Meta anlaysis comparing chronic and acute mouse models
Christian H. Holland
2020-12-19
Last updated: 2020-12-20
Checks: 7 0
Knit directory: meta-liver/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20201218) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version c78e883. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/mouse-acute-apap_cache/
Ignored: analysis/mouse-acute-bdl_cache/
Ignored: analysis/mouse-acute-ccl4_cache/
Ignored: analysis/mouse-acute-lps_cache/
Ignored: analysis/mouse-acute-ph_cache/
Ignored: analysis/mouse-acute-tunicamycin_cache/
Ignored: analysis/mouse-chronic-ccl4_cache/
Ignored: code/.DS_Store
Ignored: data/.DS_Store
Ignored: data/annotation/
Ignored: data/mouse-acute-apap/
Ignored: data/mouse-acute-bdl/
Ignored: data/mouse-acute-ccl4/
Ignored: data/mouse-acute-lps/
Ignored: data/mouse-acute-ph/
Ignored: data/mouse-acute-tunicamycin/
Ignored: data/mouse-chronic-ccl4/
Ignored: external_software/.DS_Store
Ignored: external_software/README.html
Ignored: external_software/stem/.DS_Store
Ignored: output/.DS_Store
Ignored: output/meta-chronic-vs-acute/
Ignored: output/mouse-acute-apap/
Ignored: output/mouse-acute-bdl/
Ignored: output/mouse-acute-ccl4/
Ignored: output/mouse-acute-lps/
Ignored: output/mouse-acute-ph/
Ignored: output/mouse-acute-tunicamycin/
Ignored: output/mouse-chronic-ccl4/
Ignored: renv/library/
Ignored: renv/staging/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/meta-analysis-chronic-vs-acute.Rmd) and HTML (docs/meta-analysis-chronic-vs-acute.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c78e883 | christianholland | 2020-12-20 | stem characterization |
Introduction
Here we integrate various acute liver damage mouse models with the chronic CCl4 mouse model to identify chronic exclusively and commonly regulated genes.
Libraries and sources
These libraries and sources are used for this analysis.
library(tidyverse)
library(tidylog)
library(here)
library(fgsea)
library(dorothea)
library(progeny)
library(biobroom)
library(circlize)
library(AachenColorPalette)
library(lemon)
library(VennDiagram)
library(ComplexHeatmap)
library(msigdf) # remotes::install_github("ToledoEM/msigdf@v7.1")
options("tidylog.display" = list(print))
source(here("code/utils-utils.R"))
source(here("code/utils-plots.R"))Definition of global variables that are used throughout this analysis.
# i/o
data_path <- "data/meta-chronic-vs-acute"
output_path <- "output/meta-chronic-vs-acute"
# graphical parameters
# fontsize
fz <- 9
# color function for heatmaps
col_fun <- colorRamp2(
c(-4, 0, 4),
c(aachen_color("blue"), "white", aachen_color("red"))
)Merging data of all mouse models
Merging contrasts
Contrasts from all available mouse models are merged into a single object.
# acute
tun <- readRDS(here("output/mouse-acute-tunicamycin/limma_result.rds")) %>%
mutate(treatment = "tunicamycin", source = "wek", class = "acute")
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
lps <- readRDS(here("output/mouse-acute-lps/limma_result.rds")) %>%
filter(contrast == "inLiver_lps_vs_ctrl") %>%
mutate(treatment = "lps", source = "godoy", class = "acute")
#> filter: removed 143,563 rows (88%), 20,509 rows remaining
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
acute_ccl4 <- readRDS(here("output/mouse-acute-ccl4/limma_result.rds")) %>%
filter(contrast_reference == "ccl4") %>%
select(-contrast_reference) %>%
mutate(treatment = "ccl4", source = "godoy", class = "acute")
#> filter: removed 164,072 rows (50%), 164,072 rows remaining
#> select: dropped one variable (contrast_reference)
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
ph <- readRDS(here("output/mouse-acute-ph/limma_result.rds")) %>%
filter(contrast_reference == "hepatec") %>%
select(-contrast_reference) %>%
mutate(treatment = "ph", source = "godoy", class = "acute")
#> filter: removed 225,599 rows (50%), 225,599 rows remaining
#> select: dropped one variable (contrast_reference)
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
apap <- readRDS(here("output/mouse-acute-apap/limma_result.rds")) %>%
filter(contrast_reference == "apap") %>%
select(-contrast_reference) %>%
mutate(treatment = "apap", source = "ghallab", class = "acute")
#> filter: removed 184,581 rows (50%), 184,581 rows remaining
#> select: dropped one variable (contrast_reference)
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
bdl <- readRDS(here("output/mouse-acute-bdl/limma_result.rds")) %>%
filter(contrast_reference == "bdl") %>%
select(-contrast_reference) %>%
mutate(treatment = "bdl", source = "ghallab", class = "acute")
#> filter: removed 215,676 rows (69%), 95,856 rows remaining
#> select: dropped one variable (contrast_reference)
#> mutate: new variable 'treatment' (character) with one unique value and 0% NA
#> new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
# chronic
chronic_ccl4 <- readRDS(here("output/mouse-chronic-ccl4/limma_result.rds")) %>%
filter(contrast_reference == "pure_ccl4") %>%
select(-contrast_reference) %>%
mutate(
source = "ghallab", class = "chronic",
treatment = "pure_ccl4"
)
#> filter: removed 138,042 rows (75%), 46,014 rows remaining
#> select: dropped one variable (contrast_reference)
#> mutate: new variable 'source' (character) with one unique value and 0% NA
#> new variable 'class' (character) with one unique value and 0% NA
#> new variable 'treatment' (character) with one unique value and 0% NA
combined_contrasts <- bind_rows(
tun, lps, acute_ccl4, apap,
ph, bdl, chronic_ccl4
) %>%
mutate(contrast = as_factor(contrast))
#> mutate: no changes
saveRDS(combined_contrasts, here(output_path, "limma_result.rds"))Interstudy analysis of acute mouse models
Mutual similarity of differential expressed genes
This analysis computes the similarity of differential expressed genes for specific contrast of the acute mouse models. Similarity is measured by the Jaccard Index.
