Species data
Eva-Carmen Calin
20 December 2023
Last updated: 2023-12-20
Checks: 7 0
Knit directory: WP1/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210216) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 2d40e16. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: .httr-oauth
Ignored: code/.Rhistory
Ignored: data/analyses/clean_all.RData
Ignored: data/analyses/clean_all_clean.RData
Ignored: data/analyses/ice_4km_proc.RData
Ignored: data/full_data/
Ignored: data/sst_trom.RData
Ignored: metadata/globalfishingwatch_API_key.RData
Ignored: metadata/is_gfw_database.RData
Ignored: metadata/pangaea_parameters.tab
Ignored: metadata/pg_EU_ref_meta.csv
Ignored: mhw-definition_1_orig.xcf
Ignored: poster/SSC_2021_landscape_files/paged-0.15/
Ignored: presentations/.Rhistory
Ignored: presentations/2023_Ilico.html
Ignored: presentations/2023_LOV.html
Ignored: presentations/2023_results_day.html
Ignored: presentations/2023_seminar.html
Ignored: presentations/2023_summary.html
Ignored: presentations/ASSW_2023.html
Ignored: presentations/ASSW_side_2023.html
Ignored: presentations/Session5_SCHLEGEL.html
Ignored: shiny/dataAccess/coastline_hi_sub.csv
Ignored: shiny/kongCTD/.httr-oauth
Ignored: shiny/kongCTD/credentials.RData
Ignored: shiny/kongCTD/data/
Ignored: shiny/test_data/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/species_data.Rmd) and HTML
(docs/species_data.html) files. If you’ve configured a
remote Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 0926ac4 | Robert William Schlegel | 2023-12-12 | Build site. |
| html | 7ad8a78 | Robert William Schlegel | 2023-12-12 | Build site. |
| html | 77b2a61 | Robert | 2023-12-04 | Build site. |
| html | 610ff35 | Robert | 2023-08-30 | Build site. |
| html | 6ad5b79 | Robert William Schlegel | 2023-08-24 | Build site. |
| html | bd4819b | Robert | 2023-08-23 | Build site. |
| html | 4ddbb12 | robwschlegel | 2023-07-24 | Build site. |
| html | e8997de | Robert | 2023-05-30 | Build site. |
| html | 2ea419c | Robert | 2023-05-30 | Build site. |
| html | 1422923 | Eccalin | 2023-05-22 | Species summary update |
| Rmd | 33161ad | Eccalin | 2023-05-17 | Species summary |
| html | 33161ad | Eccalin | 2023-05-17 | Species summary |
| Rmd | 49a94f6 | Eccalin | 2023-05-17 | Species summary |
| html | 49a94f6 | Eccalin | 2023-05-17 | Species summary |
| Rmd | b336e80 | Eccalin | 2023-05-17 | New species figures |
| Rmd | ad00660 | Eccalin | 2023-05-17 | Summary of species data |
| html | ad00660 | Eccalin | 2023-05-17 | Summary of species data |
| Rmd | 29107e6 | Eccalin | 2023-05-16 | data species |
| html | 29107e6 | Eccalin | 2023-05-16 | data species |
| html | d73422a | Eccalin | 2023-05-16 | Poster |
| html | 73cd309 | Eccalin | 2023-05-12 | Build site. |
| Rmd | cfa3aca | Eccalin | 2023-05-12 | web site test |
| html | cfa3aca | Eccalin | 2023-05-12 | web site test |
| Rmd | 4ce558b | Eccalin | 2023-05-12 | Web site |
| html | 4ce558b | Eccalin | 2023-05-12 | Web site |
Overview
This document outlines the process of collecting, amalgamating, and
analyzing species presence data from the FACE-IT Arctic Fjords study
sites.
Methods
Determine which data is needed
To meet the requirements of the FACE-IT project, the data must meet
certain criteria. The data must be from one of the seven study sites of
the project, in Svalbard, Greenland or Norway. Data must include species
biomass (presence data will also be collected). The data must concern
marine species such as birds, fish, mammals, zooplankton or
phytoplankton.
Searching for sources
To ensure data quality, it is essential to have reliable sources. For
this, research and academic sites were used, in particular those of
MOSJ, GEM, NPI.
