Comparisons with other data sets
ERM
2023-06-16
Last updated: 2023-06-16
Checks: 7 0
Knit directory: Cardiotoxicity/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230109) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 751239e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/41588_2018_171_MOESM3_ESMeQTL_ST2_for paper.csv
Ignored: data/Arr_GWAS.txt
Ignored: data/Arr_geneset.RDS
Ignored: data/BC_cell_lines.csv
Ignored: data/CADGWASgene_table.csv
Ignored: data/CAD_geneset.RDS
Ignored: data/Clamp_Summary.csv
Ignored: data/Cormotif_24_k1-5_raw.RDS
Ignored: data/DAgostres24.RDS
Ignored: data/DAtable1.csv
Ignored: data/DDEMresp_list.csv
Ignored: data/DDE_reQTL.txt
Ignored: data/DDEresp_list.csv
Ignored: data/DEG-GO/
Ignored: data/DEG_cormotif.RDS
Ignored: data/DF_Plate_Peak.csv
Ignored: data/DRC48hoursdata.csv
Ignored: data/Da24counts.txt
Ignored: data/Dx24counts.txt
Ignored: data/Dx_reQTL_specific.txt
Ignored: data/Ep24counts.txt
Ignored: data/GOIsig.csv
Ignored: data/GOplots.R
Ignored: data/GTEX_setsimple.csv
Ignored: data/GTEx_gene_list.csv
Ignored: data/HFGWASgene_table.csv
Ignored: data/HF_geneset.RDS
Ignored: data/Heart_Left_Ventricle.v8.egenes.txt
Ignored: data/Hf_GWAS.txt
Ignored: data/K_cluster
Ignored: data/K_cluster_kisthree.csv
Ignored: data/K_cluster_kistwo.csv
Ignored: data/LDH48hoursdata.csv
Ignored: data/Mt24counts.txt
Ignored: data/RINsamplelist.txt
Ignored: data/Seonane2019supp1.txt
Ignored: data/TOP2Bi-24hoursGO_analysis.csv
Ignored: data/TR24counts.txt
Ignored: data/Top2biresp_cluster24h.csv
Ignored: data/Viabilitylistfull.csv
Ignored: data/allexpressedgenes.txt
Ignored: data/allgenes.txt
Ignored: data/allmatrix.RDS
Ignored: data/avgLD50.RDS
Ignored: data/backGL.txt
Ignored: data/cormotif_3hk1-8.RDS
Ignored: data/cormotif_initalK5.RDS
Ignored: data/cormotif_initialK5.RDS
Ignored: data/cormotif_initialall.RDS
Ignored: data/counts24hours.RDS
Ignored: data/cpmcount.RDS
Ignored: data/cpmnorm_counts.csv
Ignored: data/crispr_genes.csv
Ignored: data/cvd_GWAS.txt
Ignored: data/dat_cpm.RDS
Ignored: data/data_outline.txt
Ignored: data/efit2.RDS
Ignored: data/efit2results.RDS
Ignored: data/ensembl_backup.RDS
Ignored: data/ensgtotal.txt
Ignored: data/filenameonly.txt
Ignored: data/filtered_cpm_counts.csv
Ignored: data/filtered_raw_counts.csv
Ignored: data/filtermatrix_x.RDS
Ignored: data/folder_05top/
Ignored: data/geneDoxonlyQTL.csv
Ignored: data/gene_corr_frame.RDS
Ignored: data/gene_prob_tran3h.RDS
Ignored: data/gene_probabilityk5.RDS
Ignored: data/gostresTop2bi_ER.RDS
Ignored: data/gostresTop2bi_LR
Ignored: data/gostresTop2bi_LR.RDS
Ignored: data/gostresTop2bi_TI.RDS
Ignored: data/gostrescoNR
Ignored: data/gtex/
Ignored: data/heartgenes.csv
Ignored: data/individualDRCfile.RDS
Ignored: data/individual_DRC48.RDS
Ignored: data/individual_LDH48.RDS
Ignored: data/knowfig4.csv
Ignored: data/knowfig5.csv
Ignored: data/mymatrix.RDS
Ignored: data/nonresponse_cluster24h.csv
Ignored: data/norm_LDH.csv
Ignored: data/norm_counts.csv
Ignored: data/old_sets/
Ignored: data/plan2plot.png
Ignored: data/raw_counts.csv
Ignored: data/response_cluster24h.csv
Ignored: data/sigVDA24.txt
Ignored: data/sigVDA3.txt
Ignored: data/sigVDX24.txt
Ignored: data/sigVDX3.txt
Ignored: data/sigVEP24.txt
Ignored: data/sigVEP3.txt
Ignored: data/sigVMT24.txt
Ignored: data/sigVMT3.txt
Ignored: data/sigVTR24.txt
Ignored: data/sigVTR3.txt
Ignored: data/siglist.RDS
Ignored: data/slope_table.csv
Ignored: data/table3a.omar
Ignored: data/toplistall.RDS
Ignored: data/tvl24hour.txt
Ignored: data/tvl24hourw.txt
Ignored: data/venn_code.R
Untracked files:
Untracked: .RDataTmp
Untracked: .RDataTmp1
Untracked: .RDataTmp2
Untracked: OmicNavigator_learn.R
Untracked: code/DRC_plotfigure1.png
Untracked: code/cpm_boxplot.R
Untracked: code/fig1plot.png
Untracked: code/figurelegeddrc.png
Untracked: cormotif_probability_genelist.csv
Untracked: individual-legenddark2.png
Untracked: installed_old.rda
Untracked: motif_ER.txt
Untracked: motif_LR.txt
Untracked: motif_NR.txt
Untracked: motif_TI.txt
Untracked: output/daplot.RDS
Untracked: output/dxplot.RDS
