Self-organising map (SOM) analysis
Robert Schlegel
2020-08-25
Last updated: 2020-09-03
Checks: 7 0
Knit directory: MHWflux/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200117) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version d1c9bad. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/ALL_anom.Rda
Ignored: data/ALL_other.Rda
Ignored: data/ALL_ts_anom.Rda
Ignored: data/ERA5_evp_anom.Rda
Ignored: data/ERA5_lhf_anom.Rda
Ignored: data/ERA5_lwr_anom.Rda
Ignored: data/ERA5_mslp_anom.Rda
Ignored: data/ERA5_pcp_anom.Rda
Ignored: data/ERA5_qnet_anom.Rda
Ignored: data/ERA5_shf_anom.Rda
Ignored: data/ERA5_swr_anom.Rda
Ignored: data/ERA5_t2m_anom.Rda
Ignored: data/ERA5_tcc_anom.Rda
Ignored: data/ERA5_u_anom.Rda
Ignored: data/ERA5_v_anom.Rda
Ignored: data/GLORYS_all_anom.Rda
Ignored: data/OISST_all_anom.Rda
Ignored: data/packet.Rda
Ignored: data/som.Rda
Ignored: data/synoptic_states.Rda
Ignored: data/synoptic_states_other.Rda
Unstaged changes:
Modified: analysis/_site.yml
Modified: analysis/node-summary.Rmd
Modified: code/workflow.R
Modified: output/NWA_product_regions.pdf
Modified: talk/WHOI_talk.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/som.Rmd) and HTML (docs/som.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | d1c9bad | robwschlegel | 2020-09-03 | Re-built site. |
| Rmd | 66f3736 | robwschlegel | 2020-08-26 | More edits to the figures |
| Rmd | 4b04d7a | robwschlegel | 2020-08-14 | Renamed some files in preparation for the file runs on the SOM sized data |
| Rmd | c0c599d | robwschlegel | 2020-08-12 | Combining the MHWNWA and MHWflux code bases |
Introduction
This vignette contains the code used to perform the self-organising map (SOM) analysis on the mean synoptic states created in the data preparation vignette. We’ll start by creating custom packets that meet certain experimental criteria before feeding them into a SOM. The full summary of the results may be seen in the Node summary vignette.
# Load functions and objects to be used below
source("code/functions.R")Data packet
In this step we will create a data packet that can be fed directly into the SOM algorithm. This means that it must be converted into a super-wide matrix format. In the first run of this analysis on the NAPA model data it was found that the inclusion of the Labrador Sea complicated the results quite a bit. It was also unclear whether or not the Gulf of St Lawrence (gsl) region should be included in the analysis. So in the second run of this analysis multiple different SOM variations were employed and it was decided that the gsl region should be included.
Prep synoptic state packets
Up first we must create the synoptic state packets.
# Set number of cores
# NB: 50 cores uses too much RAM
registerDoParallel(cores = 20)
# Load needed data
ALL_anom <- readRDS("data/ALL_anom.Rda")
ALL_other <- readRDS("data/ALL_other.Rda")
# Create one big anomaly packet from OISST data
system.time(synoptic_states <- plyr::ddply(OISST_MHW_event, c("region", "event_no"),
data_packet_func, .parallel = T, df = ALL_anom)) # 129 seconds
# Save
saveRDS(synoptic_states, "data/synoptic_states.Rda")
# Create other synoptic states per MHW per variable
doParallel::registerDoParallel(cores = 10) # NB: Be careful here...
system.time(synoptic_states_other <- plyr::ddply(OISST_MHW_event, c("region", "event_no"),
data_packet_func, .parallel = T, df = ALL_other)) # 212 seconds
# Save
saveRDS(synoptic_states_other, "data/synoptic_states_other.Rda")Create SOM packet
With all of our data ready we may now prepare and save them for the SOM.
## Create wide data packet that is fed to SOM
system.time(packet <- synoptic_states %>%
select(region, event_no, synoptic) %>%
unnest(cols = "synoptic") %>%
wide_packet_func()) # 79 seconds
# Save
saveRDS(packet, "data/packet.Rda")Run SOM models
Now we feed the SOM with a function that ingests the data packet and produces results for us. The function below has been greatly expanded on from the previous version of this project and now performs all of the SOM related work in one go. This allowed me to remove a couple hundreds lines of code and text from this vignette.
