Transcription factor and kinase activity analysis
Last updated: 2021-07-21
Checks: 7 0
Knit directory: kinase_tf_mini_tuto/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210608) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version b364b6c. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rproj.user/
Ignored: omnipathr-log/
Ignored: renv/library/
Ignored: renv/staging/
Ignored: results/
Unstaged changes:
Modified: .Rhistory
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/index.Rmd) and HTML (docs/index.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | b364b6c | adugourd | 2021-07-21 | wflow_publish("analysis/*.Rmd") |
| html | 87802fa | Martin Garrido Rodriguez-Cordoba | 2021-06-11 | Build site. |
| Rmd | 5cd61ca | Martin Garrido Rodriguez-Cordoba | 2021-06-11 | wflow_publish(“analysis/index.Rmd”) |
| Rmd | bf1d18a | adugourd | 2021-06-11 | updated package |
| Rmd | 2cf552b | adugourd | 2021-06-11 | modified to decoupleR |
| html | 8e3f301 | Martin Garrido Rodriguez-Cordoba | 2021-06-09 | Build site. |
| Rmd | edae741 | Martin Garrido Rodriguez-Cordoba | 2021-06-09 | wflow_publish("analysis/*.Rmd") |
| Rmd | 81eb4b2 | Martin Garrido Rodriguez-Cordoba | 2021-06-09 | Start workflowr project. |
About
This is a short tutorial to show how to estimate transcription factor and kinase activities from transcriptomic and phosphoproteomic data, respectively. First, we load the packages and functions that we will use during the analysis
library(tidyverse)
library(here)
library(OmnipathR)
library(dorothea)
library(decoupleR)
library(workflowr)
library(rmarkdown)
library(org.Hs.eg.db)
source(here("code/utils.R"))Kinase activity estimation