Untracked: output/epplot.RDS
Untracked: output/mtplot.RDS
Untracked: output/output-old/
Untracked: output/trplot.RDS
Untracked: output/veplot.RDS
Untracked: reneebasecode.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/other_analysis.Rmd) and
HTML (docs/other_analysis.html) files. If you’ve configured
a remote Git repository (see ?wflow_git_remote), click on
the hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 751239e | reneeisnowhere | 2023-06-16 | updating and moving code |
| Rmd | 3d4ca64 | reneeisnowhere | 2023-06-16 | updates on Friday |
| html | 7ce5a2c | reneeisnowhere | 2023-06-15 | Build site. |
| Rmd | 9afd6a0 | reneeisnowhere | 2023-06-15 | fixing wflow error |
| html | 6b03af2 | reneeisnowhere | 2023-06-15 | Build site. |
| html | e02ca18 | reneeisnowhere | 2023-06-15 | Build site. |
| Rmd | 9ad6b91 | reneeisnowhere | 2023-06-15 | showing code adding pvalue text |
| html | 750ee45 | reneeisnowhere | 2023-06-15 | Build site. |
| Rmd | 637531c | reneeisnowhere | 2023-06-15 | moving out the knowles data |
| Rmd | f8f511a | reneeisnowhere | 2023-06-15 | updates and simplifications of code |
| Rmd | 7fc7ec7 | reneeisnowhere | 2023-06-14 | updating code |
| html | 4b6bd9b | reneeisnowhere | 2023-06-07 | Build site. |
| Rmd | 4b62a1e | reneeisnowhere | 2023-06-07 | updated numbers for grant |
| html | d64a0ae | reneeisnowhere | 2023-06-07 | Build site. |
| Rmd | 81f100c | reneeisnowhere | 2023-06-07 | add Dox reQTL grouping and AC shared numbers |
| html | 47f85a2 | reneeisnowhere | 2023-06-07 | Build site. |
| Rmd | 0ecede3 | reneeisnowhere | 2023-06-07 | data with CRispr set added and heatmap changes |
| html | 9a62d7c | reneeisnowhere | 2023-06-06 | Build site. |
| Rmd | 232d3b0 | reneeisnowhere | 2023-06-06 | Finally tested chisquare between knowles data |
| Rmd | 10bcf05 | reneeisnowhere | 2023-06-06 | updating the k4/k5 analysis of DEG |
| html | b4dd015 | reneeisnowhere | 2023-06-02 | Build site. |
| Rmd | 652d7e8 | reneeisnowhere | 2023-06-02 | updated heatmap Seoane Chisqure for cormotif |
| html | 5aeda27 | reneeisnowhere | 2023-06-02 | Build site. |
| Rmd | 6524ecd | reneeisnowhere | 2023-06-02 | Adding in heatmaps of chi values |
| html | 5dd9ddb | reneeisnowhere | 2023-06-02 | Build site. |
| Rmd | 8eaea47 | reneeisnowhere | 2023-06-02 | chi square updates |
| html | e4d118c | reneeisnowhere | 2023-06-01 | Build site. |
| Rmd | 573a477 | reneeisnowhere | 2023-06-01 | Updateing supplement 1 seoan chi results |
| html | cc3dfc3 | reneeisnowhere | 2023-06-01 | Build site. |
| Rmd | 522cce8 | reneeisnowhere | 2023-06-01 | Adding chisquare and other analysis |
| html | 4723cdd | reneeisnowhere | 2023-05-31 | Build site. |
| Rmd | 07a6e06 | reneeisnowhere | 2023-05-31 | adding in more data including Cormotif enrichment numbers |
| html | 6fd877b | reneeisnowhere | 2023-05-31 | Build site. |
| Rmd | b2ba055 | reneeisnowhere | 2023-05-31 | adding Seoane data with cormotif things |
| html | 4c0812e | reneeisnowhere | 2023-05-26 | Build site. |
| Rmd | c7e0fcc | reneeisnowhere | 2023-05-26 | adding in Gtex and chisquare values |
| html | e1bcef0 | reneeisnowhere | 2023-05-26 | Build site. |
| Rmd | 0f512c3 | reneeisnowhere | 2023-05-26 | adding in Gtex and chisquare values |
| Rmd | 1f8c483 | reneeisnowhere | 2023-05-26 | updating code with gtex and chisq |
| Rmd | 25d32da | reneeisnowhere | 2023-05-26 | Adding 3 hour and chisq test to populations |
| html | 5610749 | reneeisnowhere | 2023-05-22 | Build site. |
| Rmd | 889832a | reneeisnowhere | 2023-05-22 | add Seoane data again |
| html | 36cbdab | reneeisnowhere | 2023-05-22 | Build site. |
| Rmd | de54fd5 | reneeisnowhere | 2023-05-22 | add Seoane data |
| html | 7243a18 | reneeisnowhere | 2023-05-22 | Build site. |
| Rmd | e2b3215 | reneeisnowhere | 2023-05-22 | add Seoane data |
| html | c3481d8 | reneeisnowhere | 2023-05-22 | Build site. |
| Rmd | acbd0a8 | reneeisnowhere | 2023-05-22 | updates on GWAS enrichment |
| Rmd | e8c82ec | reneeisnowhere | 2023-05-18 | adding other_analysis and genes of interest log2cpm |
library(limma)
