NPMLE via ebnm
Jason Willwerscheid
4/29/2020
Last updated: 2020-05-08
Checks: 6 0
Knit directory: FLASHvestigations/
This reproducible R Markdown analysis was created with workflowr (version 1.2.0). The Report tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20180714) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: code/.DS_Store
Ignored: code/flashier_bench/.DS_Store
Ignored: data/.DS_Store
Ignored: data/flashier_bench/
Ignored: data/metabo3_gwas_mats.RDS
Ignored: output/jean/
Untracked files:
Untracked: analysis/batting_order.Rmd
Untracked: code/fasfunction.R
Untracked: code/nnmf.R
Untracked: code/wals.R
Untracked: data/BR_teams_2019.csv
Untracked: data/FG_teams_2019.csv
Untracked: data/batting_order.rds
Untracked: data/cole.rds
Untracked: data/odorizzi.rds
Untracked: data/pitcher.rds
Untracked: data/pitcher2.rds
Untracked: data/pitcher_all.rds
Untracked: mlb2.R
Untracked: mlb_standings.txt
Untracked: ottoneu.R
Untracked: phoible.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | ff42bb0 | Jason Willwerscheid | 2020-05-08 | wflow_publish(“analysis/ebnm_npmle.Rmd”) |
| html | 1af4141 | Jason Willwerscheid | 2020-05-08 | Build site. |
| Rmd | 4afebf9 | Jason Willwerscheid | 2020-05-08 | wflow_publish(“analysis/ebnm_npmle.Rmd”) |
| html | 93fda13 | Jason Willwerscheid | 2020-04-29 | Build site. |
| Rmd | 8420f5d | Jason Willwerscheid | 2020-04-29 | wflow_publish(“analysis/ebnm_npmle.Rmd”) |
I want to test out approximations of NPMLEs using a dense ashr grid. Let \(x_1, \ldots, x_n\) be \(n\) observations with standard errors equal to 1. Dicker and Zhao show that when the true NPMLE has compact support, then a good approximation can be obtained by optimizing over the family of distributions that’s supported on \(\sqrt{n}\) equally spaced points between \(\min (x)\) and \(\max (x)\). Instead of using point masses, I use an ashr grid with \(\sqrt{n}\) uniform components of equal width. Let’s see how it works in practice.
Here’s the true distribution which I’ll be sampling from. It’s bimodal with peaks at -5 and 5, so a unimodal prior family wouldn’t work very well.
suppressMessages(library(tidyverse))
true_g <- ashr::normalmix(pi = rep(0.1, 10),
mean = c(rep(-5, 5), rep(5, 5)),