Then, we load the results of the phosphoproteomic differential analysis (carried out previously) and format it properly. In addition, here we represent the top 10 up and down regulated phosphosites.
phospho_differential_analysis <- read_csv(here("data/phospho_differential_analysis.csv")) %>%
tibble::column_to_rownames("psite_ID")
── Column specification ────────────────────────────────────────────────────────
cols(
psite_ID = col_character(),
t_value_tumor_vs_healthy = col_double()
)plot_top_features(phospho_differential_analysis, n_top = 10) +
ggtitle('Phosphosite space')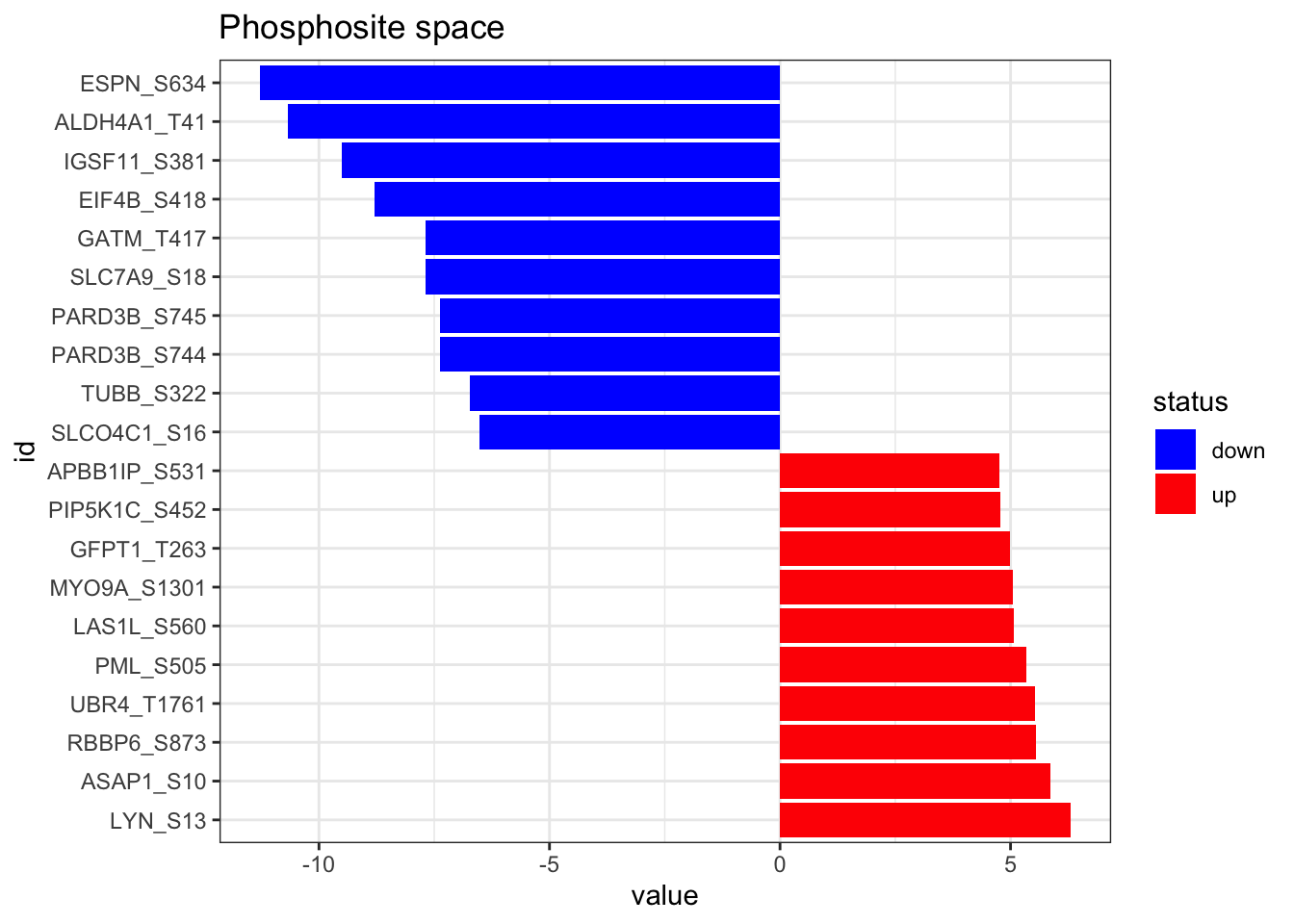
| Version | Author | Date |
|---|---|---|
| 8e3f301 | Martin Garrido Rodriguez-Cordoba | 2021-06-09 |
Next, we can load the prior knowledge interactions, composed by kinase-target relationships
omnipath_ptm <- OmnipathR::get_signed_ptms() %>%
dplyr::filter(modification %in% c("dephosphorylation","phosphorylation")) %>%
dplyr::mutate(p_site = paste0(substrate_genesymbol, "_", residue_type, residue_offset),
mor = ifelse(modification == "phosphorylation", 1, -1)) %>%
dplyr::transmute(p_site, enzyme_genesymbol, mor) %>%
as.data.frame()
omnipath_ptm$likelihood <- 1
#we remove ambiguous modes of regulations
omnipath_ptm$id <- paste(omnipath_ptm$p_site,omnipath_ptm$enzyme_genesymbol,sep ="")
omnipath_ptm <- omnipath_ptm[!duplicated(omnipath_ptm$id),]
omnipath_ptm <- omnipath_ptm[,-5]On a final step, we run viper to get the Kinase activities from the phosphoproteomic data. You can also run that on wour normalised intesity matrix of phosphosites directly, as long as it is formatted as a dataframe of similar format as here. User is strongly encouraged to check https://github.com/saezlab/decoupleR for more info on the algorithm here employed.