library(tidyverse)
library(ggsignif)
library(biomaRt)
library(RColorBrewer)
library(cowplot)
library(ggpubr)
library(scales)
library(sjmisc)
library(kableExtra)
library(broom)
library(ComplexHeatmap)Data set comparison
order:
ArrGWAS
HFGWAS
CADGWAS
Seaone 2019
Supplemental 1 (408 genes)
Supplemental 4 (54 genes)
Crispr sets
GWAS
ArrGWAS to 24 hour DEG genes p < 0.05
24 hour data set
# How I did the string split
# Arr_GWAS <- ArrGWAS[,13]
# names(Arr_GWAS) <- "genesplit"
# Arr_GWAS <- Arr_GWAS %>%
# separate_longer_delim(genesplit, delim = ",")
#write.csv(Arr_GWAS,"data/Arr_GWAS.txt")
arr_GWAS <- read.csv("data/Arr_GWAS.txt", row.names = 1)
Arr_geneset <- readRDS("data/Arr_geneset.RDS")
# Arr_geneset <- getBM(attributes=my_attributes,filters ='hgnc_symbol',
# values = arr_GWAS, mart = ensembl)
# #remove duplicates
# Arr_geneset <- Arr_geneset %>% distinct(entrezgene_id, .keep_all =TRUE)
# saveRDS(Arr_geneset,"data/Arr_geneset.RDS")
#Apply sorting
toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(ARR=if_else(ENTREZID %in%Arr_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,ARR) %>%
summarize(ARRcount=n())%>%
pivot_wider(id_cols = c(id,sigcount), names_from=c(ARR), values_from=ARRcount) %>%
mutate(ARRprop=(y/(y+no)*100)) %>%
ggplot(., aes(x=id, y=ARRprop)) +
geom_col()+
geom_text(aes(x=id, label = sprintf("%.2f",ARRprop), vjust=-.2))+
#geom_text(aes(label = expression(paste0("number"~a,"out of",~b))))+
facet_wrap(~sigcount)+
ggtitle("24 hour non-significant and significant enrichment proporitions of Arrhythmia GWAS ")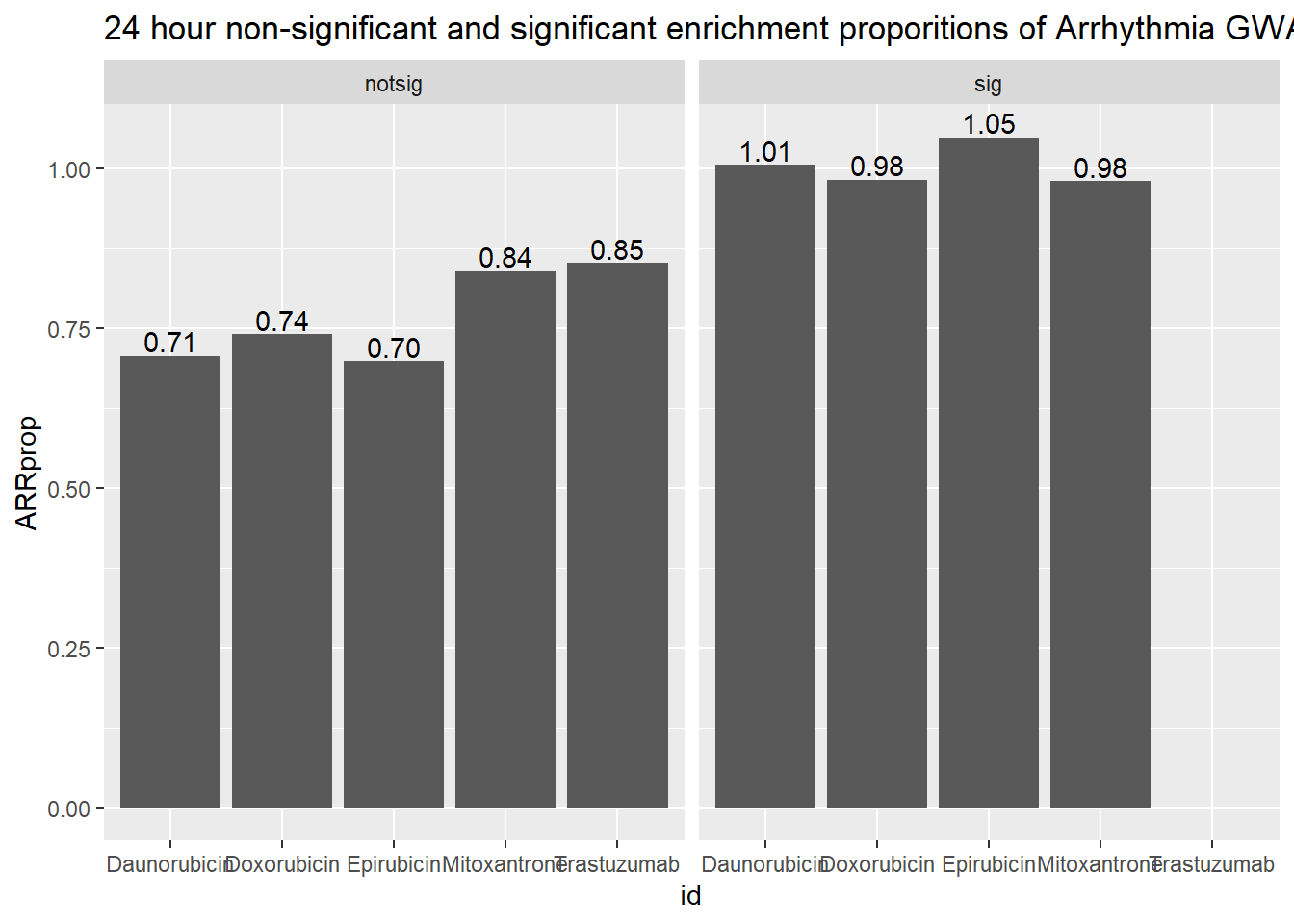
##make table of numbers:
dataframARR <- toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(ARR=if_else(ENTREZID %in%Arr_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,ARR) %>%
summarize(ARRcount=n()) %>%
as.data.frame()
dataframARR %>%
kable(., caption= "Significant (adj. P value of <0.05) and non-sig gene counts in Arrhythmia 24 hour GWAS") %>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | sigcount | ARR | ARRcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 7169 |
| Daunorubicin | notsig | y | 51 |
| Daunorubicin | sig | no | 6795 |
| Daunorubicin | sig | y | 69 |
| Doxorubicin | notsig | no | 7512 |
| Doxorubicin | notsig | y | 56 |
| Doxorubicin | sig | no | 6452 |
| Doxorubicin | sig | y | 64 |
| Epirubicin | notsig | no | 7827 |
| Epirubicin | notsig | y | 55 |
| Epirubicin | sig | no | 6137 |
| Epirubicin | sig | y | 65 |
| Mitoxantrone | notsig | no | 12650 |
| Mitoxantrone | notsig | y | 107 |
| Mitoxantrone | sig | no | 1314 |
| Mitoxantrone | sig | y | 13 |
| Trastuzumab | notsig | no | 13964 |
| Trastuzumab | notsig | y | 120 |
3 hour data set
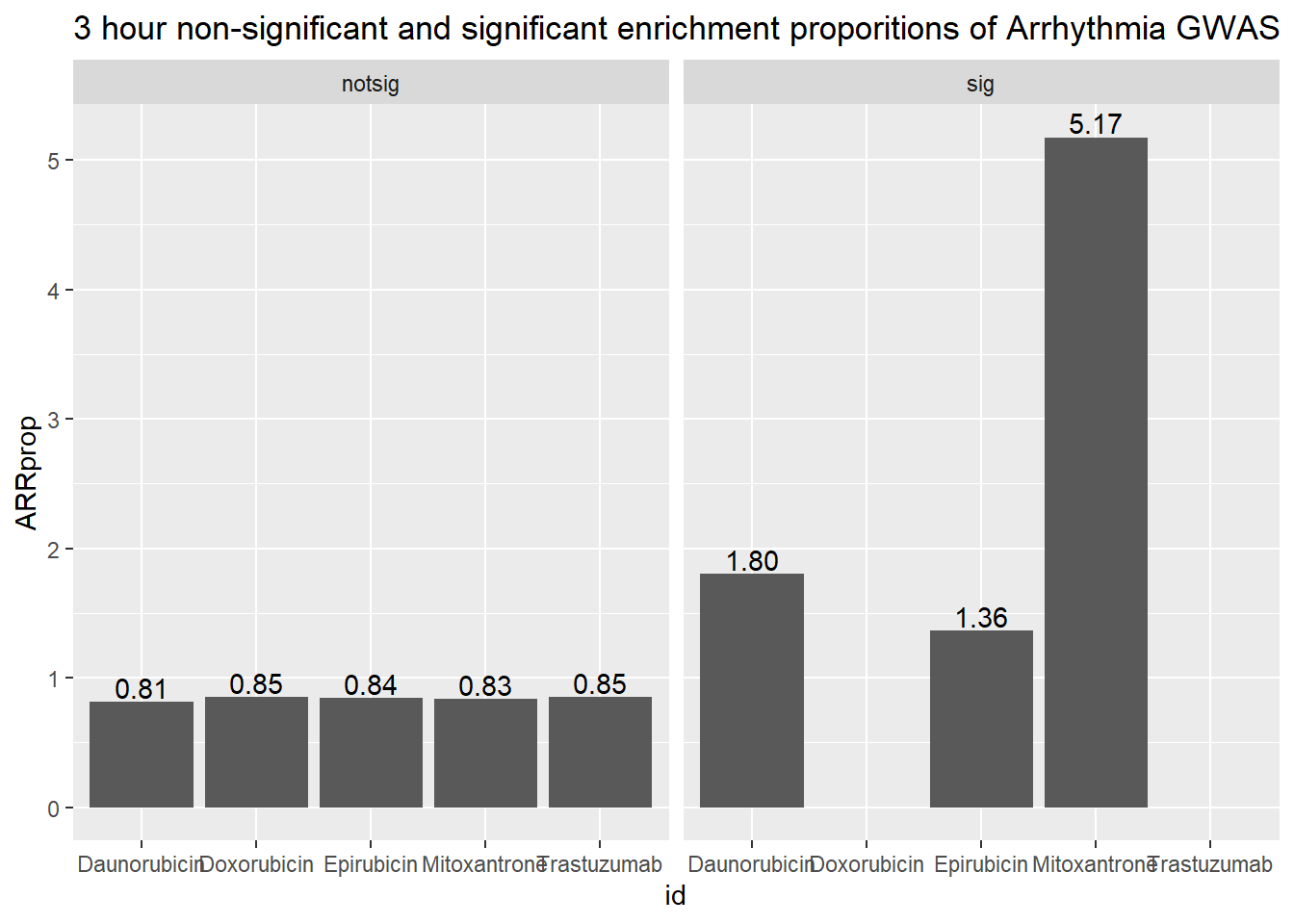
| id | sigcount | ARR | ARRcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 13419 |
| Daunorubicin | notsig | y | 110 |
| Daunorubicin | sig | no | 545 |
| Daunorubicin | sig | y | 10 |
| Doxorubicin | notsig | no | 13948 |
| Doxorubicin | notsig | y | 120 |
| Doxorubicin | sig | no | 16 |
| Epirubicin | notsig | no | 13747 |
| Epirubicin | notsig | y | 117 |
| Epirubicin | sig | no | 217 |
| Epirubicin | sig | y | 3 |
| Mitoxantrone | notsig | no | 13909 |
| Mitoxantrone | notsig | y | 117 |
| Mitoxantrone | sig | no | 55 |
| Mitoxantrone | sig | y | 3 |
| Trastuzumab | notsig | no | 13964 |
| Trastuzumab | notsig | y | 120 |
chi square test ARR
chi_funarr <- toplistall %>%
mutate(id = as.factor(id)) %>%
dplyr::filter(id!="Trastuzumab") %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(ARR=if_else(ENTREZID %in%Arr_geneset$entrezgene_id,"y","no")) %>%
group_by(id,time) %>%
summarise(pvalue= chisq.test(ARR, sigcount)$p.value)
chi_funarr %>%
kable(., caption= "after performing chi square test between DEgenes, and non DE genes") %>%
kable_paper("striped") %>%
kable_styling(full_width = FALSE,font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | time | pvalue |
|---|---|---|
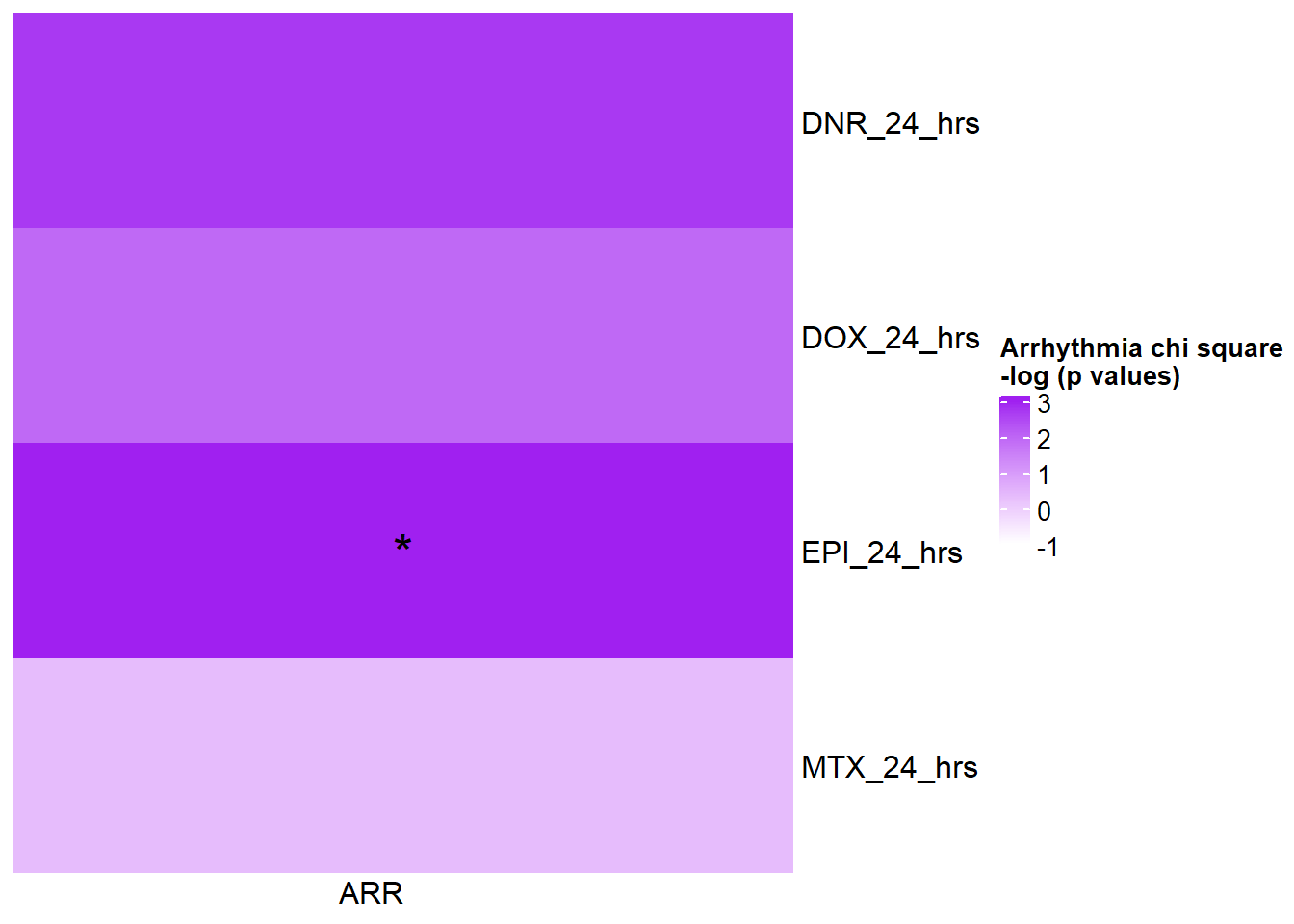
| Daunorubicin | 24_hours | 0.0661799 |
| Daunorubicin | 3_hours | 0.0245603 |
| Doxorubicin | 24_hours | 0.1422138 |