# # OISST SOM analysis
packet <- readRDS("data/packet.Rda")
synoptic_states_other <- readRDS("data/synoptic_states_other.Rda")
system.time(som <- som_model_PCI(packet, synoptic_states_other)) # 176 seconds
saveRDS(som, file = "data/som.Rda")Correlations
The code used for the MHWNWA project was also used on the GLORYS MHW results to create a SOM for the GLORYS data. I had a look at them and they were fine, but after further thinking we have decided to use the OISST. These SOM nodes are used below to cluster the correlation results to see how the differ based on the SOM. For reference to the results below let’s see what the SOM results for the regions + seasons and Air temperature + MSLP look like.
# Load the SOM from the MHWNWA
SOM <- readRDS("data/som.Rda")
# Grab only the node info
SOM_info <- SOM$info
# Load correlations
ALL_cor_wide <- readRDS("data/ALL_cor.Rda") %>%
ungroup() %>%
filter(Parameter1 == "sst") %>%
dplyr::select(region:ts, Parameter2, r, n_Obs) %>%
pivot_wider(values_from = r, names_from = Parameter2)
# Combine MHW metrics and correlation results
events_cor_prep <- OISST_MHW_event %>%
dplyr::select(region, season, event_no, duration, intensity_mean, intensity_max,
intensity_cumulative, rate_onset, rate_decline) %>%
left_join(ALL_cor_wide, by = c("region", "season", "event_no")) %>%
# ungroup() %>%
dplyr::select(region:n_Obs, sst, bottomT, sss, mld_cum, mld_1_cum, t2m, tcc_cum, p_e_cum, mslp_cum,
lwr_budget, swr_budget, lhf_budget, shf_budget, qnet_budget)
# Join to the GLORYS MHW correlation results
events_cor_SOM <- left_join(events_cor_prep, SOM_info, by = c("region", "event_no"))
# Plotting function
plot_func <- function(df, name) {
ggplot(data = df, aes(x = node, y = ts)) +
geom_tile(aes(fill = value)) +
# facet_wrap(~name, scales = "free") +
scale_fill_gradient2(low = "blue", high = "red", name = name) +
coord_cartesian(expand = F)
}
# Summary stats per node shown as heatmap
nested_SOM <- events_cor_SOM %>%