# select specific contrasts from the acute mouse models
contrast_of_interest <- c(
"treat_vs_ctrl", "inLiver_lps_vs_ctrl",
"ccl_24h_vs_0h", "apap_24h_vs_0h", "ph_0.5d",
"bdl_vs_sham_1d"
)
contrasts <- readRDS(here(output_path, "limma_result.rds")) %>%
filter(contrast %in% contrast_of_interest)
#> filter: removed 630,631 rows (83%), 126,508 rows remaining
# populate gene sets with a fixed size selected by effect size (t-value)
mat_top <- contrasts %>%
group_by(contrast, treatment, source, class) %>%
top_n(500, abs(statistic)) %>%
mutate(key = row_number()) %>%
ungroup() %>%
unite(geneset, class, source, treatment, contrast, sep = "-") %>%
mutate(geneset = as_factor(geneset)) %>%
select(geneset, gene, key) %>%
untdy(key, geneset, gene)
#> group_by: 4 grouping variables (contrast, treatment, source, class)
#> top_n (grouped): removed 123,508 rows (98%), 3,000 rows remaining
#> mutate (grouped): new variable 'key' (integer) with 500 unique values and 0% NA
#> ungroup: no grouping variables
#> mutate: converted 'geneset' from character to factor (0 new NA)
#> select: dropped 5 variables (logFC, statistic, pval, fdr, regulation)
#> select: columns reordered (key, geneset, gene)
#> spread: reorganized (geneset, gene) into (acute-wek-tunicamycin-treat_vs_ctrl, acute-godoy-lps-inLiver_lps_vs_ctrl, acute-godoy-ccl4-ccl_24h_vs_0h, acute-ghallab-apap-apap_24h_vs_0h, acute-godoy-ph-ph_0.5d, …) [was 3000x3, now 500x7]
# usage of jaccard index for balanced set sizes
j <- set_similarity(mat_top, measure = "jaccard", tidy = T)
#> gather: reorganized (acute-wek-tunicamycin-treat_vs_ctrl, acute-godoy-lps-inLiver_lps_vs_ctrl, acute-godoy-ccl4-ccl_24h_vs_0h, acute-ghallab-apap-apap_24h_vs_0h, acute-godoy-ph-ph_0.5d, …) into (set2, similarity) [was 6x7, now 36x3]
#> drop_na: removed 15 rows (42%), 21 rows remaining
#> filter: removed 6 rows (29%), 15 rows remaining
#> mutate_if: converted 'set1' from character to factor (0 new NA)
#> converted 'set2' from character to factor (0 new NA)
#> mutate: changed 0 values (0%) of 'set1' (0 new NA)
j %>%
ggplot(aes(x = set1, y = set2, fill = similarity)) +
geom_tile(color = "black") +
scale_fill_gradient(low = "white", high = aachen_color("green")) +
labs(x = NULL, y = NULL, fill = "Jaccard\nIndex") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
my_theme(fsize = fz, grid = "no")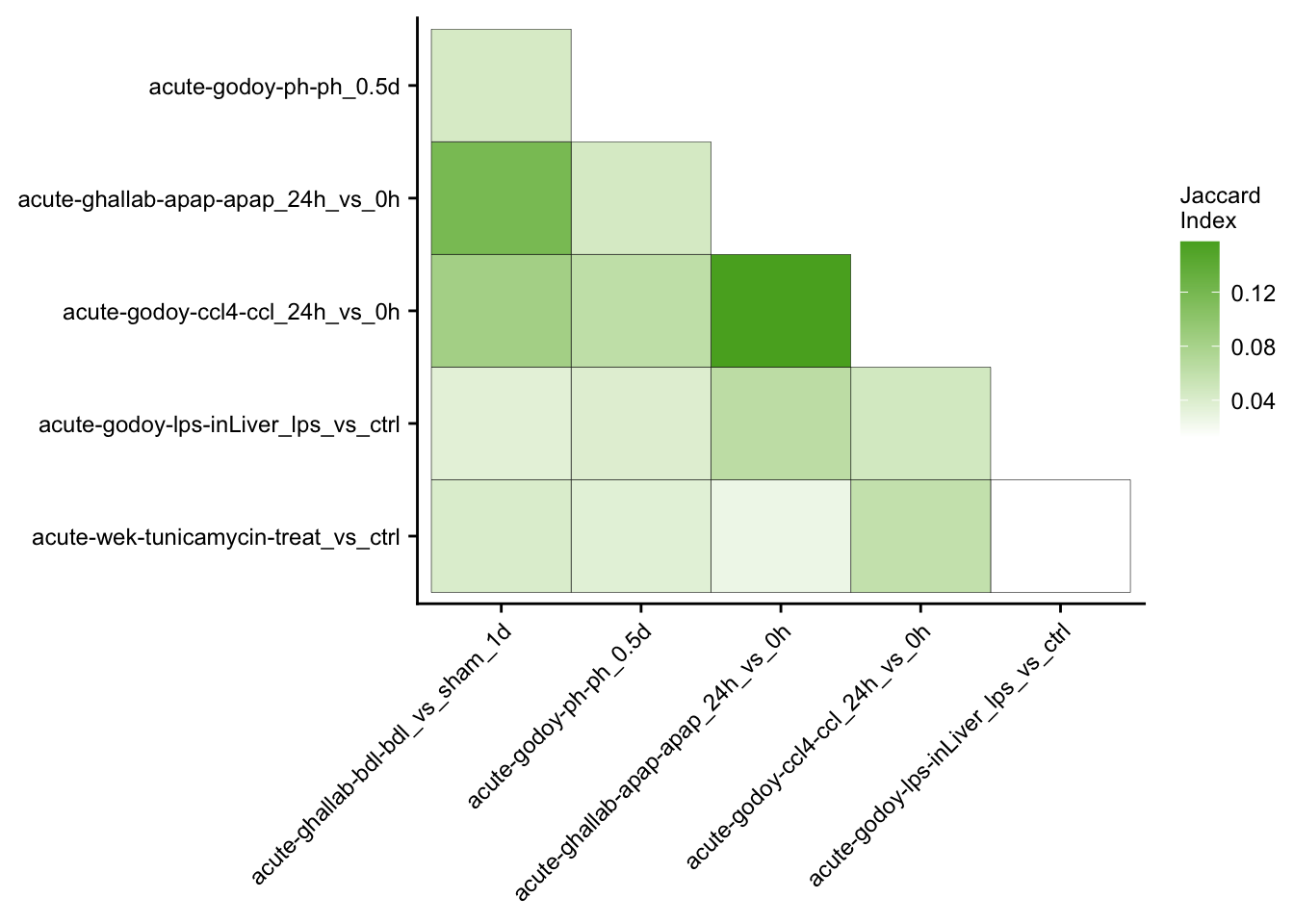
Mutual enrichment of differential expressed genes
This analysis explores whether the top differential expressed genes of specific contrasts of the acute mouse models are consistently regulated across the acute mouse models.
# select specific contrasts from the acute mouse models
contrast_of_interest <- c(
"treat_vs_ctrl", "inLiver_lps_vs_ctrl",
"ccl_24h_vs_0h", "apap_24h_vs_0h", "ph_0.5d",
"bdl_vs_sham_1d"
)
contrasts <- readRDS(here(output_path, "limma_result.rds")) %>%
filter(contrast %in% contrast_of_interest)
#> filter: removed 630,631 rows (83%), 126,508 rows remaining