#rename KSN to fit decoupler format
names(omnipath_ptm)[c(1,2)] <- c("target","tf")
kin_activity <- run_mean(mat = as.matrix(phospho_differential_analysis),network = omnipath_ptm, times = 1000)
kin_activity <- kin_activity[kin_activity$statistic == "normalized_mean",c(2,4)] %>%
tibble::column_to_rownames(var = "tf")plot_top_features(kin_activity, n_top = 10) +
ggtitle('Kinase space')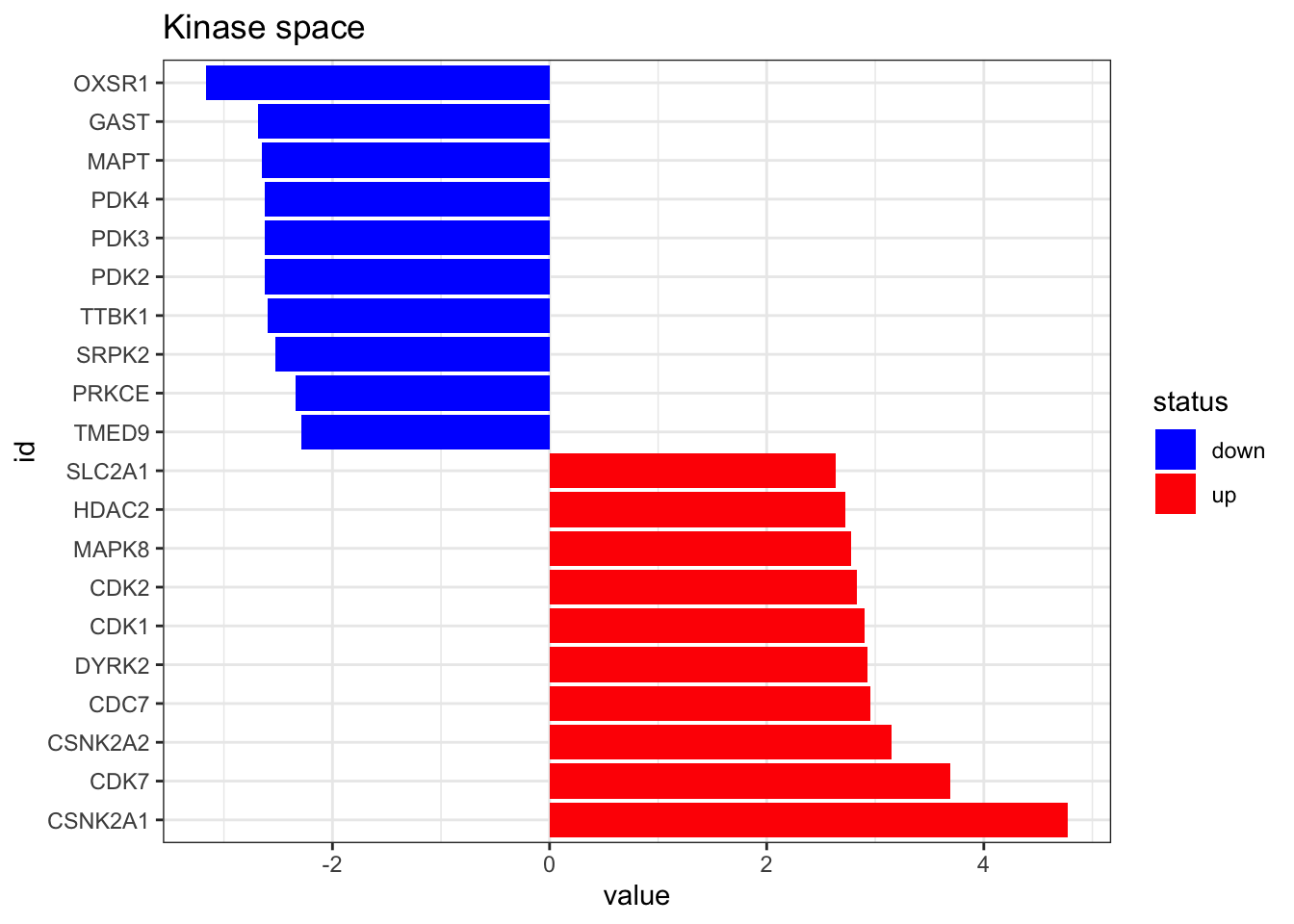
Transcription factor activity
First we import the dorothea regulons (using only confidence A, B, and C), see dorothea publication for information on confidence levels.
dorothea_df <- dorothea_hs %>%
dplyr::filter(confidence %in% c("A", "B", "C")) %>%
dplyr::select(target, tf, mor) %>%
as.data.frame()
dorothea_df$likelihood <- 1Now we import the RNAseq data. It has entrez gene identifiers, but we need it to have gene symbols to match dorothea database, so we have to do some id conversion as well. Here we can also take a look to the top altered features.