sd = c(0:4, 0:4))
cdf_grid <- seq(-20, 20, by = 0.1)
true_cdf <- drop(ashr::mixcdf(true_g, cdf_grid))
ggplot(tibble(x = cdf_grid, y = true_cdf), aes(x = x, y = y)) + geom_line()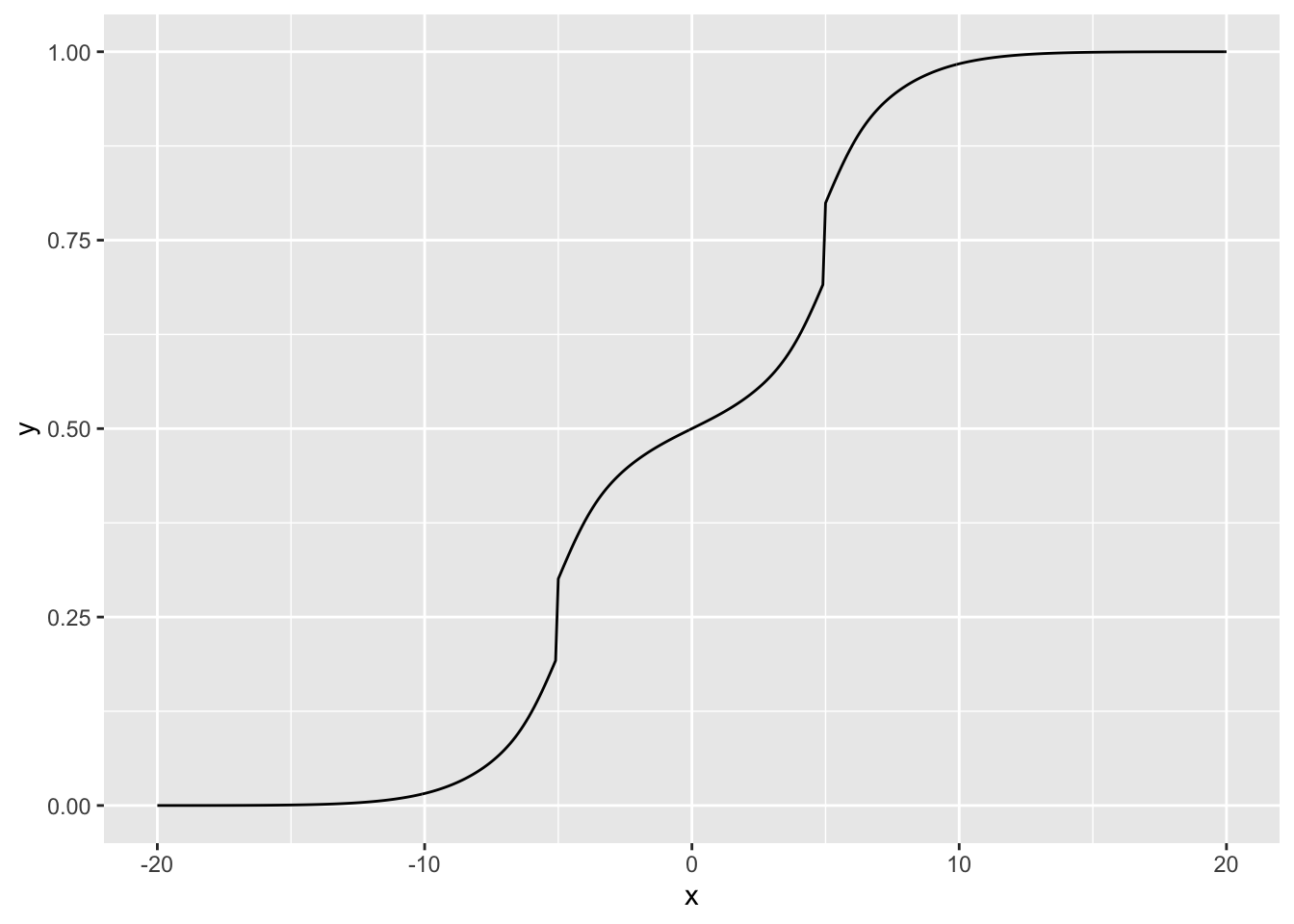
| Version | Author | Date |
|---|---|---|
| 93fda13 | Jason Willwerscheid | 2020-04-29 |
I start by sampling 1000 observations and adding normally distributed noise.
samp_from_g <- function(g, n) {
comp <- sample(1:length(g$pi), n, replace = TRUE, prob = g$pi)
mean <- g$mean[comp]
sd <- g$sd[comp]
return(rnorm(n, mean = mean, sd = sd))
}
set.seed(666)
n <- 1000
samp <- samp_from_g(true_g, n) + rnorm(n)
ggplot(tibble(x = samp), aes(x = x)) + geom_histogram(binwidth = 1)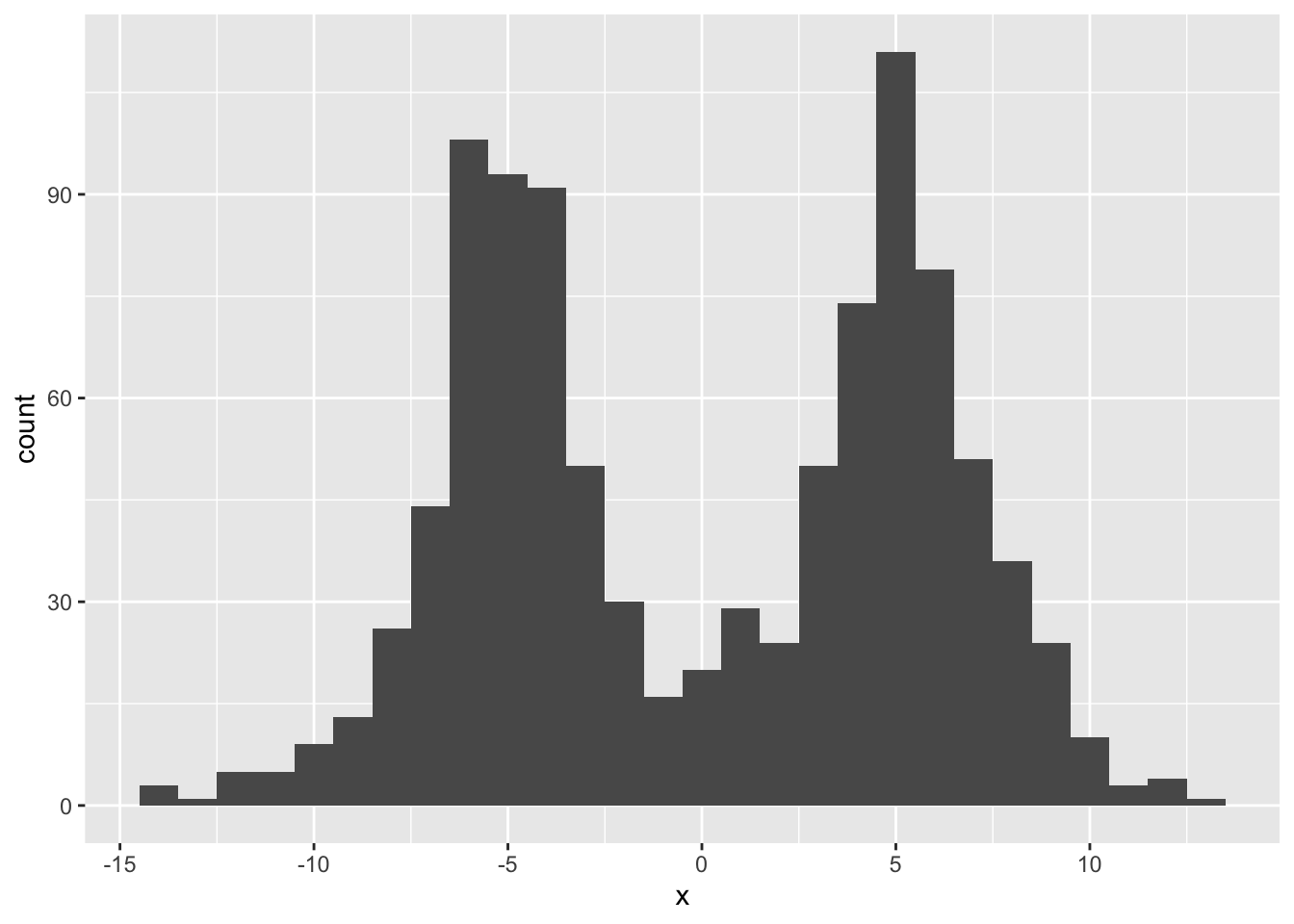
I want to see how grid density affects convergence properties and the quality of the solution. From a log likelihood perspective, using a grid of points spaced at a distance equal to half the standard deviation of the noise gives a solution that is pretty much just as good as a very fine grid:
mixsqp_control = list()
scale_vec <- exp(seq(-2.5, 0, by = 0.5))
res_list <- list()