| Doxorubicin | 3_hours | 1.0000000 |
| Epirubicin | 24_hours | 0.0313365 |
| Epirubicin | 3_hours | 0.6437411 |
| Mitoxantrone | 24_hours | 0.7079851 |
| Mitoxantrone | 3_hours | 0.0040856 |
HFGWAS
24 hours HF
##just like ARrGWAS- imported the total csv, the took the "nearest" column and separated out the gene info
# test <- HFGWAS %>%
# select(nearest) %>%
# separate_wider_delim(nearest, delim = "[", names_sep = "", too_few = "align_start")
# test2 <- str_sub(test$nearest2,0,nchar(test$nearest2)-1)
# Hf_GWAS <- test2
#write.csv(Hf_GWAS, "data/Hf_GWAS.txt")
# HF_GWAS <- read.csv("data/Hf_GWAS.txt", row.names =1)
#
# HF_geneset <- getBM(attributes=my_attributes,filters ='hgnc_symbol',
# values = HF_GWAS, mart = ensembl)
# #remove duplicates
# HF_geneset <- HF_geneset %>% distinct(entrezgene_id, .keep_all =TRUE)
# saveRDS(HF_geneset,"data/HF_geneset.RDS")
HF_geneset <- readRDS("data/HF_geneset.RDS")
#Apply sorting
toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(HF=if_else(ENTREZID %in%HF_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,HF) %>%
summarize(HFcount=n())%>%
pivot_wider(id_cols = c(id,sigcount), names_from=c(HF), values_from=HFcount) %>%
mutate(HFprop=(y/(y+no)*100)) %>%
ggplot(., aes(x=id, y=HFprop)) +
geom_col()+
geom_text(aes(x=id, label = sprintf("%.2f",HFprop), vjust=-.2))+
#geom_text(aes(label = expression(paste0("number"~a,"out of",~b))))+
facet_wrap(~sigcount)+
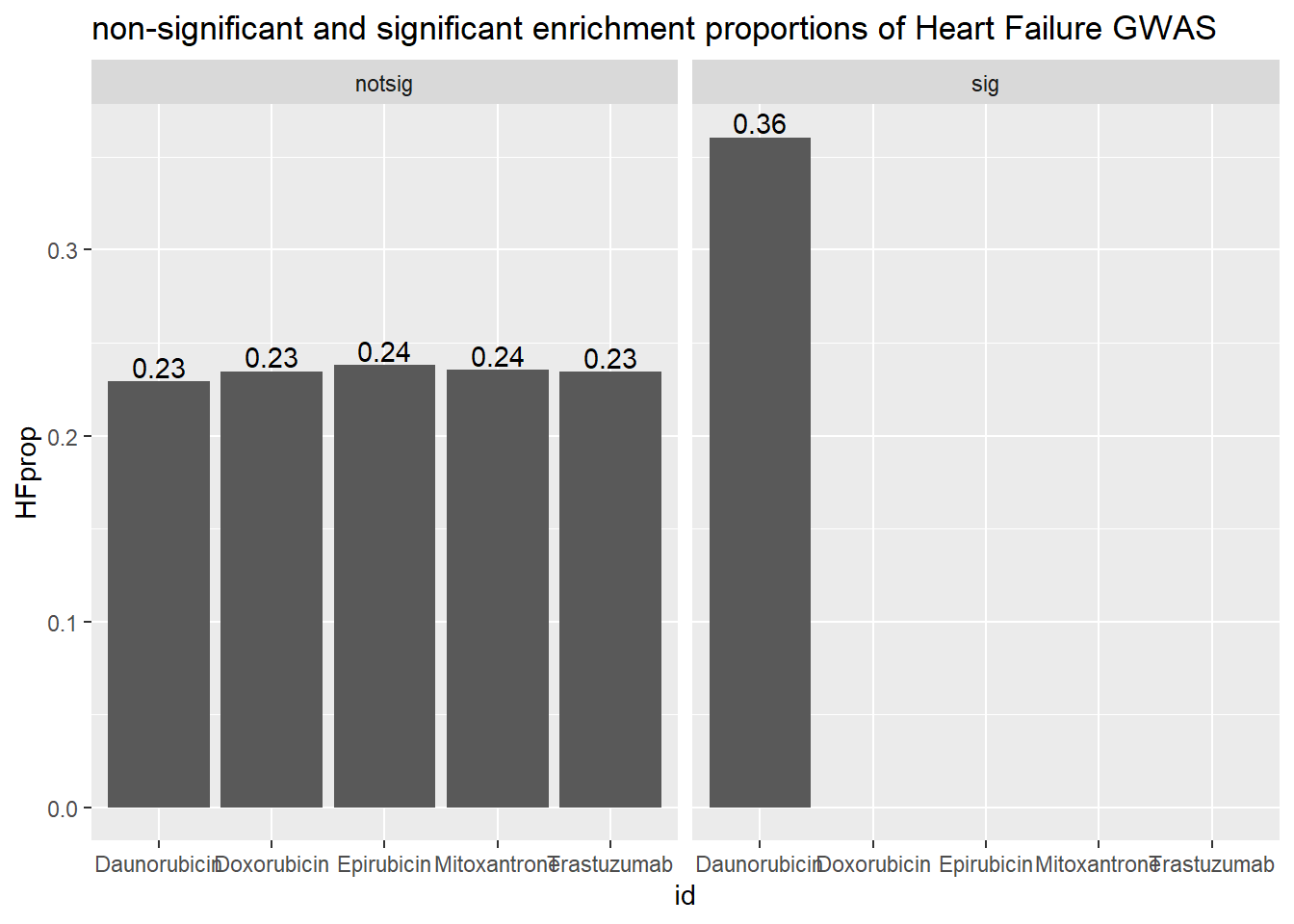
ggtitle("non-significant and significant enrichment proporitions of Heart Failure GWAS ")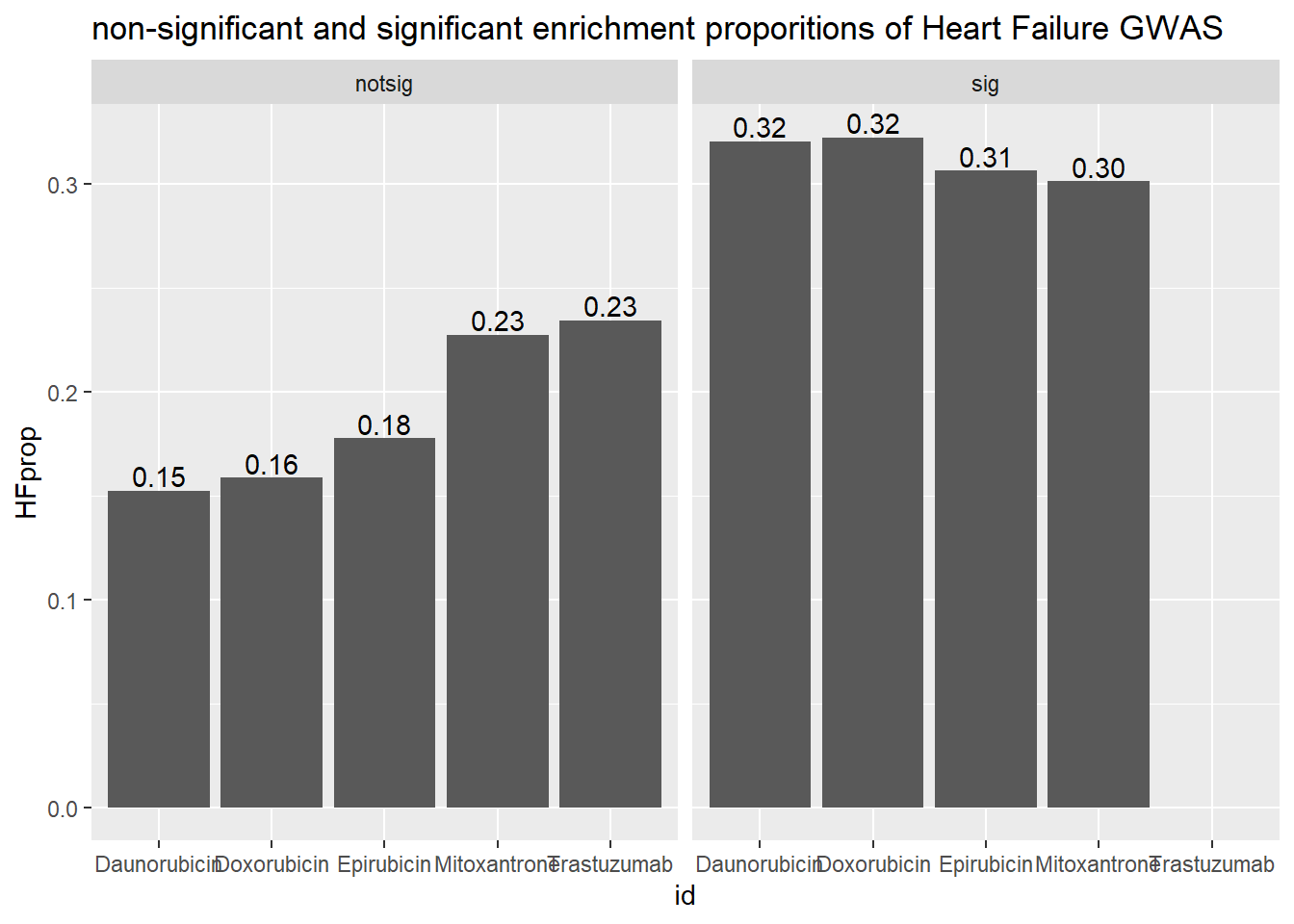
##make table of numbers:
dataframHF <- toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(HF=if_else(ENTREZID %in%HF_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,HF) %>%
summarize(HFcount=n()) %>%
as.data.frame()
dataframHF %>% #mutate_at(.vars = 6, .funs= scientific_format()) %>%
kable(., caption= "Significant (adj. P value of <0.05) and non-sig gene counts in HFhythmia GWAS") %>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | sigcount | HF | HFcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 7209 |
| Daunorubicin | notsig | y | 11 |
| Daunorubicin | sig | no | 6842 |
| Daunorubicin | sig | y | 22 |
| Doxorubicin | notsig | no | 7556 |
| Doxorubicin | notsig | y | 12 |
| Doxorubicin | sig | no | 6495 |
| Doxorubicin | sig | y | 21 |
| Epirubicin | notsig | no | 7868 |
| Epirubicin | notsig | y | 14 |
| Epirubicin | sig | no | 6183 |
| Epirubicin | sig | y | 19 |
| Mitoxantrone | notsig | no | 12728 |
| Mitoxantrone | notsig | y | 29 |
| Mitoxantrone | sig | no | 1323 |
| Mitoxantrone | sig | y | 4 |
| Trastuzumab | notsig | no | 14051 |
| Trastuzumab | notsig | y | 33 |
3 hours HF
| id | sigcount | HF | HFcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 13498 |
| Daunorubicin | notsig | y | 31 |
| Daunorubicin | sig | no | 553 |
| Daunorubicin | sig | y | 2 |
| Doxorubicin | notsig | no | 14035 |
| Doxorubicin | notsig | y | 33 |
| Doxorubicin | sig | no | 16 |
| Epirubicin | notsig | no | 13831 |
| Epirubicin | notsig | y | 33 |
| Epirubicin | sig | no | 220 |
| Mitoxantrone | notsig | no | 13993 |
| Mitoxantrone | notsig | y | 33 |
| Mitoxantrone | sig | no | 58 |
| Trastuzumab | notsig | no | 14051 |
| Trastuzumab | notsig | y | 33 |
chi square test HF
chi_funhf <- toplistall %>%
mutate(id = as.factor(id)) %>%
dplyr::filter(id!="Trastuzumab") %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(HF=if_else(ENTREZID %in%HF_geneset$entrezgene_id,"y","no")) %>%
group_by(id,time) %>%
summarise(pvalue= chisq.test(HF, sigcount)$p.value)
chi_funhf %>%
kable(., caption= "after performing chi square test between DEgenes, and non DE genes") %>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE,font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | time | pvalue |
|---|---|---|
| Daunorubicin | 24_hours | 0.0589189 |
| Daunorubicin | 3_hours | 0.8581056 |
| Doxorubicin | 24_hours | 0.0674061 |
| Doxorubicin | 3_hours | 1.0000000 |
| Epirubicin | 24_hours | 0.1635851 |
| Epirubicin | 3_hours | 0.9826436 |