RNA_differential_analysis <- read_csv(here("data/RNA_differential_analysis.csv")) %>%
tibble::column_to_rownames("ID") %>%
dplyr::select(t) %>%
as.matrix() %>%
translateMatrixWithDb(mat = ., db = org.Hs.eg.db,
sourceKey = "ENTREZID", targetKey = "SYMBOL")
── Column specification ────────────────────────────────────────────────────────
cols(
ID = col_double(),
logFC = col_double(),
AveExpr = col_double(),
t = col_double(),
P.Value = col_double(),
adj.P.Val = col_double(),
B = col_double()
)'select()' returned 1:1 mapping between keys and columns------------------------------------------------No input summarise function detected, using first match on multi-mapping situations.------------------------------------------------
151 of 15919 input ids on the translator data frame could not be mapped.
0 of 15919 input ids on the translator data frame were mapped to 2 or more target ids.
0 of 15768 target ids on the translator data frame were mapped to 2 or more input ids.
------------------------------------------------
Input keys were finally mapped to 15768 target ids.
------------------------------------------------plot_top_features(RNA_differential_analysis, n_top = 10) +
ggtitle('Transcriptomic space')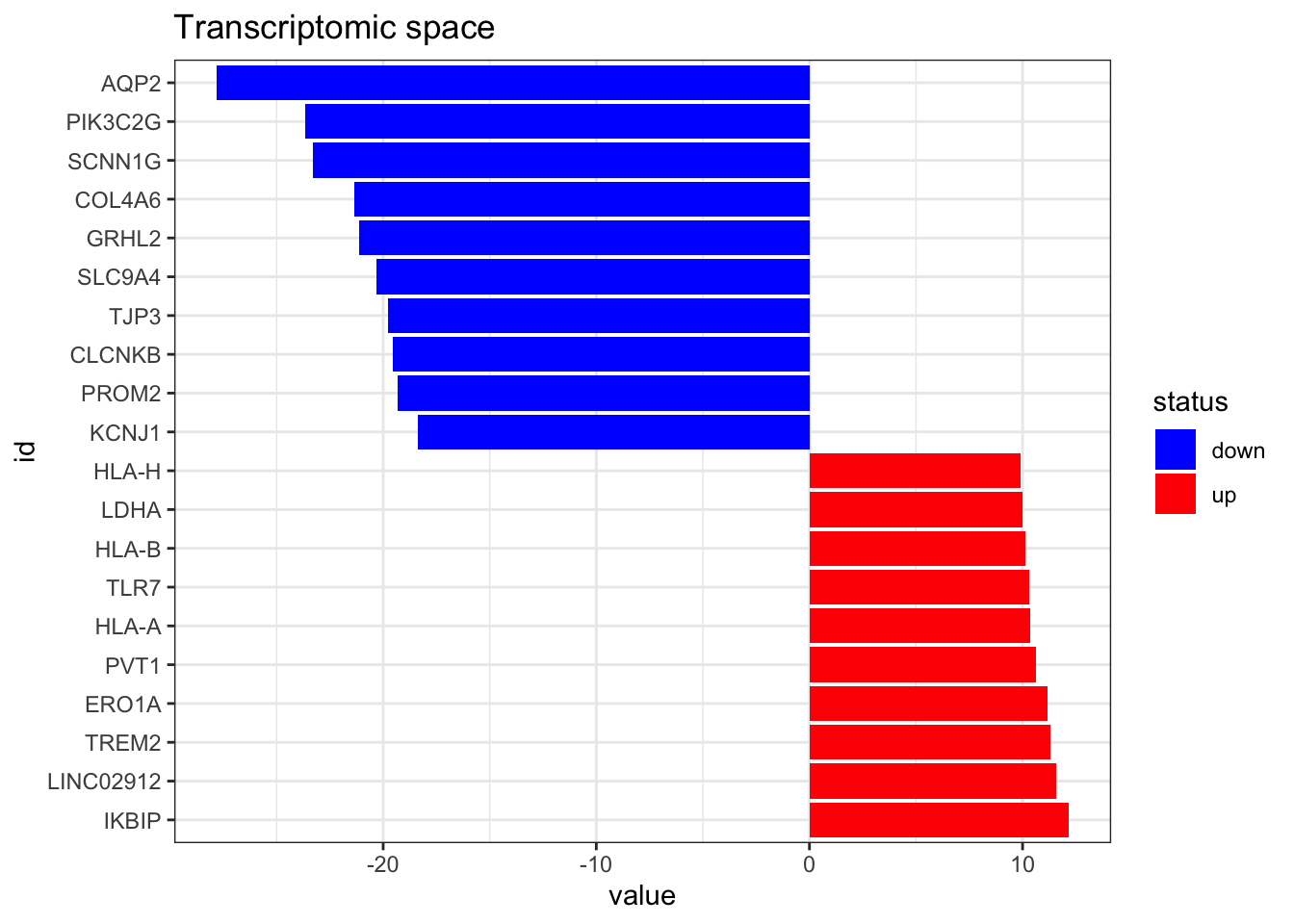
Now we estimate the TF activities using run_mean from decoupleR and visualize the top 10 altered TFs