for (scale in scale_vec) {
ebnm_res <- ebnm::ebnm_npmle(samp, scale = scale, control = mixsqp_control)
res_list <- c(res_list, list(ebnm_res))
}
ggplot(tibble(grid_dens = scale_vec,
llik = sapply(res_list, `[[`, "log_likelihood")),
aes(x = grid_dens, y = llik)) +
geom_point()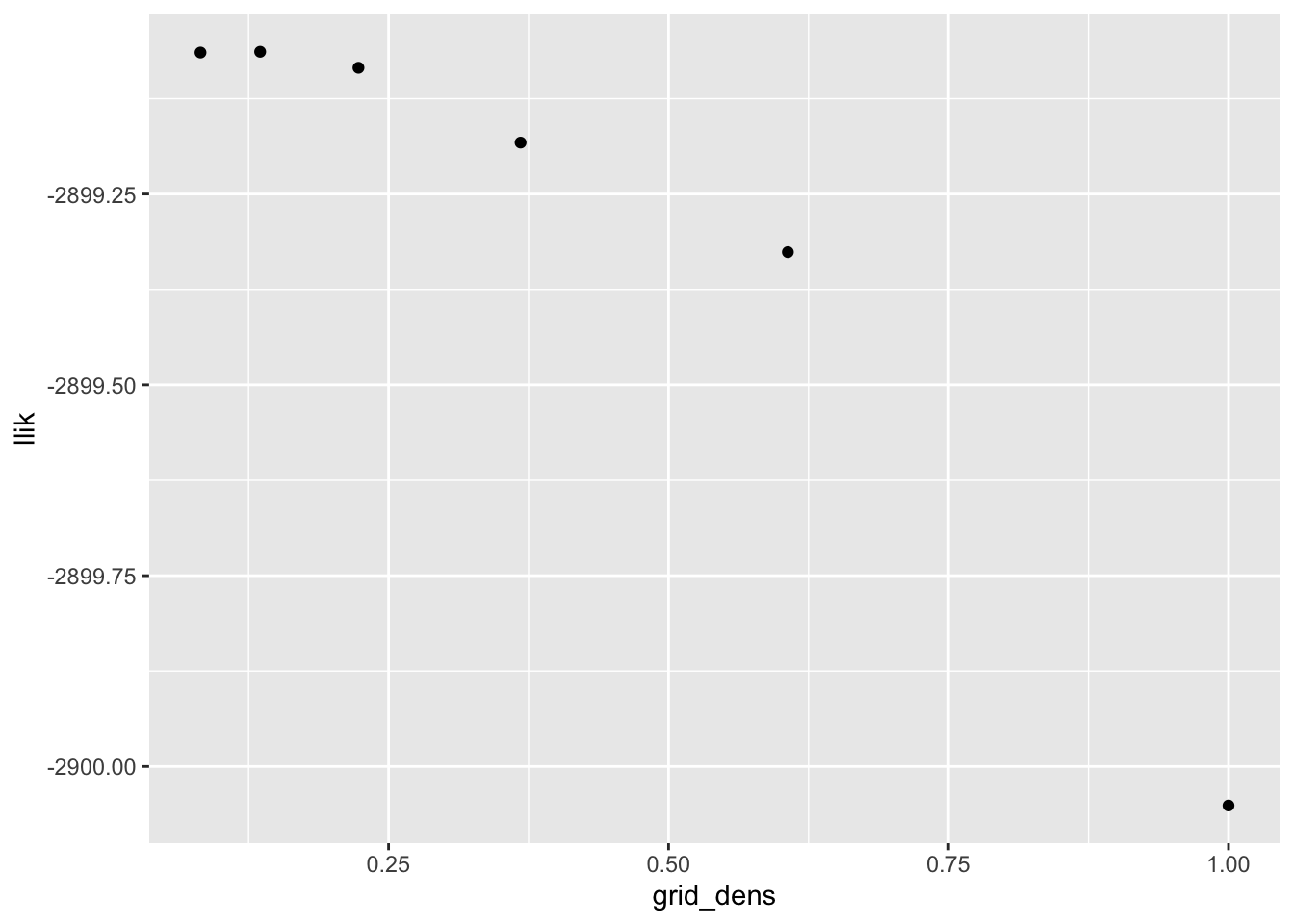
| Version | Author | Date |
|---|---|---|
| 1af4141 | Jason Willwerscheid | 2020-05-08 |
Visually, the CDFs are very similar for all densities less than 0.5 SD:
cdf_df <- tibble(x = rep(cdf_grid, length(res_list)),
y = as.vector(sapply(res_list,
function(res) drop(ashr::mixcdf(res$fitted_g, cdf_grid)))),
grid_dens = as.factor(rep(round(scale_vec, 2), each = length(cdf_grid))))
ggplot(cdf_df, aes(x = x, y = y, col = grid_dens)) +
geom_line()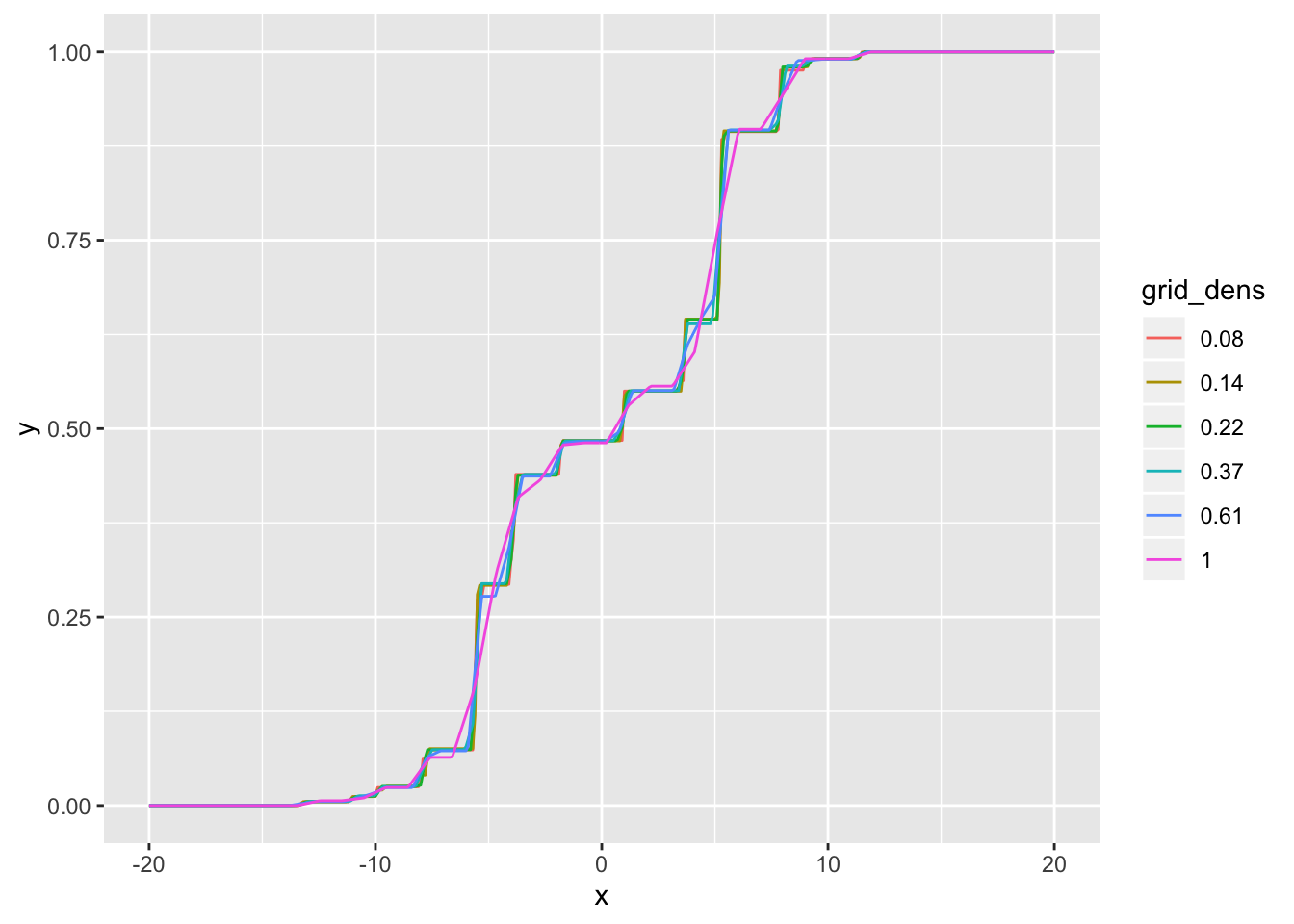
| Version | Author | Date |
|---|---|---|
| 1af4141 | Jason Willwerscheid | 2020-05-08 |
Interestingly, the number of nonzero components is pretty much constant even as the total number of components increases:
cat("Number of components:\n",
rev(sapply(res_list, function(res) length(res$fitted_g$pi))), "\n",