dplyr::select(-event_no) %>%
mutate(node = as.factor(node)) %>%
group_by(node, ts) %>%
summarise_if(is.numeric, mean) %>%
pivot_longer(cols = duration:count) %>%
filter(name != "temp",
ts != "full") %>%
group_by(name) %>%
nest() %>%
mutate(plots = map2(data, name, plot_func))
# gridExtra::grid.arrange(grobs = nested_SOM$plots) # NB: The legends are too large for HTML
# Summary heatmap for correlation values only
events_cor_SOM %>%
dplyr::select(node, ts, bottomT:qnet_budget, -mld_1_cum) %>%
group_by(node, ts) %>%
summarise_if(is.numeric, mean) %>%
pivot_longer(cols = bottomT:qnet_budget) %>%
filter(name != "temp",
ts != "full") %>%
ungroup() %>%
mutate(node = as.factor(node),
ts = factor(ts, levels = c("decline", "full", "onset")),
name = case_when(name == "sst" ~ "SST",
name == "bottomT" ~ "Bottom",
name == "sss" ~ "SSS",
name == "mld_cum" ~ "MLD",
name == "mld_1_cum" ~ "MLD_1_c",
name == "t2m" ~ "Air",
name == "tcc_cum" ~ "Cloud",
name == "p_e_cum" ~ "P_E",
name == "mslp_cum" ~ "MSLP",
name == "lwr_budget" ~ "Qlw",
name == "swr_budget" ~ "Qsw",
name == "lhf_budget" ~ "Qlh",
name == "shf_budget" ~ "Qsh",
name == "qnet_budget" ~ "Qnet",
TRUE ~ name),
name = factor(name, levels = c("Qnet", "Qlw", "Qsw", "Qlh", "Qsh", "Cloud",
"P_E", "Air", "MSLP", "MLD", "SSS", "Bottom"))) %>%
ggplot(aes(x = name, y = ts)) +
geom_tile(aes(fill = value)) +
facet_wrap(~node, scales = "free") +
scale_fill_gradient2(low = "blue", high = "red") +
coord_cartesian(expand = F) +
labs(y = NULL, fill = "r (mean)") +
theme(legend.position = "bottom",
axis.text.x = element_text(angle = 30))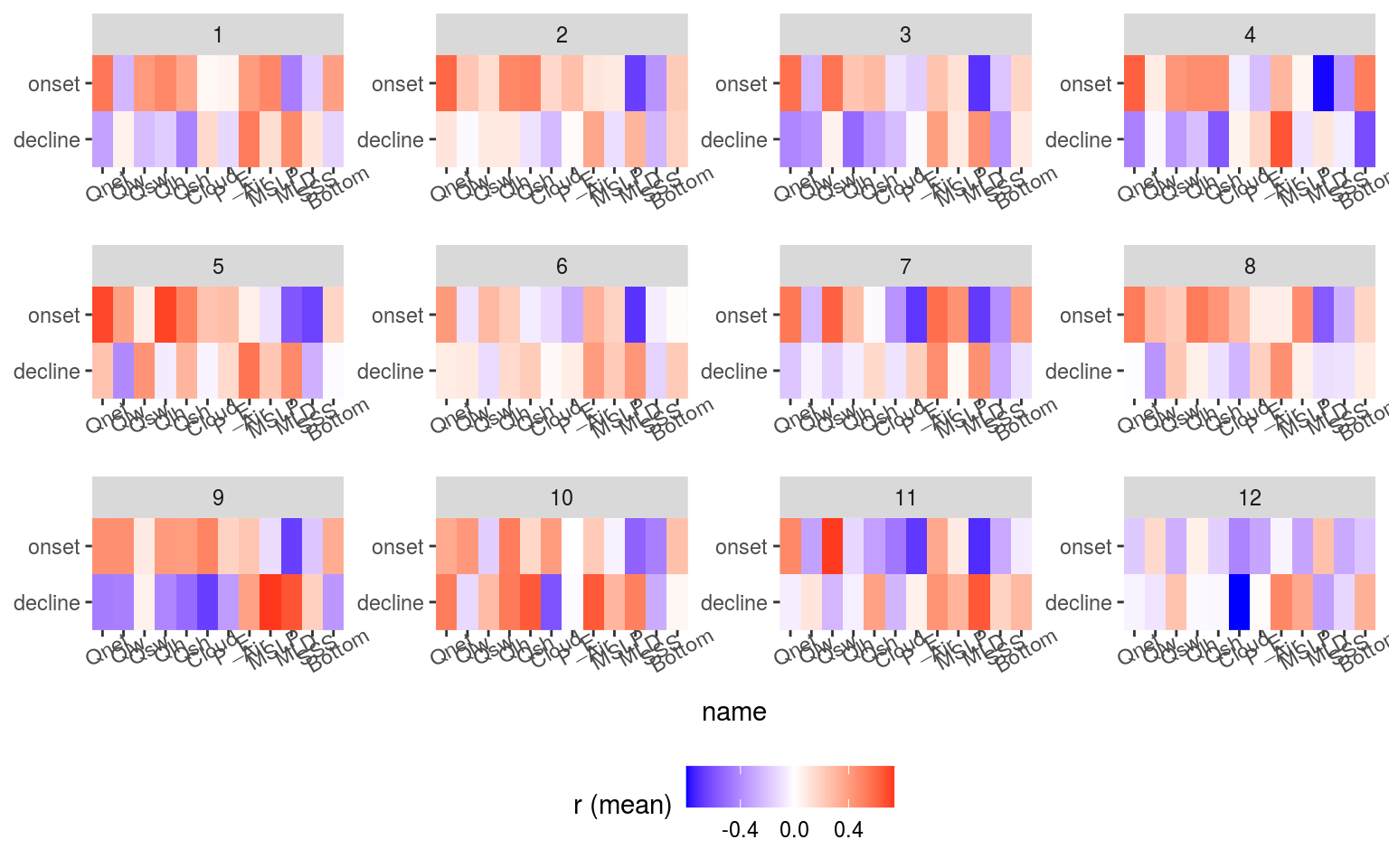
Some important patterns come through when we look at the summary correlation and MHW metric results when grouped into their SOM nodes. This is as far as the numeric results will go. From here out it is necessary for a human to look at these summary results with the SOM node results to discern the meaning of the combined results.