# populate gene sets with a fixed size selected by effect size (t-value)
genesets_top <- contrasts %>%
mutate(direction = case_when(
sign(statistic) >= 0 ~ "up",
sign(statistic) < 0 ~ "down"
)) %>%
group_by(class, source, treatment, contrast, direction) %>%
top_n(500, abs(statistic)) %>%
ungroup() %>%
unite(geneset, class, source, treatment, contrast, sep = "-") %>%
unite(geneset, geneset, direction, sep = "|") %>%
mutate(geneset = as_factor(geneset)) %>%
select(geneset, gene)
#> mutate: new variable 'direction' (character) with 2 unique values and 0% NA
#> group_by: 5 grouping variables (class, source, treatment, contrast, direction)
#> top_n (grouped): removed 120,508 rows (95%), 6,000 rows remaining
#> ungroup: no grouping variables
#> mutate: converted 'geneset' from character to factor (0 new NA)
#> select: dropped 5 variables (logFC, statistic, pval, fdr, regulation)
# construct signature matrix/data frame
signature_df <- contrasts %>%
unite(signature, class, source, treatment, contrast, sep = "-") %>%
mutate(signature = as_factor(signature)) %>%
untdy("gene", "signature", "statistic")
#> mutate: converted 'signature' from character to factor (0 new NA)
#> select: dropped 4 variables (logFC, pval, fdr, regulation)
#> spread: reorganized (signature, statistic) into (acute-wek-tunicamycin-treat_vs_ctrl, acute-godoy-lps-inLiver_lps_vs_ctrl, acute-godoy-ccl4-ccl_24h_vs_0h, acute-ghallab-apap-apap_24h_vs_0h, acute-godoy-ph-ph_0.5d, …) [was 126508x3, now 26627x7]
# run gsea
set.seed(123)
gsea_res_top <- run_gsea(signature_df, genesets_top, tidy = T) %>%
separate(geneset, into = c("geneset", "direction"), sep = "[|]") %>%
mutate(
signature = as_factor(signature),
geneset = as_factor(geneset)
)
#> group_by: one grouping variable (geneset)
#> summarise: now 12 rows and 2 columns, ungrouped
#> rename: renamed one variable (geneset)
#> select: dropped one variable (gene)
#> distinct: removed 5,988 rows (>99%), 12 rows remaining
#> left_join: added no columns
#> > rows only in x 0
#> > rows only in y ( 0)
#> > matched rows 72
#> > ====
#> > rows total 72
#> mutate: converted 'signature' from character to factor (0 new NA)
#> converted 'geneset' from character to factor (0 new NA)
gsea_res_top %>%
mutate(label = gtools::stars.pval(padj)) %>%
ggplot(aes(x = signature, y = geneset, fill = ES)) +
geom_tile() +
geom_text(aes(label = label)) +
facet_rep_wrap(~direction, scales = "free") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_gradient2() +
my_theme(fsize = fz, grid = "no") +
labs(x = "Signature", y = "Gene set")
#> mutate: new variable 'label' (character) with 3 unique values and 0% NA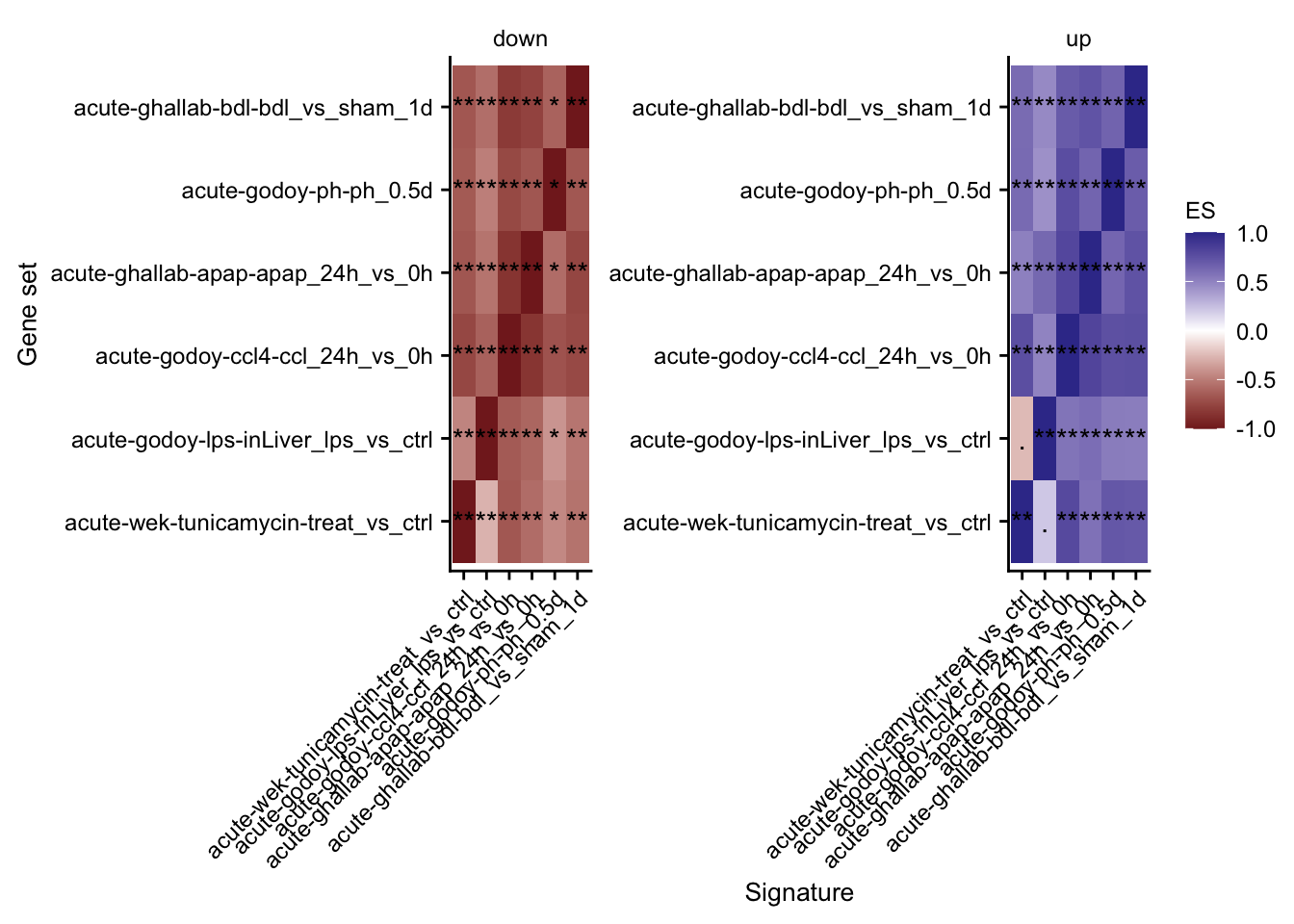
Construction of unified acute and chronic genes
Acute
Pool of differential expressed genes in acute mouse models
Filter for differential expressed genes of the acute mouse model. Visual inspection suggest that the differential expressed genes are consistently regulated across the acute mouse models.
contrasts <- readRDS(here(output_path, "limma_result.rds")) %>%