"Number of nonzero components:\n",
rev(sapply(res_list, function(res) sum(res$fitted_g$pi > 0))))#> Number of components:
#> 28 45 75 123 202 333
#> Number of nonzero components:
#> 18 23 22 22 21 21I redo with 10000 observations. The same conclusions still hold, more or less. A good rule of thumb might be to set scale equal to \(\text{SD} / \log_{10} (n)\):
n <- 10000
samp <- samp_from_g(true_g, n) + rnorm(n)
res_list <- list()
for (scale in scale_vec) {
ebnm_res <- ebnm::ebnm_npmle(samp, scale = scale, control = mixsqp_control)
res_list <- c(res_list, list(ebnm_res))
}
ggplot(tibble(grid_dens = scale_vec,
llik = sapply(res_list, `[[`, "log_likelihood")),
aes(x = grid_dens, y = llik)) +
geom_point()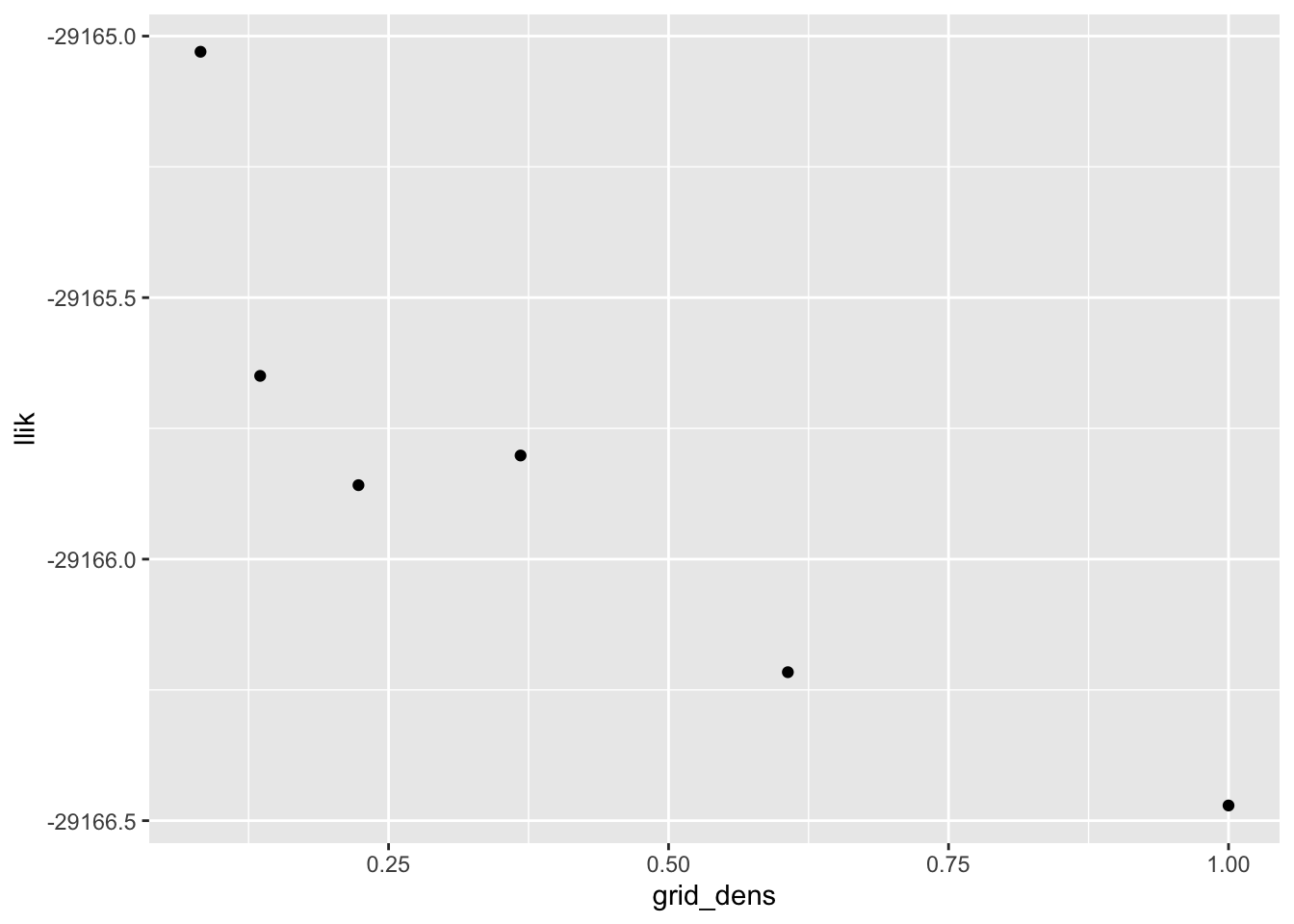
| Version | Author | Date |
|---|---|---|
| 1af4141 | Jason Willwerscheid | 2020-05-08 |
cdf_df <- tibble(x = rep(cdf_grid, length(res_list)),
y = as.vector(sapply(res_list,
function(res) drop(ashr::mixcdf(res$fitted_g, cdf_grid)))),
grid_dens = as.factor(rep(round(scale_vec, 2), each = length(cdf_grid))))
ggplot(cdf_df, aes(x = x, y = y, col = grid_dens)) +
