13
[106] cli_3.3.0 igraph_1.3.1 pkgconfig_2.0.3
[109] plotly_4.10.0 spatstat.sparse_2.1-1 xml2_1.3.3
[112] bslib_0.3.1 XVector_0.32.0 rvest_1.0.2
[115] digest_0.6.29 RcppAnnoy_0.0.19 spatstat.data_2.2-0
[118] rmarkdown_2.14 cellranger_1.1.0 leiden_0.3.10
[121] uwot_0.1.11 shiny_1.7.1 lifecycle_1.0.1
[124] nlme_3.1-157 jsonlite_1.8.0 carData_3.0-5
[127] limma_3.48.3 fansi_1.0.3 pillar_1.7.0
[130] lattice_0.20-45 fastmap_1.1.0 httr_1.4.3
[133] survival_3.3-1 glue_1.6.2 png_0.1-7
[136] bit_4.0.4 stringi_1.7.6 sass_0.4.1
[139] irlba_2.3.5 future.apply_1.9.0 date()[1] "Mon May 9 15:30:27 2022"
sessionInfo()R version 4.1.0 (2021-05-18)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] sctransform_0.3.3 viridis_0.6.2
[3] viridisLite_0.4.0 pheatmap_1.0.12
[5] ggpubr_0.4.0 ggsci_2.9
[7] runSeurat3_0.1.0 here_1.0.1
[9] magrittr_2.0.3 sp_1.4-7
[11] SeuratObject_4.1.0 Seurat_4.1.1
[13] forcats_0.5.1 stringr_1.4.0
[15] dplyr_1.0.9 purrr_0.3.4
[17] readr_2.1.2 tidyr_1.2.0
[19] tibble_3.1.7 ggplot2_3.3.6
[21] tidyverse_1.3.1 SingleCellExperiment_1.14.1
[23] SummarizedExperiment_1.22.0 Biobase_2.52.0
[25] GenomicRanges_1.44.0 GenomeInfoDb_1.28.4
[27] IRanges_2.26.0 S4Vectors_0.30.2
[29] BiocGenerics_0.38.0 MatrixGenerics_1.4.3
[31] matrixStats_0.62.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 reticulate_1.24 tidyselect_1.1.2
[4] htmlwidgets_1.5.4 grid_4.1.0 Rtsne_0.16
[7] munsell_0.5.0 codetools_0.2-18 ica_1.0-2
[10] future_1.25.0 miniUI_0.1.1.1 withr_2.5.0
[13] spatstat.random_2.2-0 colorspace_2.0-3 progressr_0.10.0
[16] highr_0.9 knitr_1.39 rstudioapi_0.13
[19] ROCR_1.0-11 ggsignif_0.6.3 tensor_1.5
[22] listenv_0.8.0 labeling_0.4.2 git2r_0.30.1
[25] GenomeInfoDbData_1.2.6 polyclip_1.10-0 bit64_4.0.5
[28] farver_2.1.0 rprojroot_2.0.3 parallelly_1.31.1
[31] vctrs_0.4.1 generics_0.1.2 xfun_0.30
[34] R6_2.5.1 bitops_1.0-7 spatstat.utils_2.3-1
[37] DelayedArray_0.18.0 assertthat_0.2.1 vroom_1.5.7
[40] promises_1.2.0.1 scales_1.2.0 rgeos_0.5-9
[43] gtable_0.3.0 globals_0.15.0 goftest_1.2-3
[46] workflowr_1.7.0 rlang_1.0.2 splines_4.1.0
[49] rstatix_0.7.0 lazyeval_0.2.2 spatstat.geom_2.4-0
[52] broom_0.8.0 yaml_2.3.5 reshape2_1.4.4
[55] abind_1.4-5 modelr_0.1.8 backports_1.4.1
[58] httpuv_1.6.5 tools_4.1.0 ellipsis_0.3.2
[61] spatstat.core_2.4-2 jquerylib_0.1.4 RColorBrewer_1.1-3
[64] ggridges_0.5.3 Rcpp_1.0.8.3 plyr_1.8.7
[67] zlibbioc_1.38.0 RCurl_1.98-1.6 rpart_4.1.16
[70] deldir_1.0-6 pbapply_1.5-0 cowplot_1.1.1
[73] zoo_1.8-10 haven_2.5.0 ggrepel_0.9.1
[76] cluster_2.1.3 fs_1.5.2 data.table_1.14.2
[79] RSpectra_0.16-1 scattermore_0.8 lmtest_0.9-40
[82] reprex_2.0.1 RANN_2.6.1 whisker_0.4
[85] fitdistrplus_1.1-8 hms_1.1.1 patchwork_1.1.1
[88] mime_0.12 evaluate_0.15 xtable_1.8-4
[91] readxl_1.4.0 gridExtra_2.3 compiler_4.1.0
[94] KernSmooth_2.23-20 crayon_1.5.1 htmltools_0.5.2
[97] mgcv_1.8-40 later_1.3.0 tzdb_0.3.0
[100] lubridate_1.8.0 DBI_1.1.2 dbplyr_2.1.1
[103] MASS_7.3-57 Matrix_1.4-1 car_3.0-13
[106] cli_3.3.0 igraph_1.3.1 pkgconfig_2.0.3
[109] plotly_4.10.0 spatstat.sparse_2.1-1 xml2_1.3.3
[112] bslib_0.3.1 XVector_0.32.0 rvest_1.0.2
[115] digest_0.6.29 RcppAnnoy_0.0.19 spatstat.data_2.2-0
[118] rmarkdown_2.14 cellranger_1.1.0 leiden_0.3.10
[121] uwot_0.1.11 shiny_1.7.1 lifecycle_1.0.1
[124] nlme_3.1-157 jsonlite_1.8.0 carData_3.0-5
[127] limma_3.48.3 fansi_1.0.3 pillar_1.7.0
[130] lattice_0.20-45 fastmap_1.1.0 httr_1.4.3
[133] survival_3.3-1 glue_1.6.2 png_0.1-7
[136] bit_4.0.4 stringi_1.7.6 sass_0.4.1
[139] irlba_2.3.5 future.apply_1.9.0