assign_deg(fdr_cutoff = 1e-4)
#> mutate: converted 'regulation' from factor to character (0 new NA)
#> mutate: converted 'regulation' from character to factor (0 new NA)
acute_gene_pool <- contrasts %>%
filter(class == "acute") %>%
filter(regulation != "ns") %>%
# remove late bdl time point as this could already be a chronic damage
filter(contrast != "bdl_vs_sham_21d")
#> filter: removed 46,014 rows (6%), 711,125 rows remaining
#> filter: removed 701,602 rows (99%), 9,523 rows remaining
#> filter: removed 771 rows (8%), 8,752 rows remaining
acute_gene_pool %>%
mutate(statistic = case_when(
statistic >= 25 ~ 25,
TRUE ~ statistic
)) %>%
ggplot(aes(
x = contrast, y = fct_reorder(gene, statistic, mean),
fill = statistic
)) +
geom_tile() +
scale_fill_gradient2() +
theme(
axis.text.x = element_text(angle = 90),
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
) +
labs(y = "Genes", x = NULL)
#> mutate: changed 28 values (<1%) of 'statistic' (0 new NA)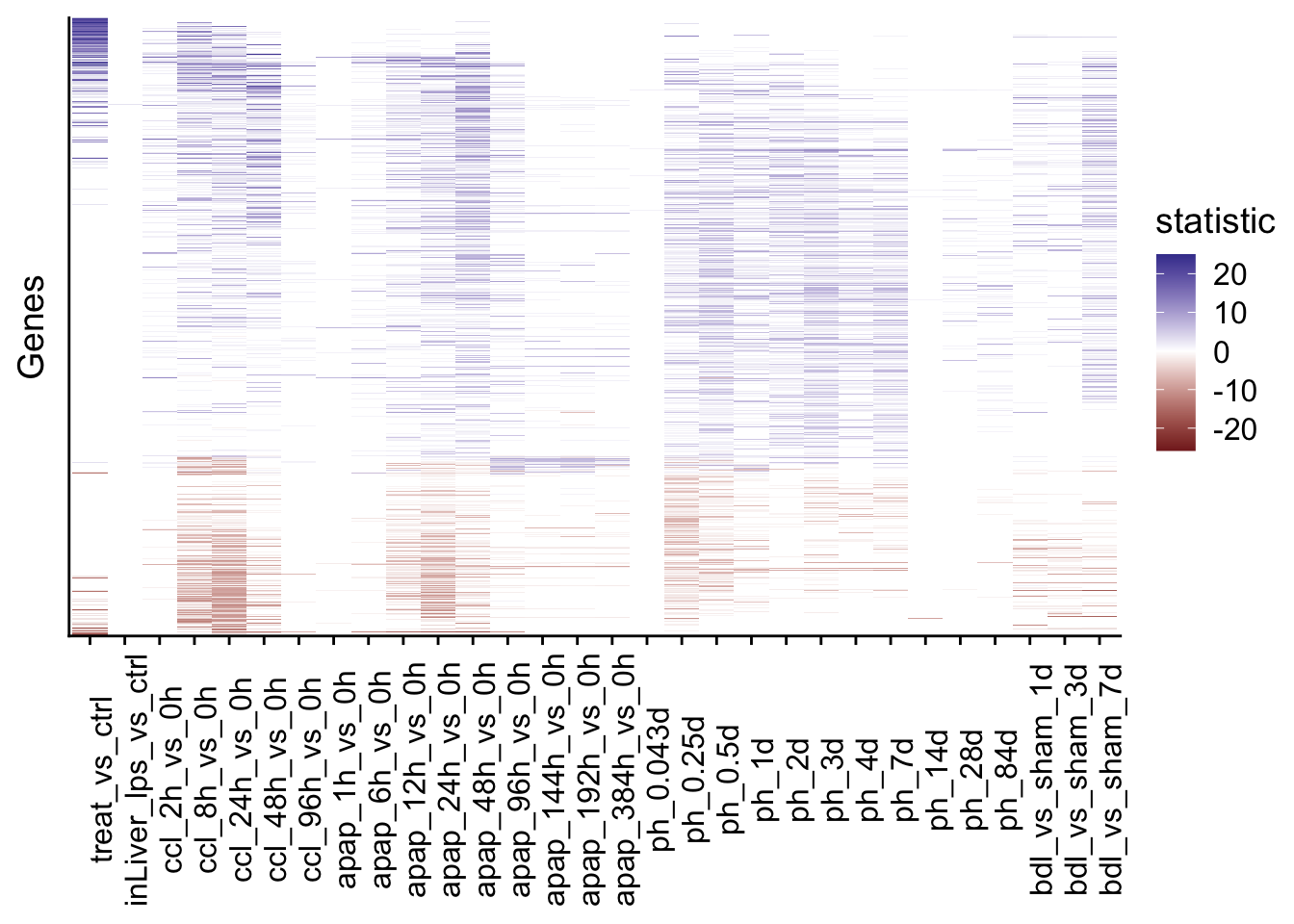
saveRDS(acute_gene_pool, here(output_path, "acute_gene_pool.rds"))Unify acute genes
Acute genes are unified and a median t-statistic is computed for each gene.
acute_gene_pool <- readRDS(here(output_path, "acute_gene_pool.rds"))
acute_gene_union <- acute_gene_pool %>%
group_by(gene) %>%
summarise(
m = mean(sign(statistic)), n = n(),
median_statistic = median(statistic),
median_logFC = median(logFC)
) %>%
distinct(gene, median_statistic, median_logFC)
#> group_by: one grouping variable (gene)
#> summarise: now 3,363 rows and 5 columns, ungrouped
#> distinct: no rows removed
saveRDS(acute_gene_union, here(output_path, "union_acute_geneset.rds"))Chronic
Pool of differential expressed genes in chronic mouse model
Filter for differential expressed genes of the chronic mouse model. Visual inspection suggest that the differential expressed genes are consistently regulated across the chronic contrasts.
contrasts <- readRDS(here(output_path, "limma_result.rds")) %>%
assign_deg(fdr_cutoff = 1e-4)
#> mutate: converted 'regulation' from factor to character (0 new NA)
#> mutate: converted 'regulation' from character to factor (0 new NA)
chronic_gene_pool <- contrasts %>%
filter(class == "chronic") %>%
filter(regulation != "ns")
#> filter: removed 711,125 rows (94%), 46,014 rows remaining
#> filter: removed 44,457 rows (97%), 1,557 rows remaining
chronic_gene_pool %>%
mutate(statistic = case_when(
statistic >= 25 ~ 25,
TRUE ~ statistic
)) %>%
ggplot(aes(
x = contrast, y = fct_reorder(gene, statistic, mean),
fill = statistic
)) +
geom_tile() +
scale_fill_gradient2() +
theme(
axis.text.x = element_text(angle = 90),
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
) +
labs(y = "Genes", x = NULL)
#> mutate: changed one value (<1%) of 'statistic' (0 new NA)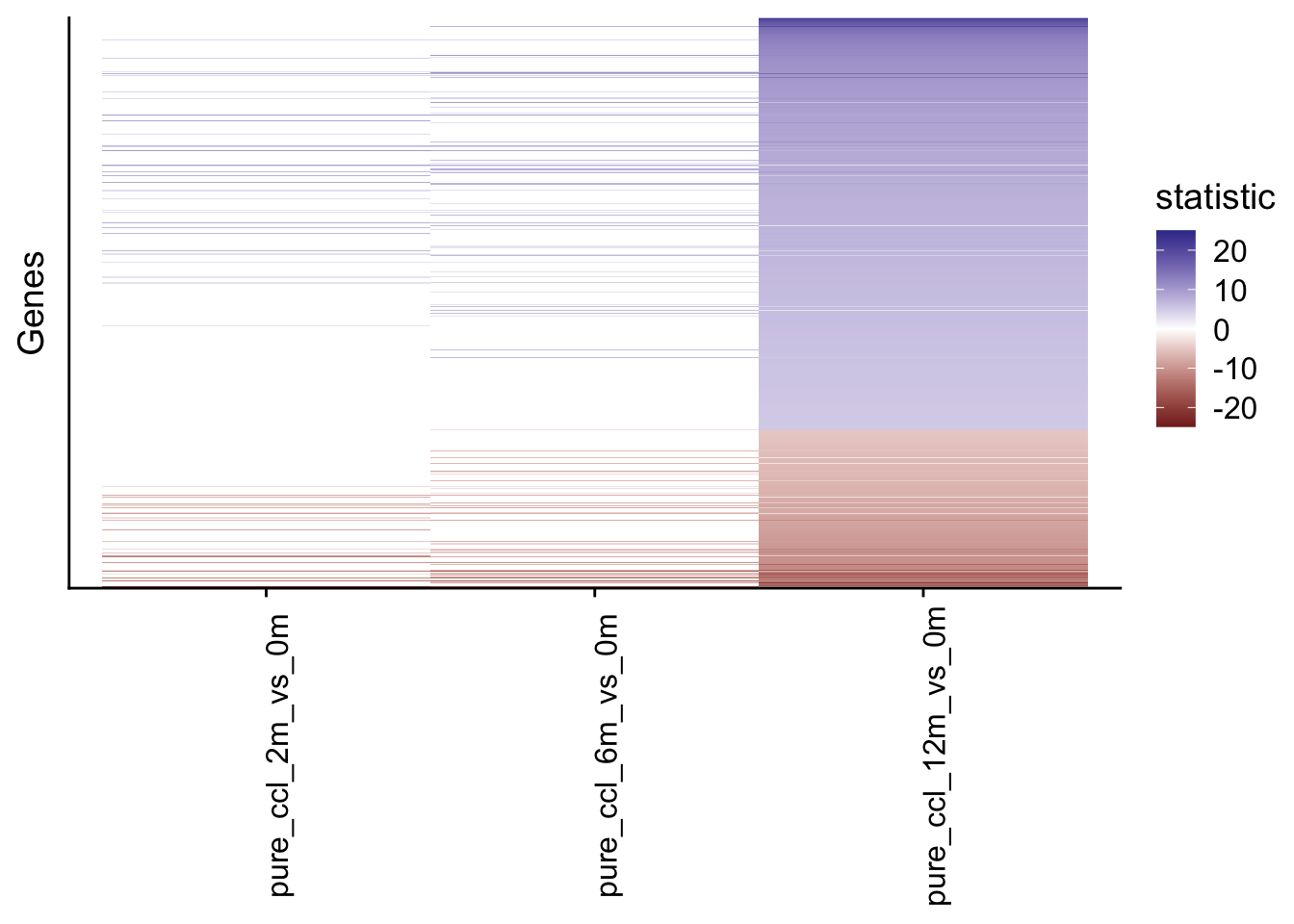
saveRDS(chronic_gene_pool, here(output_path, "chronic_gene_pool.rds"))Unify chronic genes
Chronic genes are unified and a median t-statistic is computed for each gene.