geom_line()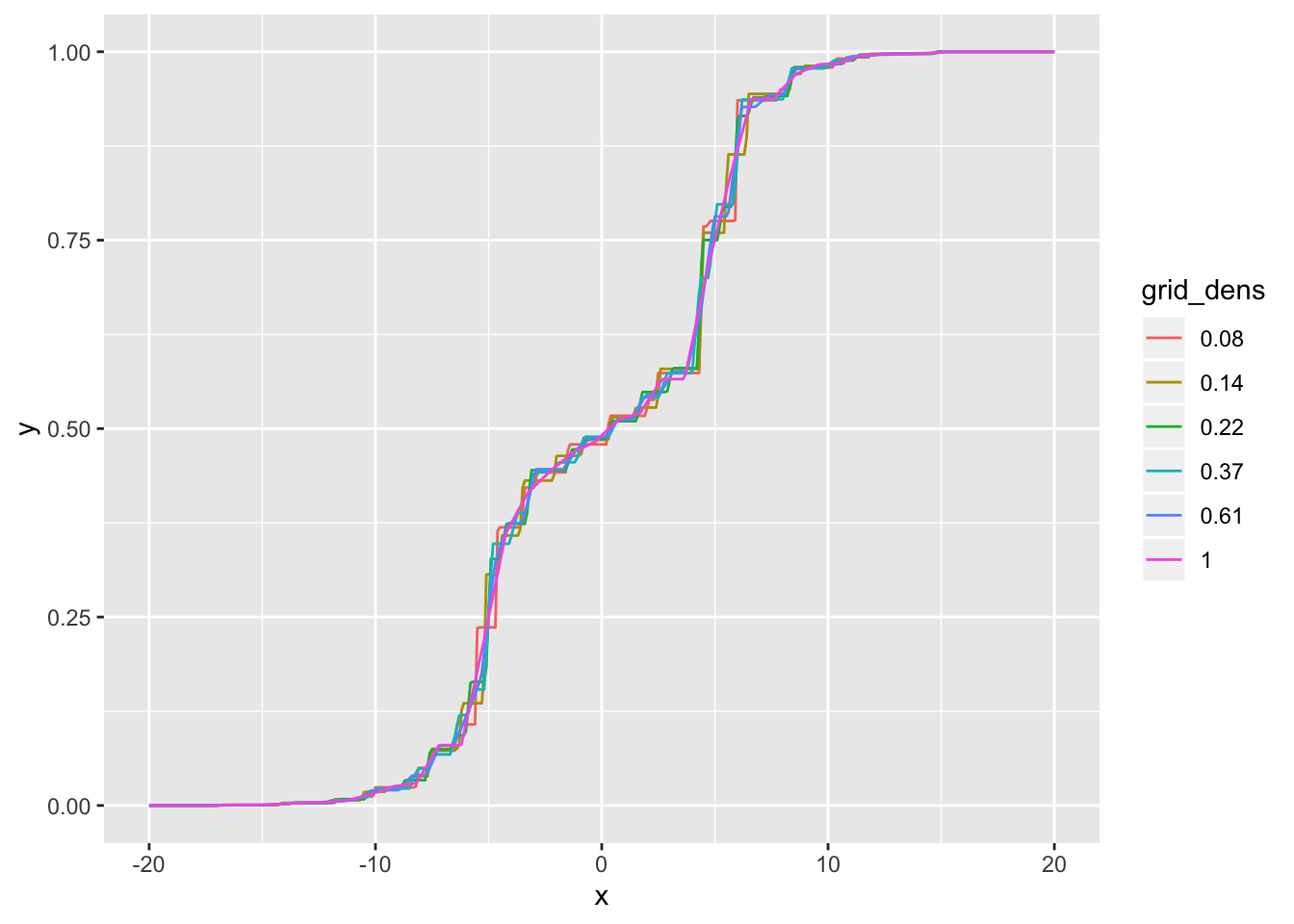
| Version | Author | Date |
|---|---|---|
| 1af4141 | Jason Willwerscheid | 2020-05-08 |
cat("Number of components:\n",
rev(sapply(res_list, function(res) length(res$fitted_g$pi))), "\n",
"Number of nonzero components:\n",
rev(sapply(res_list, function(res) sum(res$fitted_g$pi > 0))))#> Number of components:
#> 35 57 94 155 256 421
#> Number of nonzero components:
#> 28 29 29 28 27 29I include two examples with verbose output for inspection. Compare \(n = 10000\) with scale = 1 / 4:
set.seed(666)
n <- 10000
samp <- samp_from_g(true_g, n) + rnorm(n)
g10000 <- ebnm::ebnm_npmle(samp, scale = 0.25, control = list(verbose = TRUE))#> Running mix-SQP algorithm 0.3-39 on 10000 x 141 matrix
#> convergence tol. (SQP): 1.0e-08
#> conv. tol. (active-set): 1.0e-10
#> zero threshold (solution): 1.0e-08
#> zero thresh. (search dir.): 1.0e-14
#> l.s. sufficient decrease: 1.0e-02
#> step size reduction factor: 7.5e-01
#> minimum step size: 1.0e-08
#> max. iter (SQP): 1000
#> max. iter (active-set): 20
#> number of EM iterations: 20
#> Computing SVD of 10000 x 141 matrix.