| Mitoxantrone | 24_hours | 0.8156838 |
| Mitoxantrone | 3_hours | 1.0000000 |
 ## CAD GWAS
## CAD GWAS
24 hour data set
# test <- CADGWAS %>%
# select(nearest) %>%
# separate_wider_delim(nearest, delim = "[", names_sep = "", too_few = "align_start")
# test2 <- str_sub(test$nearest2,0,nchar(test$nearest2)-1)
#
# test2[c(32,38,44,74,112,126,191,212)] <- c("TPCN1","C2orf43","FAM222A", "TDRD15" ,"AGPAT4","SVOP","SVOP","PLG")
#
# test2 [c(218,226,228,233,239,245,256,270,281,322,324,332,335,338,347,351,352,358)] <- c("HPCAL1", "KLHL29" , "COL4A3BP" , "ARAP1" ,
# "VEGFA", "TBPL1","SLC22A3" ,"C19orf38","LPA","VPS29","ATP2A2" ,"ATP2A2","KLHL29","GUCY1A3","KCNE2", "HOXB9","P2RY2" ,"CTC-236F12.4")
#
# CAD_GWAS <- test2
#write.csv(CAD_GWAS, "data/cvd_GWAS.txt")
CAD_GWAS <- read.csv("data/cvd_GWAS.txt", row.names =1)
# CAD_geneset <- getBM(attributes=my_attributes,filters ='hgnc_symbol',
# values = CAD_GWAS, mart = ensembl)
# #remove duplicates
# CAD_geneset <- CAD_geneset %>% distinct(entrezgene_id, .keep_all =TRUE)
#
# saveRDS(CAD_geneset,"data/CAD_geneset.RDS")
CAD_geneset <- readRDS("data/CAD_geneset.RDS")
#Apply sorting
toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(CAD=if_else(ENTREZID %in%CAD_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,CAD) %>%
summarize(CADcount=n())%>%
pivot_wider(id_cols = c(id,sigcount), names_from=c(CAD), values_from=CADcount) %>%
mutate(CADprop=(y/(y+no)*100)) %>%
ggplot(., aes(x=id, y=CADprop)) +
geom_col()+
geom_text(aes(x=id, label = sprintf("%.2f",CADprop), vjust=-.2))+
#geom_text(aes(label = expression(paste0("number"~a,"out of",~b))))+
facet_wrap(~sigcount)+
ggtitle("non-significant and significant enrichment proporitions of CAD GWAS ")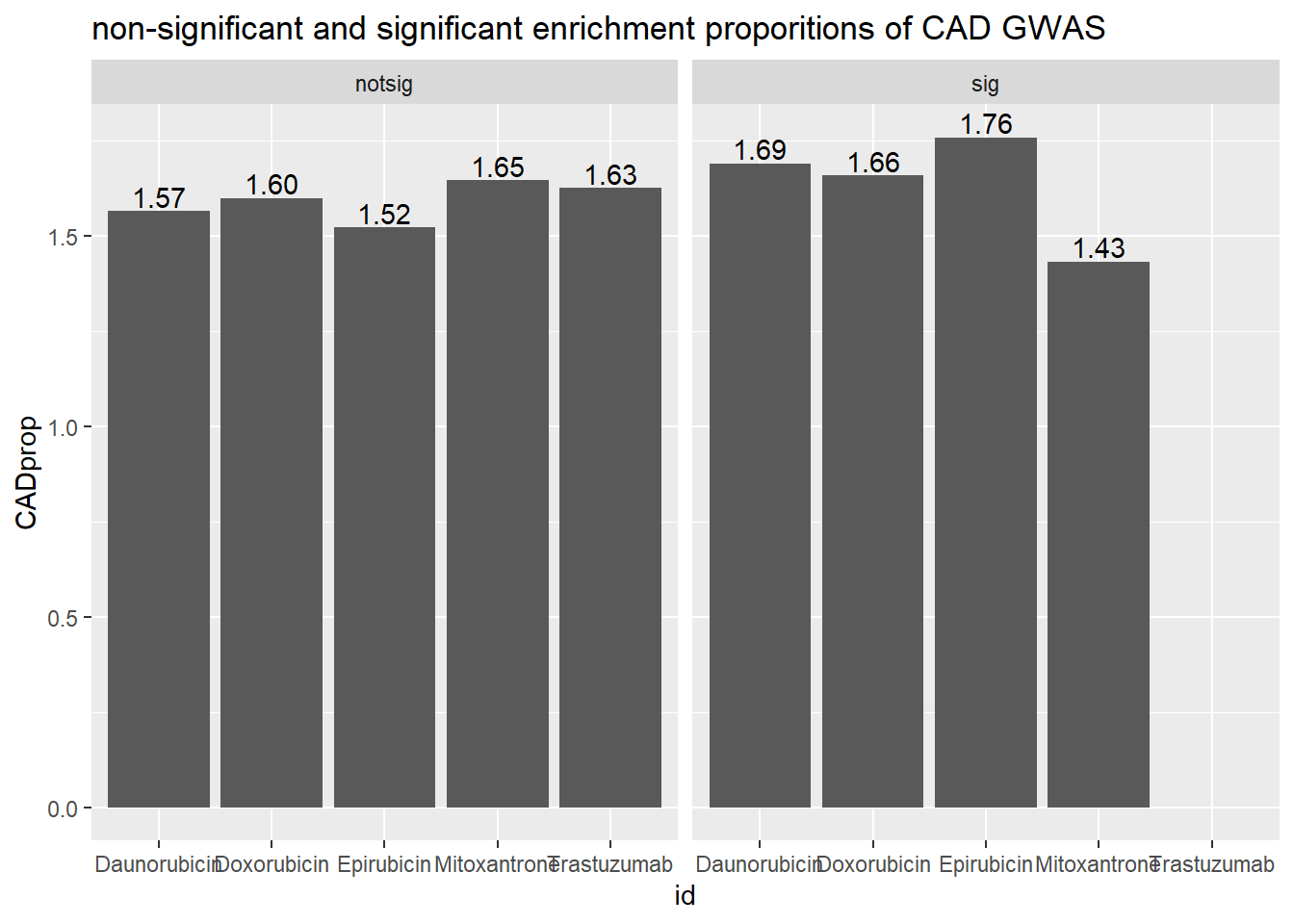
##make table of numbers:
dataframCAD <- toplist24hr %>%
mutate(id = as.factor(id)) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(CAD=if_else(ENTREZID %in%CAD_geneset$entrezgene_id,"y","no")) %>%
group_by(id,sigcount,CAD) %>%
summarize(CADcount=n()) %>%
as.data.frame()
dataframCAD %>% #mutate_at(.vars = 6, .funs= scientific_format()) %>%
kable(., caption= "Significant (adj. P value of <0.05) and non-sig gene counts in CAD GWAS") %>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | sigcount | CAD | CADcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 7107 |
| Daunorubicin | notsig | y | 113 |
| Daunorubicin | sig | no | 6748 |
| Daunorubicin | sig | y | 116 |
| Doxorubicin | notsig | no | 7447 |
| Doxorubicin | notsig | y | 121 |
| Doxorubicin | sig | no | 6408 |
| Doxorubicin | sig | y | 108 |
| Epirubicin | notsig | no | 7762 |
| Epirubicin | notsig | y | 120 |
| Epirubicin | sig | no | 6093 |
| Epirubicin | sig | y | 109 |
| Mitoxantrone | notsig | no | 12547 |
| Mitoxantrone | notsig | y | 210 |
| Mitoxantrone | sig | no | 1308 |
| Mitoxantrone | sig | y | 19 |
| Trastuzumab | notsig | no | 13855 |
| Trastuzumab | notsig | y | 229 |
3 hour data set
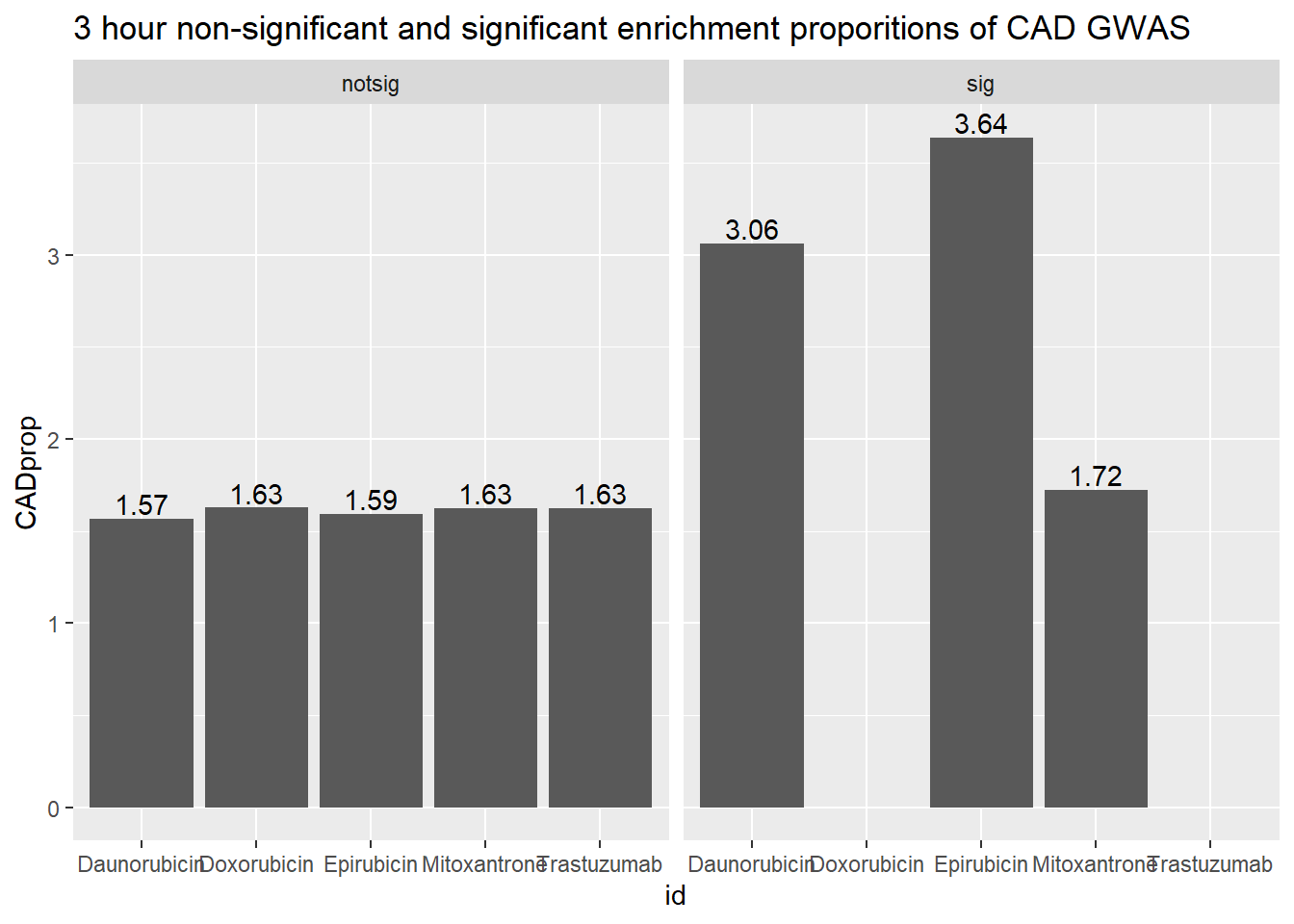
| id | sigcount | CAD | CADcount |
|---|---|---|---|
| Daunorubicin | notsig | no | 13317 |
| Daunorubicin | notsig | y | 212 |
| Daunorubicin | sig | no | 538 |
| Daunorubicin | sig | y | 17 |
| Doxorubicin | notsig | no | 13839 |
| Doxorubicin | notsig | y | 229 |
| Doxorubicin | sig | no | 16 |
| Epirubicin | notsig | no | 13643 |
| Epirubicin | notsig | y | 221 |
| Epirubicin | sig | no | 212 |
| Epirubicin | sig | y | 8 |
| Mitoxantrone | notsig | no | 13798 |
| Mitoxantrone | notsig | y | 228 |
| Mitoxantrone | sig | no | 57 |
| Mitoxantrone | sig | y | 1 |
| Trastuzumab | notsig | no | 13855 |
| Trastuzumab | notsig | y | 229 |
chi square test CAD
chi_funCAD <- toplistall %>%
mutate(id = as.factor(id)) %>%
dplyr::filter(id!="Trastuzumab") %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(CAD=if_else(ENTREZID %in%CAD_geneset$entrezgene_id,"y","no")) %>%
group_by(id,time) %>%
summarise(pvalue= chisq.test(CAD, sigcount)$p.value)
chi_funCAD %>%
kable(., caption= "after performing chi square test between DEgenes, and non DE genes") %>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE,font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| id | time | pvalue |