chronic_gene_pool <- readRDS(here(output_path, "chronic_gene_pool.rds"))
chronic_gene_union <- chronic_gene_pool %>%
group_by(gene) %>%
summarise(
m = mean(sign(statistic)), n = n(),
median_statistic = median(statistic),
median_logFC = median(logFC)
) %>%
distinct(gene, median_statistic, median_logFC)
#> group_by: one grouping variable (gene)
#> summarise: now 1,420 rows and 5 columns, ungrouped
#> distinct: no rows removed
saveRDS(chronic_gene_union, here(output_path, "union_chronic_geneset.rds"))Overlap of unified gene sets
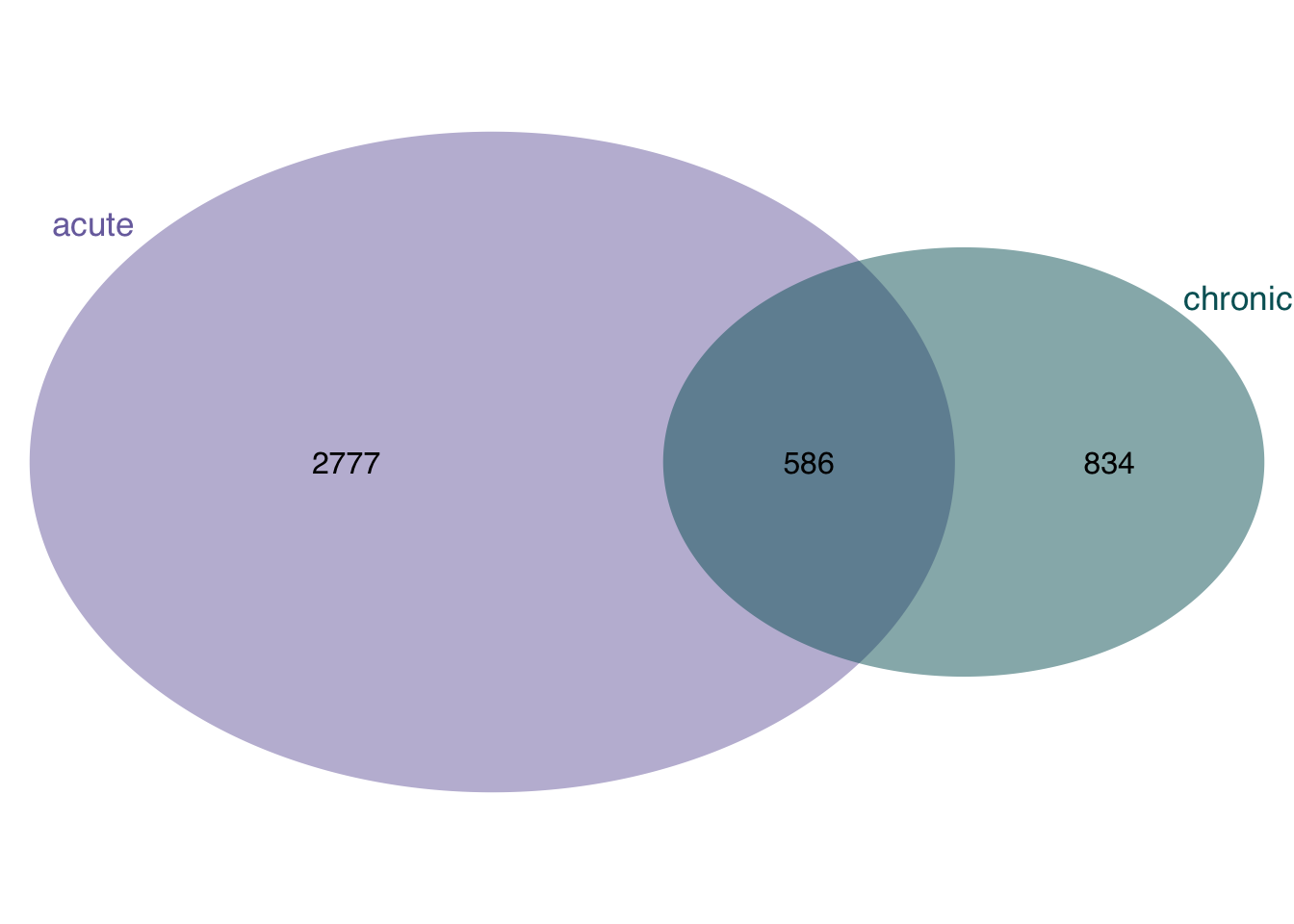
Venn diagram showing the overlap of unified chronic and acute genes.
acute_gene_union <- readRDS(here(output_path, "union_acute_geneset.rds")) %>%
mutate(class = "acute")
#> mutate: new variable 'class' (character) with one unique value and 0% NA
chronic_gene_union <- readRDS(here(output_path, "union_chronic_geneset.rds")) %>%
mutate(class = "chronic")
#> mutate: new variable 'class' (character) with one unique value and 0% NA
a1 <- acute_gene_union %>% nrow()
a2 <- chronic_gene_union %>% nrow()
ca <- intersect(
acute_gene_union %>% pull(gene),
chronic_gene_union %>% pull(gene)
) %>%
length()
v <- draw.pairwise.venn(
area1 = a1, area2 = a2, cross.area = ca,
category = c("acute", "chronic"),
lty = "blank",
cex = 1,
fontfamily = rep("sans", 3),
fill = aachen_color(c("purple", "petrol")),
cat.col = aachen_color(c("purple", "petrol")),
cat.cex = 1.1,
cat.fontfamily = rep("sans", 2)
)
Assign membership to each gene
Genes are assigned a membership: i) exclusive chronic, ii) exclusive acute, iii) common.
acute_gene_union <- readRDS(here(output_path, "union_acute_geneset.rds")) %>%
mutate(class = "acute")
#> mutate: new variable 'class' (character) with one unique value and 0% NA
chronic_gene_union <- readRDS(here(output_path, "union_chronic_geneset.rds")) %>%
mutate(class = "chronic")
#> mutate: new variable 'class' (character) with one unique value and 0% NA
# assign membership to the genes
m <- bind_rows(acute_gene_union, chronic_gene_union) %>%
add_count(gene) %>%
mutate(membership = case_when(
n == 2 ~ "common",
n == 1 & class == "acute" ~ "acute",
n == 1 & class == "chronic" ~ "chronic"
)) %>%
dplyr::select(-n)
#> add_count: new variable 'n' (integer) with 2 unique values and 0% NA
#> mutate: new variable 'membership' (character) with 3 unique values and 0% NA
saveRDS(m, here(output_path, "gene_membership.rds"))Extraction of top exclusive and common genes
For each membership class the the genes are ranked and the top genes are visualized.