#> Matrix is not low-rank; falling back to full matrix.
#> iter objective max(rdual) nnz stepsize max.diff nqp nls
#> 1 +2.021669639e+00 -- EM -- 141 1.00e+00 1.52e-02 -- --
#> 2 +2.003108745e+00 -- EM -- 141 1.00e+00 4.73e-03 -- --
#> 3 +1.999697243e+00 -- EM -- 141 1.00e+00 2.38e-03 -- --
#> 4 +1.998416351e+00 -- EM -- 141 1.00e+00 1.49e-03 -- --
#> 5 +1.997724431e+00 -- EM -- 141 1.00e+00 1.07e-03 -- --
#> 6 +1.997291274e+00 -- EM -- 141 1.00e+00 8.47e-04 -- --
#> 7 +1.997001201e+00 -- EM -- 141 1.00e+00 7.05e-04 -- --
#> 8 +1.996798354e+00 -- EM -- 141 1.00e+00 6.04e-04 -- --
#> 9 +1.996651348e+00 -- EM -- 141 1.00e+00 5.27e-04 -- --
#> 10 +1.996541268e+00 -- EM -- 141 1.00e+00 4.66e-04 -- --
#> 11 +1.996456255e+00 -- EM -- 141 1.00e+00 4.17e-04 -- --
#> 12 +1.996388659e+00 -- EM -- 141 1.00e+00 3.76e-04 -- --
#> 13 +1.996333437e+00 -- EM -- 141 1.00e+00 3.42e-04 -- --
#> 14 +1.996287192e+00 -- EM -- 141 1.00e+00 3.13e-04 -- --
#> 15 +1.996247599e+00 -- EM -- 141 1.00e+00 2.88e-04 -- --
#> 16 +1.996213038e+00 -- EM -- 141 1.00e+00 2.67e-04 -- --
#> 17 +1.996182366e+00 -- EM -- 141 1.00e+00 2.49e-04 -- --
#> 18 +1.996154761e+00 -- EM -- 141 1.00e+00 2.33e-04 -- --
#> 19 +1.996129627e+00 -- EM -- 141 1.00e+00 2.20e-04 -- --
#> 20 +1.996106521e+00 -- EM -- 141 1.00e+00 2.08e-04 -- --
#> 1 +1.996085115e+00 +2.593e-02 141 ------ ------ -- --
#> 2 +1.996065053e+00 +2.524e-02 121 1.00e+00 1.15e-03 20 1
#> 3 +1.996046287e+00 +2.414e-02 101 1.00e+00 8.55e-03 20 1
#> 4 +1.996028650e+00 +2.262e-02 81 1.00e+00 2.53e-02 20 1
#> 5 +1.996011918e+00 +2.092e-02 61 1.00e+00 3.00e-02 20 1
#> 6 +1.995978643e+00 +1.922e-02 41 1.00e+00 1.20e-01 20 1
#> 7 +1.995479254e+00 +3.028e-03 26 1.00e+00 4.68e-02 20 1
#> 8 +1.995453336e+00 +5.102e-04 27 1.00e+00 6.01e-03 20 1
#> 9 +1.995425984e+00 +1.469e-06 27 1.00e+00 5.12e-02 20 1
#> 10 +1.995412578e+00 -8.542e-07 30 1.00e+00 1.03e-01 20 1
#> Optimization took 1.72 seconds.
#> Convergence criteria met---optimal solution found.and \(n = 100000\) with scale = 1 / 5:
set.seed(666)
n <- 100000
samp <- samp_from_g(true_g, n) + rnorm(n)
g100000 <- ebnm::ebnm_npmle(samp, scale = 0.2, control = list(verbose = TRUE))#> Running mix-SQP algorithm 0.3-39 on 100000 x 206 matrix
#> convergence tol. (SQP): 1.0e-08
#> conv. tol. (active-set): 1.0e-10
#> zero threshold (solution): 1.0e-08
#> zero thresh. (search dir.): 1.0e-14
#> l.s. sufficient decrease: 1.0e-02
#> step size reduction factor: 7.5e-01
#> minimum step size: 1.0e-08
#> max. iter (SQP): 1000
#> max. iter (active-set): 20
#> number of EM iterations: 20
#> Computing SVD of 100000 x 206 matrix.
#> Matrix is not low-rank; falling back to full matrix.