|---|---|---|
| Daunorubicin | 24_hours | 0.6037088 |
| Daunorubicin | 3_hours | 0.0104647 |
| Doxorubicin | 24_hours | 0.8356522 |
| Doxorubicin | 3_hours | 1.0000000 |
| Epirubicin | 24_hours | 0.3040510 |
| Epirubicin | 3_hours | 0.0350528 |
| Mitoxantrone | 24_hours | 0.6358068 |
| Mitoxantrone | 3_hours | 1.0000000 |

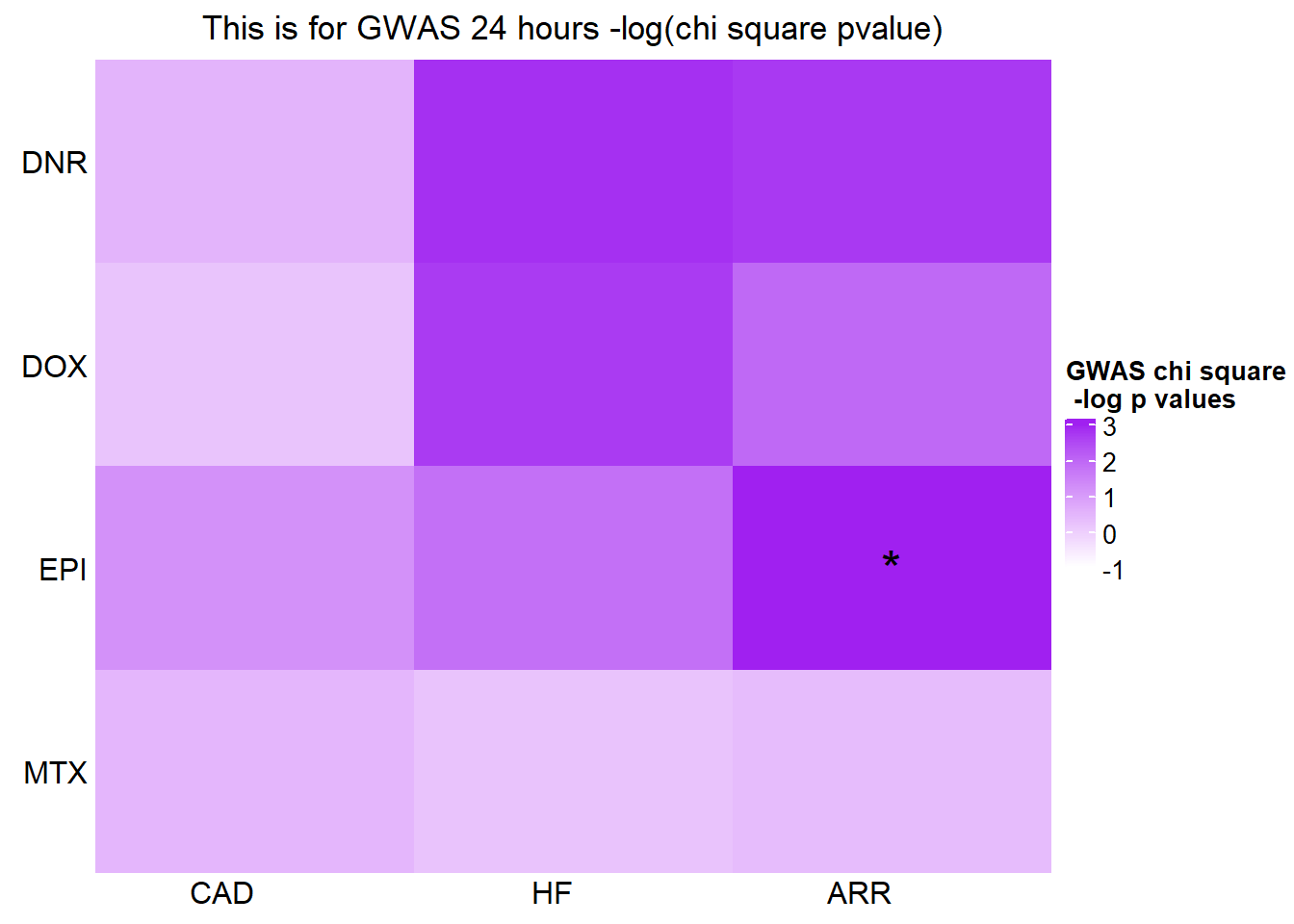
[1] "This is for GWAS 24 hours -log(chi square pvalue)"The star represents chi square p.value < 0.05.
# GWAS_goi <- c('RARG', 'ITGB7', 'TNS2','ZNF740','SLC28A3','RMI1',
# 'FEDORA' ,'GDF5','FRS2','HDDC2','EEF1B2')
#
# library(biomaRt)
# ensembl <- useMart("ensembl", dataset="hsapiens_gene_ensembl")
# my_chr <- c(1:22, 'M', 'X', 'Y')
# my_attributes <- c('entrezgene_id', 'ensembl_gene_id', 'hgnc_symbol')
#
#
# GWAS_goi<- getBM(attributes=my_attributes,filters ='hgnc_symbol',
# values = GWAS_goi, mart = ensembl)
# GWAS_goi<-GWAS_goi %>% distinct(entrezgene_id,.keep_all = TRUE) %>% add_row(entrezgene_id='124903732',ensembl_gene_id='ENSG00000260788', hgnc_symbol="RP11-298D21.1
# ")
# write.csv(GWAS_goi,"output/GWAS_goi.csv")
GWAS_goi <- read.csv("output/GWAS_goi.csv")
##get the abs FC of all GOI
GWASabsFCsig <-
toplistall %>%
# mutate(absFC=abs(logFC)) %>%
mutate(id = as.factor(id)) %>%
filter(id !="Trastuzumab") %>%
mutate(time=factor(time, levels=c("3_hours","24_hours"))) %>%
filter(ENTREZID %in% GWAS_goi$entrezgene_id) %>%
filter(time =="24_hours") %>%
dplyr::select(ENTREZID ,time, id,logFC, adj.P.Val, SYMBOL) %>%
# filter(adj.P.Val <0.05) %>%
mutate(id =case_match(id,'Daunorubicin'~'DNR','Doxorubicin'~'DOX','Epirubicin'~'EPI','Mitoxantrone'~'MTX', .default = id)) %>%
# mutate(time =case_match(time,"3_hours"~'3_hr',"24_hours"~'24_hr',.default = time)) %>%
# unite("trt_time",id:time,sep = '_') %>%
pivot_wider(id_cols=id, names_from = SYMBOL, values_from =adj.P.Val)# %>%
gwas_sig_mat <- GWASabsFCsig %>%
column_to_rownames(var="id") %>%
as.matrix()
GWASabsFC <- toplistall %>%
# mutate(absFC=abs(logFC)) %>%
mutate(id = as.factor(id)) %>%
filter(id !="Trastuzumab") %>%
filter(time=="24_hours") %>%
# mutate(time=factor(time, levels=c("3_hours","24_hours"))) %>%
filter(ENTREZID %in% GWAS_goi$entrezgene_id) %>%
dplyr::select(SYMBOL ,time, id, logFC) %>%
mutate(id =case_match(id,'Daunorubicin'~'DNR','Doxorubicin'~'DOX','Epirubicin'~'EPI','Mitoxantrone'~'MTX', .default = id)) %>%
# mutate(time =case_match(time,"3_hours"~'3_hr',"24_hours"~'24_hr',.default = time)) %>%
# unite("trt_time",id:time,sep = '_') %>%
pivot_wider(id_cols=id, names_from = SYMBOL, values_from = logFC) %>%
column_to_rownames(var="id") %>%
as.matrix()
Heatmap(GWASabsFC, name = "Fold change\nvalues",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title = "Fold change values of GWAS and TWAS genes",
column_title_side = "top",
column_title_gp = gpar(fontsize = 16, fontface = "bold"),
column_order= c('RARG',
'TNS2',
'ZNF740',
'SLC28A3',
'RMI1',
'EEF1B2',
'FRS2',
'HDDC2'),
column_names_rot = 0,
column_names_gp = gpar(fontsize = 12),
column_names_centered = TRUE,
cell_fun = function(j, i, x, y, width, height, fill) {
if(gwas_sig_mat[i, j] <0.05)
grid.text("*", x, y, gp = gpar(fontsize = 20))
})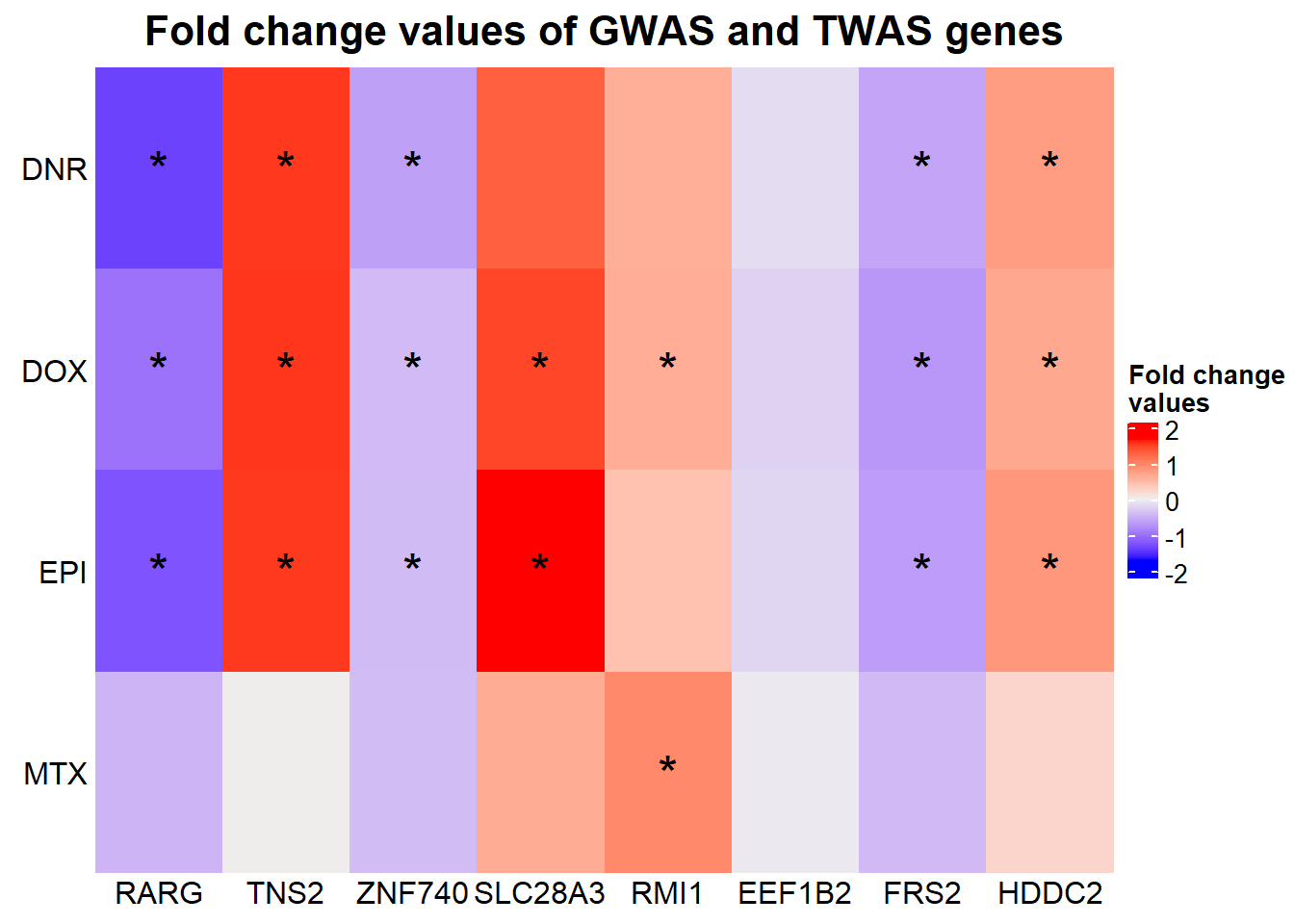
The stars represent all genes that have an adj. P. value of < 0.05 (significantly differentially expressed)
Crispr list
DEG_cormotif <- readRDS("data/DEG_cormotif.RDS")
list2env(DEG_cormotif,envir=.GlobalEnv)<environment: R_GlobalEnv># Crispr_list <- read_excel("C:/Users/renee/Downloads/41598_2021_92988_MOESM2_ESM.xlsx")
# View(Crispr_list)
# crispr_genes <- Crispr_list %>%
# dplyr::filter(p.value <0.05) %>%
# select(GeneName)
# crispr_genes <- getBM(attributes=my_attributes,filters ='hgnc_symbol',
# values =crispr_genes$GeneName, mart = ensembl)
# write.csv(crispr_genes,'data/crispr_genes.csv')
crispr_genes <- read.csv("data/crispr_genes.csv", row.names = 1)