Exclusive chronic
Exclusive chronic genes are ranked based on a metric that prioritizes genes that have a high consensus chronic gene-level statistic and at the same time are consistently not deregulated in selected acute contrasts.
exclusive_chronic_genes <- readRDS(here(output_path, "gene_membership.rds")) %>%
filter(membership == "chronic" & class == "chronic") %>%
distinct(gene, chronic_statistic = median_statistic)
#> filter: removed 3,949 rows (83%), 834 rows remaining
#> distinct: no rows removed
contrasts <- readRDS(here(output_path, "limma_result.rds"))
acute_contrasts <- c(
"treat_vs_ctrl",
"inLiver_lps_vs_ctrl",
"ccl_8h_vs_0h", "ccl_24h_vs_0h", "ccl_48h_vs_0h",
"apap_12h_vs_0h", "apap_24h_vs_0h", "apap_48h_vs_0h",
"ph_0.5d", "ph_1d", "ph_2d",
"bdl_vs_sham_1d"
)
df <- contrasts %>%
filter(contrast %in% acute_contrasts) %>%
inner_join(exclusive_chronic_genes, by = "gene") %>%
group_by(gene, chronic_statistic) %>%
summarise(acute_statistic = median(statistic), var = var(statistic), n = n()) %>%
ungroup()
#> filter: removed 507,577 rows (67%), 249,562 rows remaining
#> inner_join: added one column (chronic_statistic)
#> > rows only in x (241,782)
#> > rows only in y ( 127)
#> > matched rows 7,780
#> > =========
#> > rows total 7,780
#> group_by: 2 grouping variables (gene, chronic_statistic)
#> summarise: now 707 rows and 5 columns, one group variable remaining (gene)
#> ungroup: no grouping variables
ranked_exclusive_chronic_genes <- df %>%
# consider only genes that are available in at least in 5 acute contrasts
filter(n >= 5) %>%
# compute empirical metric that maximizes if the chronic statistic is high,
# and the acute statistic and variance is low
mutate(importance = chronic_statistic * (1 / acute_statistic) * sqrt(1 / var)) %>%
arrange(-abs(importance), -chronic_statistic) %>%
mutate(rank = row_number())
#> filter: removed 63 rows (9%), 644 rows remaining
#> mutate: new variable 'importance' (double) with 644 unique values and 0% NA
#> mutate: new variable 'rank' (integer) with 644 unique values and 0% NA
saveRDS(
ranked_exclusive_chronic_genes,
here(output_path, "ranked_exclusive_chronic_genes.rds")
)Extraction of the top 100 exclusive chronic genes. Their expression in acute and chronic mouse models is visualized in a heatmap.
ranked_exclusive_chronic_genes <- readRDS(
here(output_path, "ranked_exclusive_chronic_genes.rds")
)
mat_exclusive_chronic_genes <- ranked_exclusive_chronic_genes %>%
filter(rank <= 100) %>%
left_join(contrasts) %>%
filter(contrast %in% acute_contrasts | treatment == "pure_ccl4") %>%
mutate(gene = as_factor(gene)) %>%
select(gene, contrast, logFC) %>%
untdy("gene", "contrast", "logFC") %>%
as.matrix()
#> filter: removed 544 rows (84%), 100 rows remaining
#> left_join: added 9 columns (contrast, logFC, statistic, pval, fdr, …)
#> > rows only in x 0
#> > rows only in y (753,439)
#> > matched rows 3,700 (includes duplicates)
#> > =========
#> > rows total 3,700
#> filter: removed 2,200 rows (59%), 1,500 rows remaining
#> mutate: converted 'gene' from character to factor (0 new NA)
#> select: dropped 13 variables (chronic_statistic, acute_statistic, var, n, importance, …)
#> select: no changes
#> spread: reorganized (contrast, logFC) into (treat_vs_ctrl, inLiver_lps_vs_ctrl, ccl_8h_vs_0h, ccl_24h_vs_0h, ccl_48h_vs_0h, …) [was 1500x3, now 100x16]
Heatmap(t(mat_exclusive_chronic_genes),
col = col_fun,
cluster_rows = F, cluster_columns = T,
row_names_gp = gpar(fontsize = fz), column_names_gp = gpar(fontsize = fz),
name = "logFC",
row_gap = unit(2.5, "mm"),
border = T,
row_split = c(rep("Acute", 12), rep("Chronic", 3))
)
Common
Common genes are ranked based on a metric that prioritize genes that have a high consensus chronic gene-level statistic and at the same are time consistently regulated in the same direction as in the chronic scenario in selected acute contrasts.
common_genes <- readRDS(here(output_path, "gene_membership.rds")) %>%
filter(membership == "common" & class == "chronic") %>%
distinct(gene, chronic_statistic = median_statistic)
#> filter: removed 4,197 rows (88%), 586 rows remaining
#> distinct: no rows removed
contrasts <- readRDS(here(output_path, "limma_result.rds"))
acute_contrasts <- c(
"treat_vs_ctrl",
"inLiver_lps_vs_ctrl",
"ccl_8h_vs_0h", "ccl_24h_vs_0h", "ccl_48h_vs_0h",
"apap_12h_vs_0h", "apap_24h_vs_0h", "apap_48h_vs_0h",
"ph_0.5d", "ph_1d", "ph_2d",
"bdl_vs_sham_1d"
)
df <- contrasts %>%
filter(contrast %in% acute_contrasts) %>%
inner_join(common_genes, by = "gene") %>%
group_by(gene, chronic_statistic) %>%
summarise(acute_statistic = median(statistic), var = var(statistic), n = n()) %>%
ungroup()
#> filter: removed 507,577 rows (67%), 249,562 rows remaining
#> inner_join: added one column (chronic_statistic)
#> > rows only in x (242,682)
#> > rows only in y ( 0)
#> > matched rows 6,880
#> > =========
#> > rows total 6,880
#> group_by: 2 grouping variables (gene, chronic_statistic)
#> summarise: now 586 rows and 5 columns, one group variable remaining (gene)
#> ungroup: no grouping variables
ranked_common_genes <- df %>%
# consider only genes that are available in at least in 5 acute contrasts
filter(n >= 5) %>%
# compute empirical metric that maximizes if the chronic and acute statistic
# is high and acute variance is low
mutate(importance = chronic_statistic * acute_statistic * sqrt(1 / var)) %>%
arrange(-abs(importance), -chronic_statistic) %>%
mutate(rank = row_number(-importance))
#> filter: removed 13 rows (2%), 573 rows remaining
#> mutate: new variable 'importance' (double) with 573 unique values and 0% NA
#> mutate: new variable 'rank' (integer) with 573 unique values and 0% NA
saveRDS(ranked_common_genes, here(output_path, "ranked_common_genes.rds"))Extraction of the top 100 common genes. Their expression in acute and chronic mouse models is visualized in a heatmap.