#> iter objective max(rdual) nnz stepsize max.diff nqp nls
#> 1 +2.027223557e+00 -- EM -- 206 1.00e+00 1.32e-02 -- --
#> 2 +2.008410910e+00 -- EM -- 206 1.00e+00 3.89e-03 -- --
#> 3 +2.004864385e+00 -- EM -- 206 1.00e+00 1.97e-03 -- --
#> 4 +2.003493379e+00 -- EM -- 206 1.00e+00 1.23e-03 -- --
#> 5 +2.002746710e+00 -- EM -- 206 1.00e+00 8.83e-04 -- --
#> 6 +2.002283415e+00 -- EM -- 206 1.00e+00 6.85e-04 -- --
#> 7 +2.001978999e+00 -- EM -- 206 1.00e+00 5.58e-04 -- --
#> 8 +2.001771577e+00 -- EM -- 206 1.00e+00 4.68e-04 -- --
#> 9 +2.001625879e+00 -- EM -- 206 1.00e+00 4.00e-04 -- --
#> 10 +2.001520556e+00 -- EM -- 206 1.00e+00 3.46e-04 -- --
#> 11 +2.001442247e+00 -- EM -- 206 1.00e+00 3.04e-04 -- --
#> 12 +2.001382396e+00 -- EM -- 206 1.00e+00 2.69e-04 -- --
#> 13 +2.001335418e+00 -- EM -- 206 1.00e+00 2.41e-04 -- --
#> 14 +2.001297602e+00 -- EM -- 206 1.00e+00 2.18e-04 -- --
#> 15 +2.001266443e+00 -- EM -- 206 1.00e+00 1.98e-04 -- --
#> 16 +2.001240223e+00 -- EM -- 206 1.00e+00 1.82e-04 -- --
#> 17 +2.001217743e+00 -- EM -- 206 1.00e+00 1.68e-04 -- --
#> 18 +2.001198156e+00 -- EM -- 206 1.00e+00 1.56e-04 -- --
#> 19 +2.001180852e+00 -- EM -- 206 1.00e+00 1.46e-04 -- --
#> 20 +2.001165386e+00 -- EM -- 205 1.00e+00 1.37e-04 -- --
#> 1 +2.001151433e+00 +1.545e-02 205 ------ ------ -- --
#> 2 +2.001138745e+00 +1.456e-02 185 1.00e+00 1.27e-04 20 1
#> 3 +2.001127136e+00 +1.372e-02 165 1.00e+00 3.26e-04 20 1
#> 4 +2.001116433e+00 +1.293e-02 145 1.00e+00 1.30e-03 20 1
#> 5 +2.001106483e+00 +1.290e-02 125 1.00e+00 6.38e-03 20 1
#> 6 +2.001097281e+00 +1.310e-02 105 1.00e+00 1.31e-02 20 1
#> 7 +2.001088677e+00 +1.310e-02 85 1.00e+00 1.52e-02 20 1
#> 8 +2.001080384e+00 +1.230e-02 65 1.00e+00 3.06e-02 20 1
#> 9 +2.001057776e+00 +4.822e-03 45 1.00e+00 8.57e-02 20 1
#> 10 +2.000856234e+00 +1.105e-04 34 1.00e+00 4.51e-02 20 1
#> 11 +2.000856230e+00 -5.901e-06 34 1.00e+00 1.31e-03 20 1
#> Optimization took 33.35 seconds.
#> Convergence criteria met---optimal solution found.
sessionInfo()#> R version 3.5.3 (2019-03-11)
#> Platform: x86_64-apple-darwin15.6.0 (64-bit)
#> Running under: macOS Mojave 10.14.6
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] forcats_0.4.0 stringr_1.4.0 dplyr_0.8.0.1 purrr_0.3.2
#> [5] readr_1.3.1 tidyr_0.8.3 tibble_2.1.1 ggplot2_3.2.0
#> [9] tidyverse_1.2.1
#>
#> loaded via a namespace (and not attached):
#> [1] tidyselect_0.2.5 xfun_0.6 ashr_2.2-50
#> [4] haven_2.1.1 lattice_0.20-38 colorspace_1.4-1
#> [7] generics_0.0.2 htmltools_0.3.6 yaml_2.2.0
#> [10] rlang_0.4.2 mixsqp_0.3-39 pillar_1.3.1
#> [13] glue_1.3.1 withr_2.1.2 modelr_0.1.5
#> [16] readxl_1.3.1 munsell_0.5.0 gtable_0.3.0
#> [19] workflowr_1.2.0 cellranger_1.1.0 rvest_0.3.4
#> [22] evaluate_0.13 labeling_0.3 knitr_1.22
#> [25] invgamma_1.1 irlba_2.3.3 broom_0.5.1
#> [28] Rcpp_1.0.1 scales_1.0.0 backports_1.1.3
#> [31] jsonlite_1.6 truncnorm_1.0-8 fs_1.2.7
#> [34] hms_0.4.2 digest_0.6.18 stringi_1.4.3
#> [37] ebnm_0.1-21 grid_3.5.3 rprojroot_1.3-2
#> [40] cli_1.1.0 tools_3.5.3 magrittr_1.5
#> [43] lazyeval_0.2.2 crayon_1.3.4 whisker_0.3-2
#> [46] pkgconfig_2.0.2 Matrix_1.2-15 SQUAREM_2017.10-1
#> [49] xml2_1.2.0 lubridate_1.7.4 assertthat_0.2.1
#> [52] rmarkdown_1.12 httr_1.4.0 rstudioapi_0.10
#> [55] R6_2.4.0 nlme_3.1-137 git2r_0.25.2
#> [58] compiler_3.5.3