Data collection and identification
Once the sources are found, it is important to collect the datasets
that can be used for the project. Sometimes it is necessary to log in to
certain websites to access the data. In order to use this data to its
highest potential, it is important to determine what useful and
necessary information in each dataset should be preserved. Careful
consideration must be given to each set to ensure the quality of the
information.
Modeling the sets
The data collected will be added to the ones already present on the FACE-IT project, they will have to follow the same format and respect the order by filling the following columns:
the date of access to the data,
the URL where to find the set,
the citation,
the type of data,
the site (kong, nuup, svalbard, is, disko, …),
the category (bio, cryo, social, …),
the driver (category details.) ),
the variable,
the longitude of each data,
the latitude of each data,
the date of collection of the data,
the depth of water of each data,
the value
Variable naming
All the variables follow a precise naming system. This allows to save their main information. For each variable we find:

Species type code
For an easier use, the different species studied have been divided in several categories each distinguished by a three letters code: Birds, Poisons |FIS|, Marine mammal |MAM|, Zooplankton |ZOO| and Phytoplankton |PHY|.
For the birds, subcategories have been added. The goal of the project being the study of marine species and the data collected concerning different types of birds. A distinction was made between marine birds |SBI|, land birds (non marine) |NBI| and species not yet sorted |BIR|.
Assembling the sets
Once the data are formatted, they are combined by geographic area, saved and added to the website.
Analyze the sets