ranked_common_genes <- readRDS(
here(output_path, "ranked_common_genes.rds")
)
mat_common_genes <- ranked_common_genes %>%
filter(rank <= 100) %>%
left_join(contrasts) %>%
filter(contrast %in% acute_contrasts | treatment == "pure_ccl4") %>%
mutate(gene = as_factor(gene)) %>%
select(gene, contrast, logFC) %>%
untdy("gene", "contrast", "logFC") %>%
as.matrix()
#> filter: removed 473 rows (83%), 100 rows remaining
#> left_join: added 9 columns (contrast, logFC, statistic, pval, fdr, …)
#> > rows only in x 0
#> > rows only in y (753,447)
#> > matched rows 3,692 (includes duplicates)
#> > =========
#> > rows total 3,692
#> filter: removed 2,194 rows (59%), 1,498 rows remaining
#> mutate: converted 'gene' from character to factor (0 new NA)
#> select: dropped 13 variables (chronic_statistic, acute_statistic, var, n, importance, …)
#> select: no changes
#> spread: reorganized (contrast, logFC) into (treat_vs_ctrl, inLiver_lps_vs_ctrl, ccl_8h_vs_0h, ccl_24h_vs_0h, ccl_48h_vs_0h, …) [was 1498x3, now 100x16]
Heatmap(t(mat_common_genes),
col = col_fun,
cluster_rows = F, cluster_columns = T,
row_names_gp = gpar(fontsize = fz), column_names_gp = gpar(fontsize = fz),
name = "logFC",
row_gap = unit(2.5, "mm"),
border = T,
row_split = c(rep("Acute", 12), rep("Chronic", 3))
)
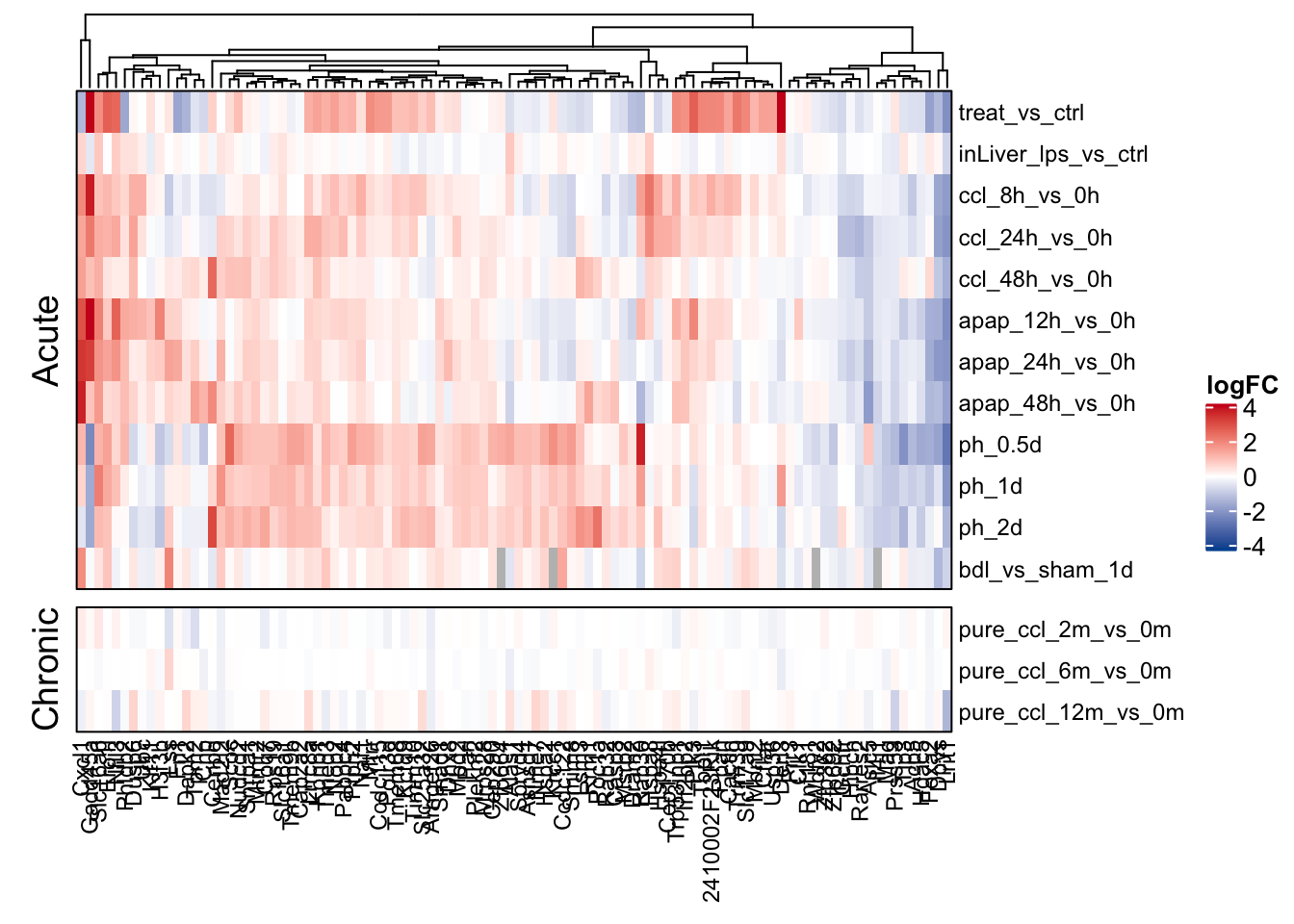
Exclusive acute
Exclusive acute genes are ranked based on a metric that prioritize genes that have a high consensus acute gene-level statistic and at the same time are consistently not deregulated in the chronic contrasts.
exclusive_acute_genes <- readRDS(here(output_path, "gene_membership.rds")) %>%
filter(membership == "acute" & class == "acute") %>%
distinct(gene, acute_statistic = median_statistic)
#> filter: removed 2,006 rows (42%), 2,777 rows remaining
#> distinct: no rows removed
contrasts <- readRDS(here(output_path, "limma_result.rds"))
acute_contrasts <- c(
"treat_vs_ctrl",
"inLiver_lps_vs_ctrl",
"ccl_8h_vs_0h", "ccl_24h_vs_0h", "ccl_48h_vs_0h",
"apap_12h_vs_0h", "apap_24h_vs_0h", "apap_48h_vs_0h",
"ph_0.5d", "ph_1d", "ph_2d",
"bdl_vs_sham_1d"
)
df <- contrasts %>%
filter(treatment == "pure_ccl4") %>%
inner_join(exclusive_acute_genes, by = "gene") %>%
group_by(gene, acute_statistic) %>%
summarise(chronic_statistic = median(statistic), var = var(statistic), n = n()) %>%
ungroup()
#> filter: removed 711,125 rows (94%), 46,014 rows remaining
#> inner_join: added one column (acute_statistic)
#> > rows only in x (38,391)
#> > rows only in y ( 236)
#> > matched rows 7,623
#> > ========
#> > rows total 7,623
#> group_by: 2 grouping variables (gene, acute_statistic)
#> summarise: now 2,541 rows and 5 columns, one group variable remaining (gene)
#> ungroup: no grouping variables
ranked_exclusive_acute_genes <- df %>%
# compute empirical metric that maximizes if the acute statistic is high,
# and the chronic statistic and variance is low
mutate(importance = (1 / chronic_statistic) * acute_statistic * sqrt(1 / var)) %>%
arrange(-abs(importance), -acute_statistic) %>%
mutate(rank = row_number())
#> mutate: new variable 'importance' (double) with 2,541 unique values and 0% NA
#> mutate: new variable 'rank' (integer) with 2,541 unique values and 0% NA
saveRDS(
ranked_exclusive_acute_genes,
here(output_path, "ranked_exclusive_acute_genes.rds")
)Extraction of the top 100 exclusive acute genes. Their expression in acute and chronic mouse models is visualized in a heatmap.
ranked_exclusive_acute_genes <- readRDS(
here(output_path, "ranked_exclusive_acute_genes.rds")
)
mat_exclusive_acute_genes <- ranked_exclusive_acute_genes %>%
filter(rank <= 100) %>%
left_join(contrasts) %>%
filter(contrast %in% acute_contrasts | treatment == "pure_ccl4") %>%
mutate(gene = as_factor(gene)) %>%
select(gene, contrast, logFC) %>%
untdy("gene", "contrast", "logFC") %>%
as.matrix()
#> filter: removed 2,441 rows (96%), 100 rows remaining
#> left_join: added 9 columns (contrast, logFC, statistic, pval, fdr, …)
#> > rows only in x 0
#> > rows only in y (753,455)
#> > matched rows 3,684 (includes duplicates)
#> > =========
#> > rows total 3,684
#> filter: removed 2,188 rows (59%), 1,496 rows remaining
#> mutate: converted 'gene' from character to factor (0 new NA)
#> select: dropped 13 variables (acute_statistic, chronic_statistic, var, n, importance, …)
#> select: no changes
#> spread: reorganized (contrast, logFC) into (treat_vs_ctrl, inLiver_lps_vs_ctrl, ccl_8h_vs_0h, ccl_24h_vs_0h, ccl_48h_vs_0h, …) [was 1496x3, now 100x16]
Heatmap(t(mat_exclusive_acute_genes),
col = col_fun,
cluster_rows = F, cluster_columns = T,
row_names_gp = gpar(fontsize = fz), column_names_gp = gpar(fontsize = fz),
name = "logFC",
row_gap = unit(2.5, "mm"),
border = T,
row_split = c(rep("Acute", 12), rep("Chronic", 3))
)
Characterization of exclusive and common genes
All exclusive chronic, exclusive acute and common genes are characterized GO terms, PROGENy’s pathways and DoRothEA’s TFs. As statistic over-representation analysis is used.