print(" number of unique crispr_genes after conversion from hgnc symbol to entrezid")[1] " number of unique crispr_genes after conversion from hgnc symbol to entrezid"length(unique(crispr_genes$entrezgene_id))[1] 154crisprunique <- crispr_genes %>% distinct(entrezgene_id,.keep_all = TRUE)
Doxcrispall <- toplistall %>%
distinct(ENTREZID,.keep_all = TRUE) %>%
dplyr::select(ENTREZID,id,time)
crispmotifsummary <- Doxcrispall %>%
mutate(ER=if_else(ENTREZID %in% motif_ER,"y","no")) %>%
mutate(LR=if_else(ENTREZID %in% motif_LR,"y","no")) %>%
mutate(TI=if_else(ENTREZID %in% motif_TI,"y","no")) %>%
mutate(NR=if_else(ENTREZID %in% motif_NR,"y","no")) %>%
mutate(crisp = if_else(ENTREZID %in% crisprunique$entrezgene_id, "y", "no")) %>%
group_by(crisp,ER,TI,LR,NR) %>%
dplyr::summarize(n=n()) %>%
as.tibble %>%
pivot_wider(id_cols = c(crisp), names_from = c('ER', 'TI', 'LR', 'NR'), values_from= n) %>%
rename(.,c("crisp"=crisp,"none"= 2 , "ER" = 3 , "TI" = 4 , "LR" = 5 ,"NR" = 6))
cris_mat <- crispmotifsummary %>% dplyr::select(ER:NR) %>% as.matrix()
chicheck <- data.frame(one= c("LR","ER","TI"),two=rep("NR",3),p.value=c("","",""))
chicheck$p.value[1] <- chisq.test(cris_mat[,c('LR','NR')],correct = FALSE)$p.value
chicheck$p.value[2] <- chisq.test(cris_mat[,c('ER','NR')],correct = FALSE)$p.value
chicheck$p.value[3] <- chisq.test(cris_mat[,c('TI','NR')],correct = FALSE)$p.value
chicheck%>% kable(., caption= "chi square test p.values for encrichment of Doxcrispr gene sets in motif sets" )%>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| one | two | p.value |
|---|---|---|
| LR | NR | 0.861985991471947 |
| ER | NR | 0.402681880154749 |
| TI | NR | 0.309642007916355 |
chicheck_1 <- chicheck %>% mutate(p.value=as.numeric(p.value)) %>%
mutate(neg.logvalue=(-1*log(p.value))) %>% column_to_rownames('one') %>% dplyr::select(neg.logvalue) %>% as.matrix
col_fun = circlize::colorRamp2(c(0, 2), c("white", "purple"))
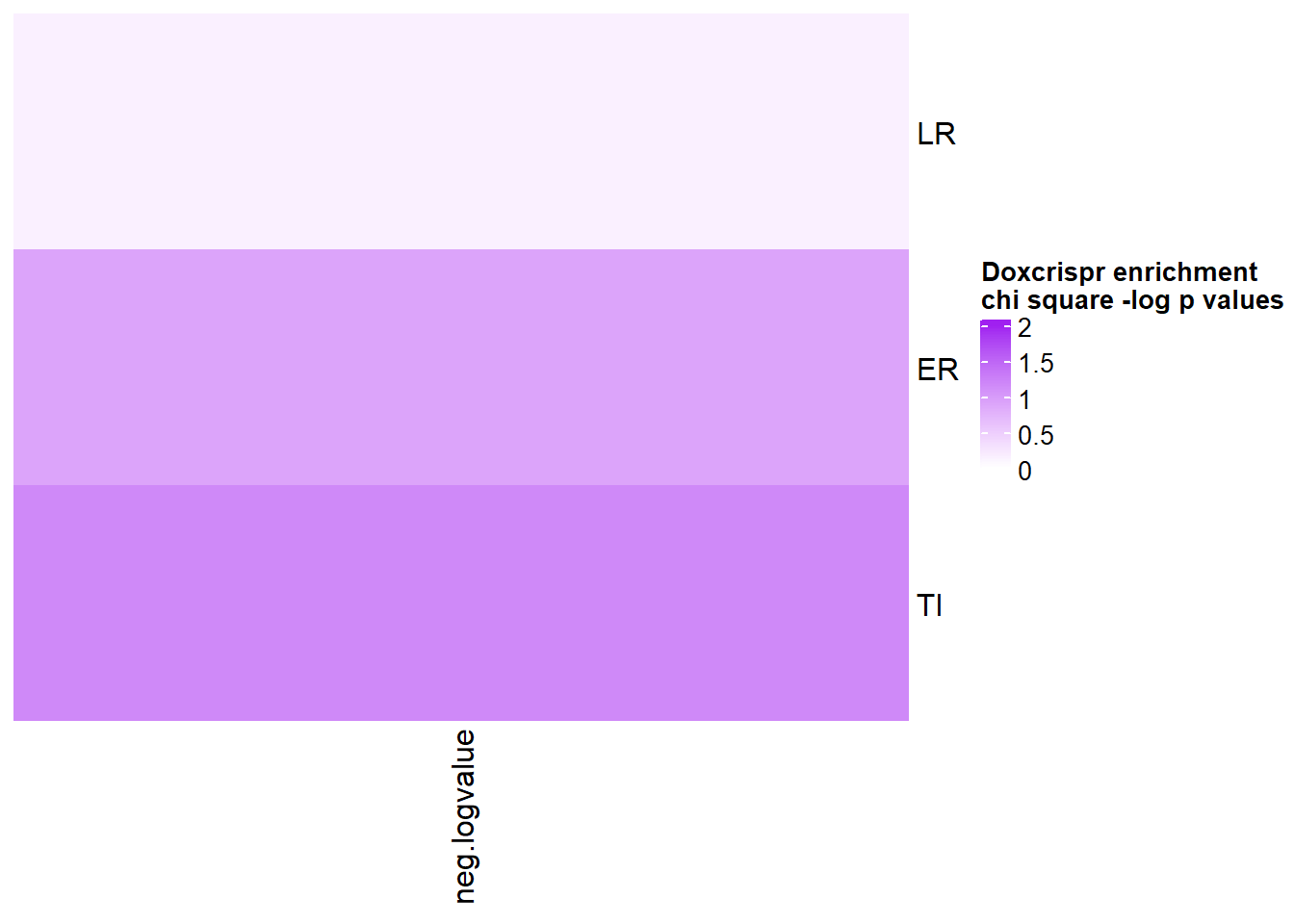
Heatmap( chicheck_1, name = "Doxcrispr enrichment \nchi square -log p values", cluster_rows = FALSE, cluster_columns = FALSE, col=col_fun,
cell_fun = function(j, i, x, y, width, height, fill) {
if(chicheck_1[i, j] > -log(0.05))
grid.text("*", x, y, gp = gpar(fontsize = 20))
})
col_fun4 = circlize::colorRamp2(c(0, 5), c("white", "purple"))
pairwisecrispr <- toplistall %>%
filter(id!='Trastuzumab') %>%
mutate(id = as.factor(id)) %>%
mutate(time=factor(time, levels=c("3_hours","24_hours"))) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(crisp = if_else(ENTREZID %in% crisprunique$entrezgene_id, "y", "no")) %>%
group_by(time, id) %>%
summarise(pvalue= chisq.test(crisp, sigcount, correct=FALSE)$p.value)
crisprnumbers <- toplistall %>%
filter(id!='Trastuzumab') %>%
mutate(id = as.factor(id)) %>%
mutate(time=factor(time, levels=c("3_hours","24_hours"))) %>%
mutate(sigcount = if_else(adj.P.Val <0.05,'sig','notsig'))%>%
mutate(crisp = if_else(ENTREZID %in% crisprunique$entrezgene_id, "y", "no")) %>%
group_by(time, id,sigcount,crisp) %>%
dplyr::summarize(n=n()) %>%
as.tibble() #%>%
crisprnumbers %>% kable(., caption= "Summary of genes found in both sigDE and non sigDE by treatment" )%>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| time | id | sigcount | crisp | n |
|---|---|---|---|---|
| 3_hours | Daunorubicin | notsig | no | 13414 |
| 3_hours | Daunorubicin | notsig | y | 115 |
| 3_hours | Daunorubicin | sig | no | 553 |
| 3_hours | Daunorubicin | sig | y | 2 |
| 3_hours | Doxorubicin | notsig | no | 13951 |
| 3_hours | Doxorubicin | notsig | y | 117 |
| 3_hours | Doxorubicin | sig | no | 16 |
| 3_hours | Epirubicin | notsig | no | 13749 |
| 3_hours | Epirubicin | notsig | y | 115 |
| 3_hours | Epirubicin | sig | no | 218 |
| 3_hours | Epirubicin | sig | y | 2 |
| 3_hours | Mitoxantrone | notsig | no | 13909 |
| 3_hours | Mitoxantrone | notsig | y | 117 |
| 3_hours | Mitoxantrone | sig | no | 58 |
| 24_hours | Daunorubicin | notsig | no | 7165 |
| 24_hours | Daunorubicin | notsig | y | 55 |
| 24_hours | Daunorubicin | sig | no | 6802 |
| 24_hours | Daunorubicin | sig | y | 62 |
| 24_hours | Doxorubicin | notsig | no | 7512 |
| 24_hours | Doxorubicin | notsig | y | 56 |
| 24_hours | Doxorubicin | sig | no | 6455 |