Once the sets are complete, an analysis of the data recovered can be
made. This allows us to see the information collected and to highlight
certain patterns.
Svalbard

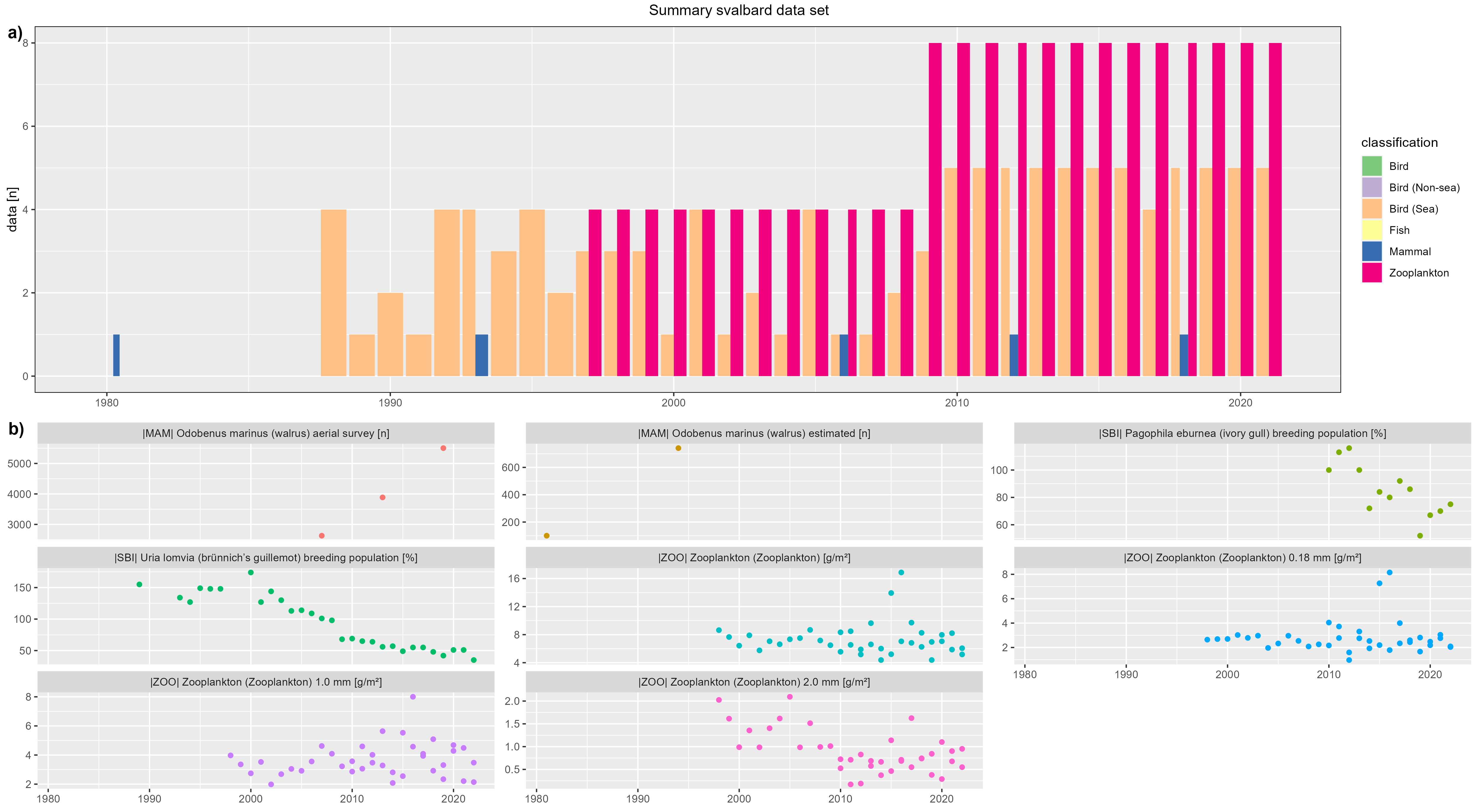
figure 1 - a) Svalbard data count by year, b) Svalbard species biomass over year
Kongsfjorden

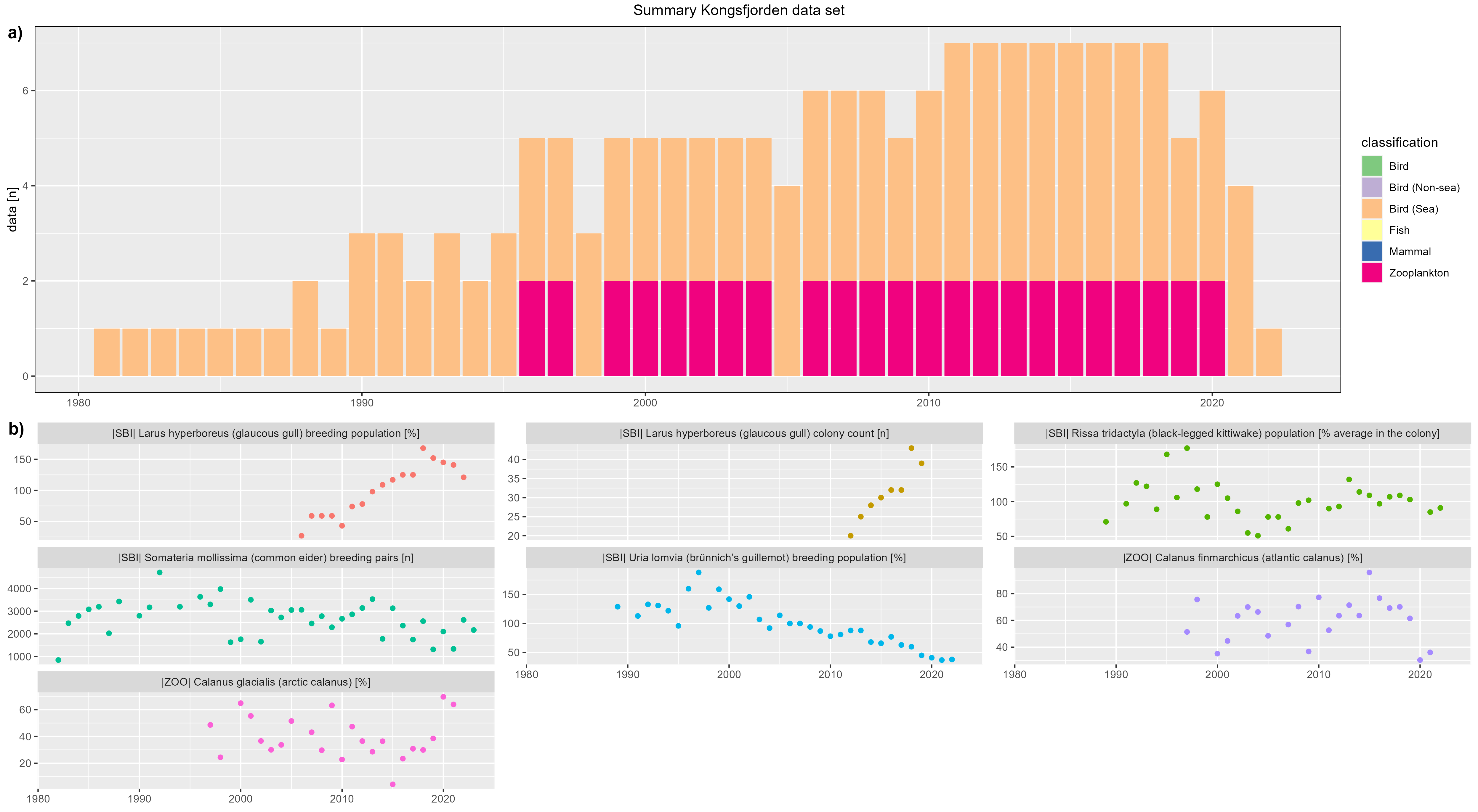
figure 2 - a) Kongsfjorden data count by year, b) Kongsfjorden species biomass over year
Isfjorden

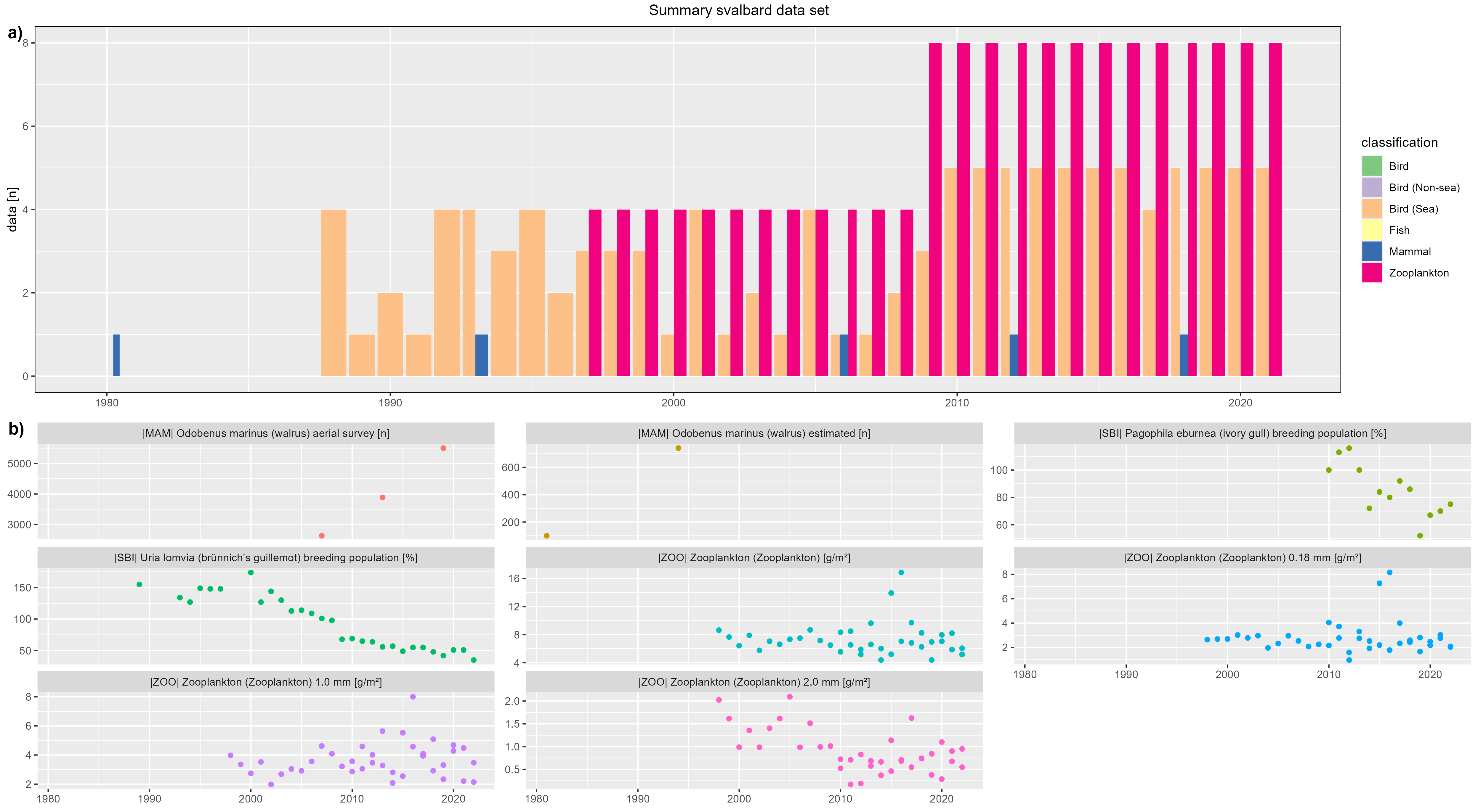
figure 3 - a) Isfjorden data count by year, b) Isfjorden species biomass over year
Barents sea

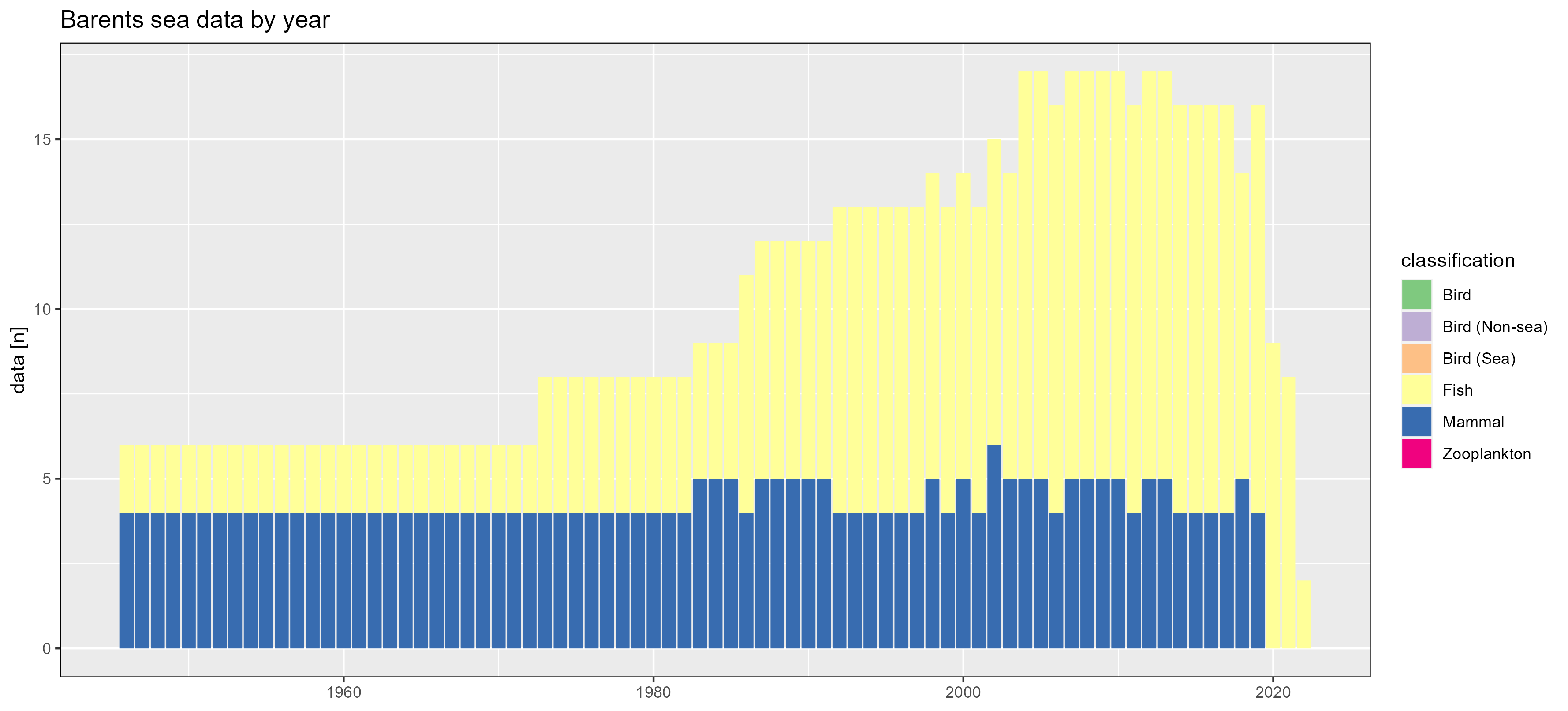