exclusive_chronic_genes <- readRDS(
here(output_path, "ranked_exclusive_chronic_genes.rds")
) %>%
select(gene, statistic = chronic_statistic, rank) %>%
mutate(class = "chronic")
#> select: renamed one variable (statistic) and dropped 4 variables
#> mutate: new variable 'class' (character) with one unique value and 0% NA
exclusive_acute_genes <- readRDS(
here(output_path, "ranked_exclusive_acute_genes.rds")
) %>%
select(gene, statistic = acute_statistic, rank) %>%
mutate(class = "acute")
#> select: renamed one variable (statistic) and dropped 4 variables
#> mutate: new variable 'class' (character) with one unique value and 0% NA
common_genes <- readRDS(here(output_path, "ranked_common_genes.rds")) %>%
filter(sign(chronic_statistic) == sign(acute_statistic)) %>%
select(gene, statistic = chronic_statistic, rank) %>%
mutate(class = "common")
#> filter: removed 93 rows (16%), 480 rows remaining
#> select: renamed one variable (statistic) and dropped 4 variables
#> mutate: new variable 'class' (character) with one unique value and 0% NA
signatures <- bind_rows(
exclusive_chronic_genes, exclusive_acute_genes,
common_genes
) %>%
mutate(regulation = ifelse(statistic >= 0, "up", "down"))
#> mutate: new variable 'regulation' (character) with 2 unique values and 0% NA
# load gene sets of GO terms, pathways, tfs)
genesets <- load_genesets() %>%
filter(confidence %in% c(NA,"A", "B", "C"))
#> filter: removed 2,340,732 rows (80%), 597,560 rows remaining
#> select: renamed one variable (gene) and dropped 2 variables
#> mutate: new variable 'group' (character) with one unique value and 0% NA
#> gather: reorganized (Androgen, EGFR, Estrogen, Hypoxia, JAK-STAT, …) into (geneset, weight) [was 1299x15, now 18186x3]
#> filter: removed 16,785 rows (92%), 1,401 rows remaining
#> select: dropped one variable (weight)
#> mutate: new variable 'group' (character) with one unique value and 0% NA
#> select: renamed 2 variables (geneset, gene) and dropped one variable
#> mutate: new variable 'group' (character) with one unique value and 0% NA
#> filter: removed 396,818 rows (39%), 612,694 rows remaining
# run over-representation analysis
ora_res <- signatures %>%
nest(sig = c(-class, -regulation)) %>%
dplyr::mutate(ora = sig %>% map(run_ora,
sets = genesets, min_size = 10,
options = list(alternative = "greater"),
background_n = 20000
)) %>%
select(-sig) %>%
unnest(ora)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 1,609 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 1,503 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 838 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 1,215 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 990 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 494 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 2,137 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 2,098 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 1,516 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 1,638 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 1,536 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 424 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 1,530 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 1,393 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 956 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> add_count: new variable 'n' (integer) with 643 unique values and 0% NA
#> filter: removed 13,996 rows (2%), 598,698 rows remaining
#> select: dropped one variable (n)
#> mutate: new variable 'contingency_table' (list) with 1,252 unique values and 0% NA
#> mutate: new variable 'stat' (list) with 998 unique values and 0% NA
#> group_by: one grouping variable (group)
#> mutate (grouped): new variable 'fdr' (double) with 544 unique values and 0% NA
#> ungroup: no grouping variables
#> select: dropped 4 variables (set, conf.low, conf.high, method)
#> select: dropped one variable (sig)
saveRDS(ora_res, here(output_path, "exclusive_genes_characterization.rds"))
sessionInfo()
#> R version 4.0.2 (2020-06-22)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Mojave 10.14.5
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] grid stats graphics grDevices datasets utils methods
#> [8] base
#>
#> other attached packages:
#> [1] msigdf_7.1 ComplexHeatmap_2.4.3 VennDiagram_1.6.20
#> [4] futile.logger_1.4.3 lemon_0.4.5 AachenColorPalette_1.1.2
#> [7] circlize_0.4.11 biobroom_1.20.0 broom_0.7.3
#> [10] progeny_1.10.0 dorothea_1.0.1 fgsea_1.14.0
#> [13] here_1.0.1 tidylog_1.0.2 forcats_0.5.0
#> [16] stringr_1.4.0 dplyr_1.0.2 purrr_0.3.4
#> [19] readr_1.4.0 tidyr_1.1.2 tibble_3.0.4
#> [22] ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
#>
#> loaded via a namespace (and not attached):
#> [1] fs_1.5.0 lubridate_1.7.9.2 RColorBrewer_1.1-2
#> [4] httr_1.4.2 rprojroot_2.0.2 tools_4.0.2
#> [7] backports_1.2.1 R6_2.5.0 DBI_1.1.0
#> [10] BiocGenerics_0.34.0 colorspace_2.0-0 GetoptLong_1.0.5
#> [13] withr_2.3.0 tidyselect_1.1.0 gridExtra_2.3
#> [16] compiler_4.0.2 git2r_0.27.1 cli_2.2.0
#> [19] rvest_0.3.6 Biobase_2.48.0 formatR_1.7
#> [22] xml2_1.3.2 labeling_0.4.2 scales_1.1.1
#> [25] digest_0.6.27 rmarkdown_2.6 pkgconfig_2.0.3
#> [28] htmltools_0.5.0 bcellViper_1.24.0 dbplyr_2.0.0
#> [31] rlang_0.4.9 GlobalOptions_0.1.2 readxl_1.3.1
#> [34] rstudioapi_0.13 farver_2.0.3 shape_1.4.5
#> [37] generics_0.1.0 jsonlite_1.7.2 gtools_3.8.2
#> [40] BiocParallel_1.22.0 magrittr_2.0.1 Matrix_1.2-18
#> [43] Rcpp_1.0.5 munsell_0.5.0 fansi_0.4.1
#> [46] lifecycle_0.2.0 stringi_1.5.3 whisker_0.4
#> [49] yaml_2.2.1 plyr_1.8.6 parallel_4.0.2
#> [52] promises_1.1.1 ggrepel_0.9.0 crayon_1.3.4
#> [55] lattice_0.20-41 cowplot_1.1.0 haven_2.3.1
#> [58] hms_0.5.3 knitr_1.30 pillar_1.4.7
#> [61] rjson_0.2.20 codetools_0.2-16 clisymbols_1.2.0
#> [64] futile.options_1.0.1 fastmatch_1.1-0 reprex_0.3.0
#> [67] glue_1.4.2 evaluate_0.14 lambda.r_1.2.4
#> [70] data.table_1.13.4 renv_0.12.3 modelr_0.1.8
#> [73] png_0.1-7 vctrs_0.3.6 httpuv_1.5.4
#> [76] cellranger_1.1.0 gtable_0.3.0 clue_0.3-58
#> [79] assertthat_0.2.1 xfun_0.19 later_1.1.0.1
#> [82] cluster_2.1.0 ellipsis_0.3.1