| 24_hours | Doxorubicin | sig | y | 61 |
| 24_hours | Epirubicin | notsig | no | 7825 |
| 24_hours | Epirubicin | notsig | y | 57 |
| 24_hours | Epirubicin | sig | no | 6142 |
| 24_hours | Epirubicin | sig | y | 60 |
| 24_hours | Mitoxantrone | notsig | no | 12652 |
| 24_hours | Mitoxantrone | notsig | y | 105 |
| 24_hours | Mitoxantrone | sig | no | 1315 |
| 24_hours | Mitoxantrone | sig | y | 12 |
pairwisecrispr%>% kable(., caption= "Summary of chisqure values between numbers of sigDE and non sigDE by treatment" )%>%
kable_paper("striped", full_width = FALSE) %>%
kable_styling(full_width = FALSE, position = "left",bootstrap_options = c("striped"),font_size = 18) %>%
scroll_box(width = "60%", height = "400px")| time | id | pvalue |
|---|---|---|
| 3_hours | Daunorubicin | 0.2128915 |
| 3_hours | Doxorubicin | 0.7141341 |
| 3_hours | Epirubicin | 0.8973055 |
| 3_hours | Mitoxantrone | 0.4848796 |
| 24_hours | Daunorubicin | 0.3551194 |
| 24_hours | Doxorubicin | 0.2008692 |
| 24_hours | Epirubicin | 0.1128575 |
| 24_hours | Mitoxantrone | 0.7563882 |
crisp_pair_mat <- pairwisecrispr %>%
mutate(neg.log.pvalue= (-1*log(pvalue))) %>%
mutate(time= case_match(time, '3_hours'~'3_hrs', '24_hours'~'24_hrs',.default = id)) %>%
mutate(id =case_match( id, 'Daunorubicin'~'DNR', 'Doxorubicin'~'DOX' ,'Epirubicin'~'EPI' , 'Mitoxantrone' ~ 'MTX',.default = id)) %>%
unite('pairset',time,id ) %>%
column_to_rownames('pairset') %>% dplyr::select(neg.log.pvalue) %>% as.matrix()
Heatmap( crisp_pair_mat, name = "Doxcrispr pairwise enrichment \nchi square -log p values",
cluster_rows = FALSE,
cluster_columns = FALSE,
col=col_fun5, column_names_rot = 0,
cell_fun = function(j, i, x, y, width, height, fill) {
if(crisp_pair_mat[i, j] > -log(0.05))
grid.text("*", x, y, gp = gpar(fontsize = 20))
})
sessionInfo()R version 4.2.2 (2022-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19045)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ComplexHeatmap_2.12.1 broom_1.0.5 kableExtra_1.3.4
[4] sjmisc_2.8.9 scales_1.2.1 ggpubr_0.6.0
[7] cowplot_1.1.1 RColorBrewer_1.1-3 biomaRt_2.52.0
[10] ggsignif_0.6.4 lubridate_1.9.2 forcats_1.0.0
[13] stringr_1.5.0 dplyr_1.1.2 purrr_1.0.1
[16] readr_2.1.4 tidyr_1.3.0 tibble_3.2.1
[19] ggplot2_3.4.2 tidyverse_2.0.0 limma_3.52.4
[22] workflowr_1.7.0
loaded via a namespace (and not attached):
[1] colorspace_2.1-0 rjson_0.2.21 sjlabelled_1.2.0
[4] rprojroot_2.0.3 circlize_0.4.15 XVector_0.36.0
[7] GlobalOptions_0.1.2 fs_1.6.2 clue_0.3-64
[10] rstudioapi_0.14 farver_2.1.1 bit64_4.0.5
[13] AnnotationDbi_1.58.0 fansi_1.0.4 xml2_1.3.4
[16] codetools_0.2-19 doParallel_1.0.17 cachem_1.0.8
[19] knitr_1.43 jsonlite_1.8.5 cluster_2.1.4
[22] dbplyr_2.3.2 png_0.1-8 compiler_4.2.2
[25] httr_1.4.6 backports_1.4.1 fastmap_1.1.1
[28] cli_3.6.1 later_1.3.1 htmltools_0.5.5
[31] prettyunits_1.1.1 tools_4.2.2 gtable_0.3.3
[34] glue_1.6.2 GenomeInfoDbData_1.2.8 rappdirs_0.3.3
[37] Rcpp_1.0.10 carData_3.0-5 Biobase_2.56.0
[40] jquerylib_0.1.4 vctrs_0.6.3 Biostrings_2.64.1
[43] svglite_2.1.1 iterators_1.0.14 insight_0.19.2
[46] xfun_0.39 ps_1.7.5 rvest_1.0.3
[49] timechange_0.2.0 lifecycle_1.0.3 rstatix_0.7.2
[52] XML_3.99-0.14 getPass_0.2-2 zlibbioc_1.42.0
[55] hms_1.1.3 promises_1.2.0.1 parallel_4.2.2
[58] yaml_2.3.7 curl_5.0.1 memoise_2.0.1
[61] sass_0.4.6 stringi_1.7.12 RSQLite_2.3.1
[64] highr_0.10 S4Vectors_0.34.0 foreach_1.5.2
[67] BiocGenerics_0.42.0 filelock_1.0.2 shape_1.4.6
[70] GenomeInfoDb_1.32.4 matrixStats_1.0.0 rlang_1.1.1
[73] pkgconfig_2.0.3 systemfonts_1.0.4 bitops_1.0-7
[76] evaluate_0.21 labeling_0.4.2 bit_4.0.5
[79] processx_3.8.1 tidyselect_1.2.0 magrittr_2.0.3
[82] R6_2.5.1 IRanges_2.30.1 generics_0.1.3
[85] DBI_1.1.3 pillar_1.9.0 whisker_0.4.1
[88] withr_2.5.0 KEGGREST_1.36.3 abind_1.4-5
[91] RCurl_1.98-1.12 crayon_1.5.2 car_3.1-2
[94] utf8_1.2.3 BiocFileCache_2.4.0 tzdb_0.4.0
[97] rmarkdown_2.22 GetoptLong_1.0.5 progress_1.2.2
[100] blob_1.2.4 callr_3.7.3 git2r_0.32.0
[103] digest_0.6.31 webshot_0.5.4 httpuv_1.6.11
[106] stats4_4.2.2 munsell_0.5.0 viridisLite_0.4.2
[109] bslib_0.5.0