Greenland
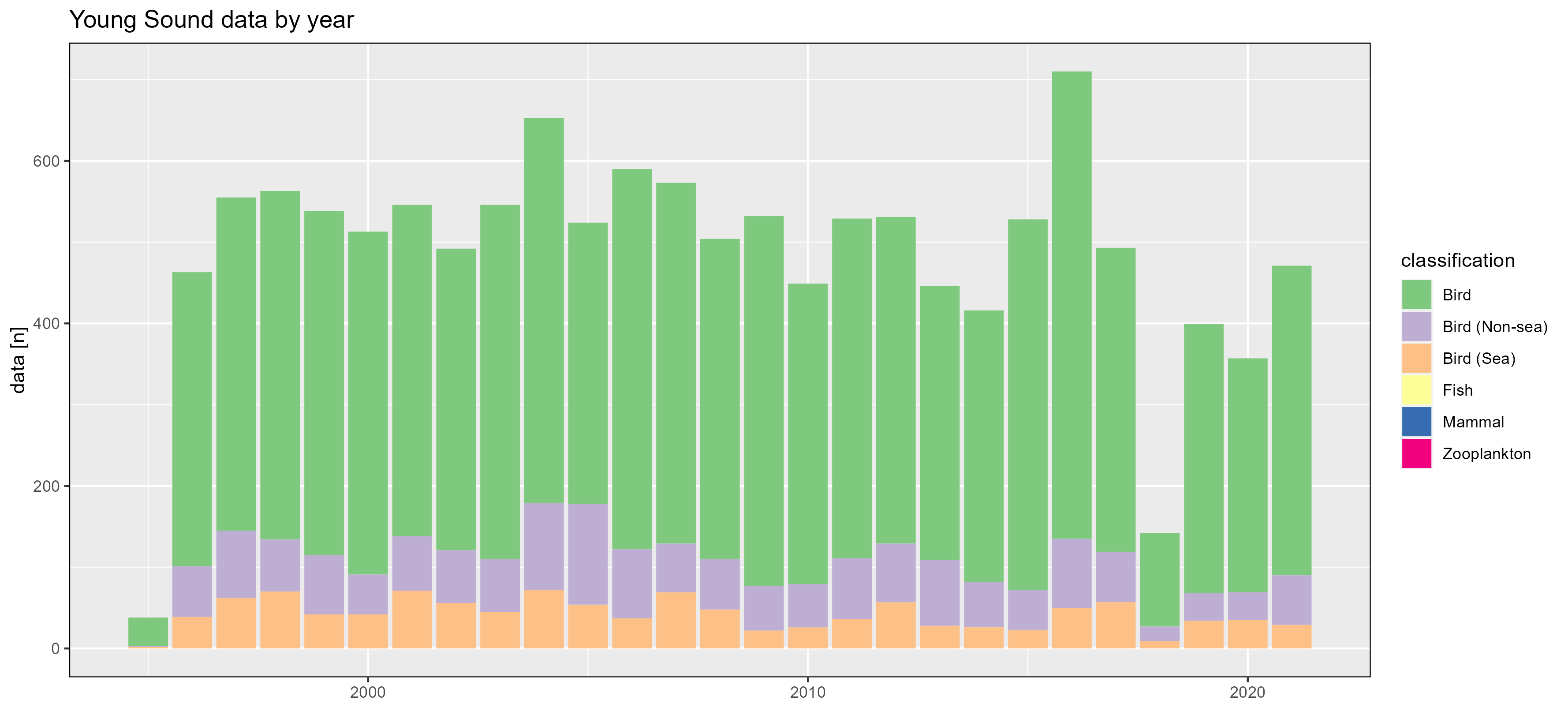
Young Sound

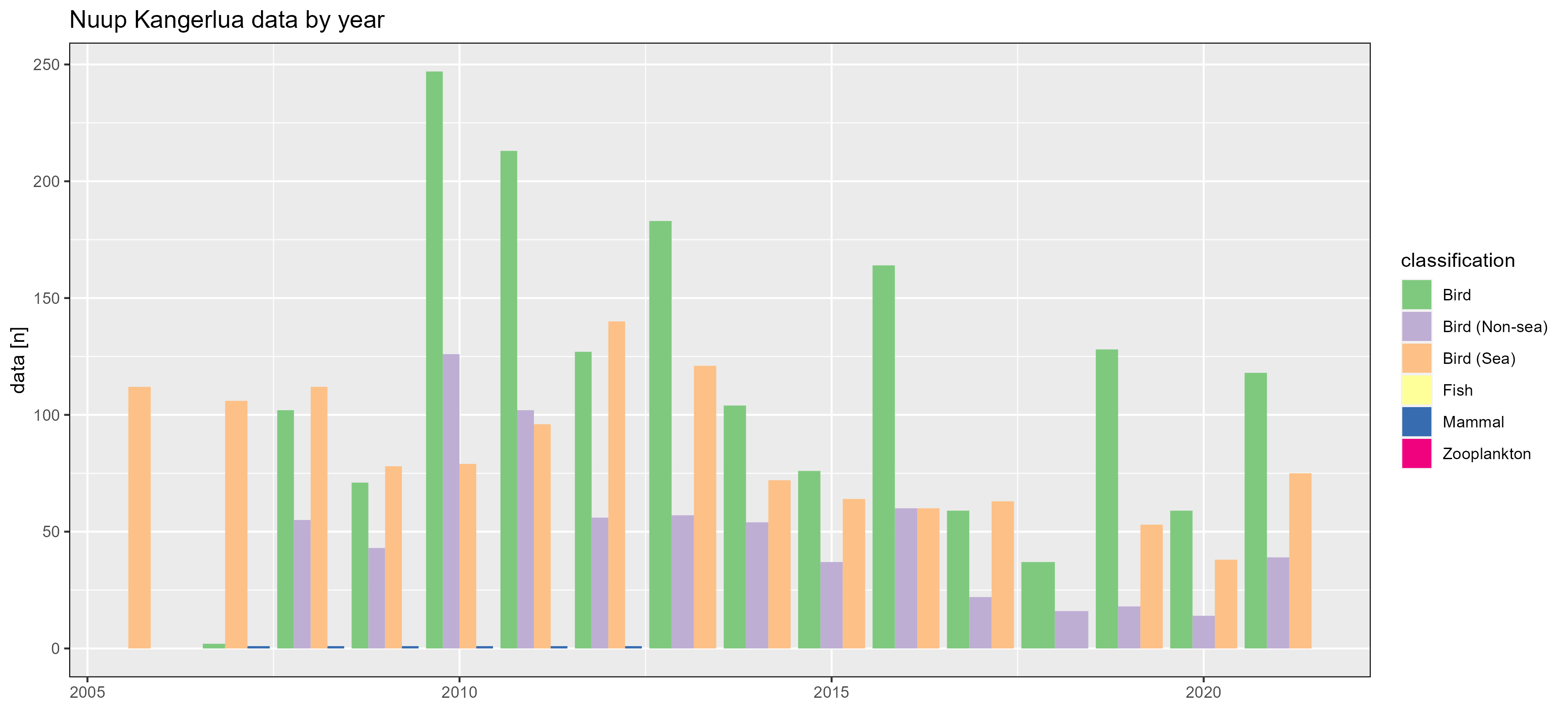
Nuup Kangerlua

sessionInfo()R version 4.3.2 (2023-10-31)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.6 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=en_GB.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB.UTF-8 LC_COLLATE=en_GB.UTF-8
[5] LC_MONETARY=en_GB.UTF-8 LC_MESSAGES=en_GB.UTF-8
[7] LC_PAPER=en_GB.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_GB.UTF-8 LC_IDENTIFICATION=C
time zone: Europe/Paris
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] vctrs_0.6.5 httr_1.4.7 cli_3.6.1 knitr_1.45
[5] rlang_1.1.2 xfun_0.41 stringi_1.8.2 processx_3.8.2
[9] promises_1.2.1 jsonlite_1.8.8 glue_1.6.2 rprojroot_2.0.4
[13] git2r_0.33.0 htmltools_0.5.7 httpuv_1.6.13 ps_1.7.5
[17] sass_0.4.8 fansi_1.0.5 rmarkdown_2.25 jquerylib_0.1.4
[21] tibble_3.2.1 evaluate_0.23 fastmap_1.1.1 yaml_2.3.7
[25] lifecycle_1.0.4 whisker_0.4.1 stringr_1.5.1 compiler_4.3.2
[29] fs_1.6.3 pkgconfig_2.0.3 Rcpp_1.0.11 rstudioapi_0.15.0
[33] later_1.3.2 digest_0.6.33 R6_2.5.1 utf8_1.2.4
[37] pillar_1.9.0 callr_3.7.3 magrittr_2.0.3 bslib_0.6.1
[41] tools_4.3.2 cachem_1.0.8 getPass_0.2-2