And there we have our SOM results. Up next in the Node summary vignette we will show the results with a range of visuals.
References
sessionInfo()R version 4.0.2 (2020-06-22)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 16.04.6 LTS
Matrix products: default
BLAS: /usr/lib/openblas-base/libblas.so.3
LAPACK: /usr/lib/libopenblasp-r0.2.18.so
locale:
[1] LC_CTYPE=en_CA.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_CA.UTF-8 LC_COLLATE=en_CA.UTF-8
[5] LC_MONETARY=en_CA.UTF-8 LC_MESSAGES=en_CA.UTF-8
[7] LC_PAPER=en_CA.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_CA.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] doParallel_1.0.15 iterators_1.0.12 foreach_1.5.0
[4] Metrics_0.1.4 yasomi_0.3 proxy_0.4-24
[7] e1071_1.7-3 ggraph_2.0.3 correlation_0.3.0
[10] tidync_0.2.4 heatwaveR_0.4.4.9000 lubridate_1.7.9
[13] data.table_1.13.0 forcats_0.5.0 stringr_1.4.0
[16] dplyr_1.0.1 purrr_0.3.4 readr_1.3.1
[19] tidyr_1.1.1 tibble_3.0.3 ggplot2_3.3.2
[22] tidyverse_1.3.0
loaded via a namespace (and not attached):
[1] fs_1.5.0 insight_0.9.0 httr_1.4.2 rprojroot_1.3-2
[5] tools_4.0.2 backports_1.1.8 R6_2.4.1 DBI_1.1.0
[9] lazyeval_0.2.2 colorspace_1.4-1 withr_2.2.0 gridExtra_2.3
[13] tidyselect_1.1.0 compiler_4.0.2 git2r_0.27.1 cli_2.0.2
[17] rvest_0.3.6 RNetCDF_2.3-1 xml2_1.3.2 plotly_4.9.2.1
[21] labeling_0.3 bayestestR_0.7.2 scales_1.1.1 digest_0.6.25
[25] rmarkdown_2.3 pkgconfig_2.0.3 htmltools_0.5.0 dbplyr_1.4.4
[29] htmlwidgets_1.5.1 rlang_0.4.7 readxl_1.3.1 rstudioapi_0.11
[33] generics_0.0.2 farver_2.0.3 jsonlite_1.7.0 magrittr_1.5
[37] ncmeta_0.2.5 parameters_0.8.2 Rcpp_1.0.5 munsell_0.5.0
[41] fansi_0.4.1 viridis_0.5.1 lifecycle_0.2.0 stringi_1.4.6
[45] whisker_0.4 yaml_2.2.1 MASS_7.3-51.6 grid_4.0.2
[49] blob_1.2.1 promises_1.1.1 ggrepel_0.8.2 crayon_1.3.4
[53] graphlayouts_0.7.0 haven_2.3.1 hms_0.5.3 knitr_1.29
[57] pillar_1.4.6 igraph_1.2.5 effectsize_0.3.2 codetools_0.2-16
[61] reprex_0.3.0 glue_1.4.1 evaluate_0.14 modelr_0.1.8
[65] vctrs_0.3.2 tweenr_1.0.1 httpuv_1.5.4 cellranger_1.1.0
[69] gtable_0.3.0 polyclip_1.10-0 assertthat_0.2.1 xfun_0.16
[73] ggforce_0.3.2 broom_0.7.0 tidygraph_1.2.0 later_1.1.0.1
[77] class_7.3-17 ncdf4_1.17 viridisLite_0.3.0 workflowr_1.6.2
[81] ellipsis_0.3.1