TF_activities <- as.data.frame(run_mean(mat = as.matrix(RNA_differential_analysis), network = dorothea_df, times = 1000))
TF_activities <- TF_activities %>%
dplyr::filter(statistic == "normalized_mean") %>%
dplyr::select(tf, score) %>%
tibble::column_to_rownames(var = "tf")plot_top_features(TF_activities, n_top = 10) +
ggtitle('TF space')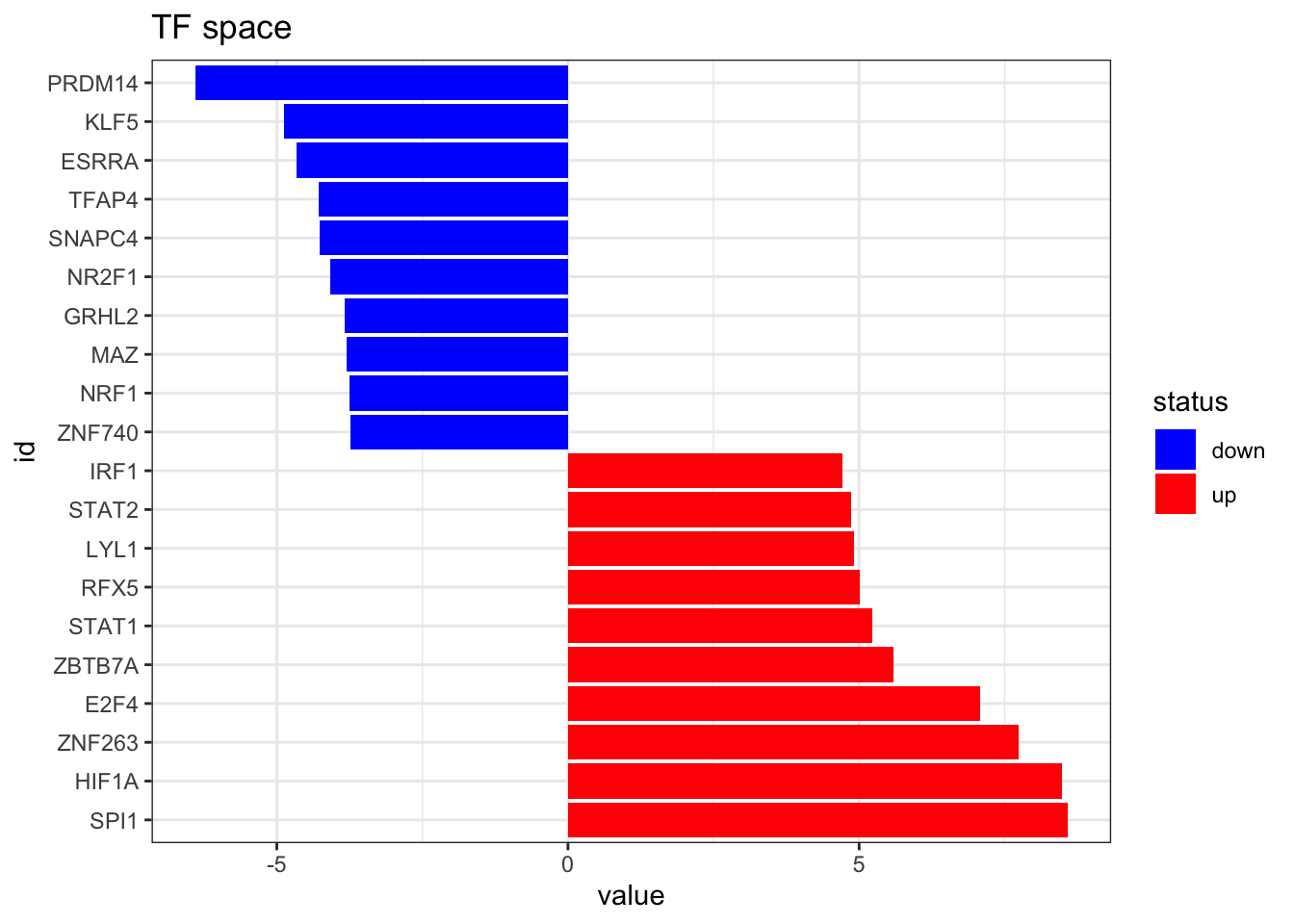
Next steps
Now you have succefully estimated kinase and TF activities from phosphoproteomic and transcriptomic. You can now combine them together and use them as input for COSMOS. You may also leave them separated and use them a separated input and measurments in cosmos, if you lack metabolomic data
See https://github.com/saezlab/cosmosR for more info on how to use cosmos
sessionInfo()R version 4.1.0 (2021-05-18)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats4 stats graphics grDevices datasets utils
[8] methods base
other attached packages:
[1] org.Hs.eg.db_3.13.0 AnnotationDbi_1.54.1 IRanges_2.26.0
[4] S4Vectors_0.30.0 Biobase_2.52.0 BiocGenerics_0.38.0
[7] rmarkdown_2.8 decoupleR_1.1.0 dorothea_1.4.1
[10] OmnipathR_3.0.0 here_1.0.1 forcats_0.5.1
[13] stringr_1.4.0 dplyr_1.0.6 purrr_0.3.4
[16] readr_1.4.0 tidyr_1.1.3 tibble_3.1.2
[19] ggplot2_3.3.3 tidyverse_1.3.1 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] colorspace_2.0-1 ellipsis_0.3.2 rprojroot_2.0.2
[4] XVector_0.32.0 fs_1.5.0 rstudioapi_0.13
[7] farver_2.1.0 bit64_4.0.5 fansi_0.5.0
[10] lubridate_1.7.10 xml2_1.3.2 cachem_1.0.5
[13] knitr_1.33 jsonlite_1.7.2 speedglm_0.3-3
[16] bcellViper_1.28.0 broom_0.7.6 dbplyr_2.1.1
[19] png_0.1-7 compiler_4.1.0 httr_1.4.2
[22] backports_1.2.1 assertthat_0.2.1 Matrix_1.3-4
[25] fastmap_1.1.0 cli_2.5.0 later_1.2.0
[28] htmltools_0.5.1.1 prettyunits_1.1.1 tools_4.1.0
[31] igraph_1.2.6 gtable_0.3.0 glue_1.4.2
[34] GenomeInfoDbData_1.2.6 rappdirs_0.3.3 Rcpp_1.0.6
[37] cellranger_1.1.0 vctrs_0.3.8 Biostrings_2.60.1
[40] xfun_0.23 rvest_1.0.0 lifecycle_1.0.0
[43] renv_0.13.2 MASS_7.3-54 zlibbioc_1.38.0
[46] scales_1.1.1 hms_1.1.0 promises_1.2.0.1
[49] yaml_2.2.1 curl_4.3.1 memoise_2.0.0
[52] stringi_1.6.2 RSQLite_2.2.7 highr_0.9
[55] checkmate_2.0.0 GenomeInfoDb_1.28.0 rlang_0.4.11
[58] pkgconfig_2.0.3 bitops_1.0-7 evaluate_0.14
[61] lattice_0.20-44 labeling_0.4.2 bit_4.0.4
[64] tidyselect_1.1.1 logger_0.2.0 magrittr_2.0.1
[67] R6_2.5.0 generics_0.1.0 DBI_1.1.1
[70] pillar_1.6.1 haven_2.4.1 whisker_0.4
[73] withr_2.4.2 KEGGREST_1.32.0 RCurl_1.98-1.3
[76] modelr_0.1.8 crayon_1.4.1 utf8_1.2.1
[79] progress_1.2.2 grid_4.1.0 readxl_1.3.1
[82] blob_1.2.1 git2r_0.28.0 reprex_2.0.0
[85] digest_0.6.27 httpuv_1.6.1 munsell_0.5.0