Source for Figures
Thomas Bataillon
12/9/2020 Last update:(last update 2021-06-25)
Last updated: 2021-06-25
Checks: 6 1
Knit directory: delta-sift-polydfe/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of the R Markdown file created these results, you’ll want to first commit it to the Git repo. If you’re still working on the analysis, you can ignore this warning. When you’re finished, you can run wflow_publish to commit the R Markdown file and build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210313) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 593f3c8. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.Rhistory
Ignored: analysis/figure/
Untracked files:
Untracked: FigsMay2021/
Untracked: data/summary_table_v3.txt
Untracked: eps_vs_delta.pdf
Untracked: eps_vs_lognsyn_counts.pdf
Untracked: flux_benef_vsdelta.pdf
Untracked: pb_versus_delta.pdf
Unstaged changes:
Deleted: analysis/S1_Stat_models_deltaDIFT_DFEs.Rmd
Modified: analysis/S1_Stat_models_deltaSIFT_DFEs.Rmd
Modified: analysis/S2_Summary_Figure_deltaSIFT_DFEs.Rmd
Modified: analysis/_site.yml
Modified: analysis/license.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/S2_Summary_Figure_deltaSIFT_DFEs.Rmd) and HTML (docs/S2_Summary_Figure_deltaSIFT_DFEs.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 593f3c8 | Thomas Bataillon | 2021-03-20 | Build site. |
| html | 52a94dd | Thomas Bataillon | 2021-03-20 | Build site. |
| Rmd | 3fe9d78 | Thomas Bataillon | 2021-03-20 | Publish the initial files + S1 & S2 + readme for myproject |
| html | 040ba4c | Thomas Bataillon | 2021-03-13 | Build site. |
| html | afad139 | Thomas Bataillon | 2021-03-13 | Build site. |
| html | 343029d | Thomas Bataillon | 2021-03-13 | Build site. |
| html | 706a03c | Thomas Bataillon | 2021-03-13 | Build site. |
| Rmd | 6ef954c | Thomas Bataillon | 2021-03-13 | wflow_git_commit(files = "analysis/*.Rmd") |
brief overview of analysis and updates :
We read in the data made available in the lastest version of the polyDFE outputs summary by Jun Chen.
We define a covariate \(\delta\) as the change in discretized SIFT scores
We filter away the cases where \(\epsilon_{anc}\) is too big
Rationale for conditioning DFE on \(\delta\) is to illustrate that change in SIFT scores are a powerful way to capture the expected effect of mutations and the fact that DFEs are quite different and there is a consistent change in the DFEs and this change is well captured by although there is not a neat/sharp divide between \(\delta \leq 0\) and \(\delta >0\)
Reading the data
dfe_sift <- read.table("data/summary_table_v3.txt",header=T)
dim(dfe_sift)[1] 322 28names(dfe_sift) [1] "species" "group" "category" "fold" "from"
[6] "to" "delta" "PiS" "PiN" "PiNPiS"
[11] "syn_counts" "nsyn_counts" "Lsyn" "Lnsyn" "TD4"
[16] "TD0" "GC3" "gradient" "eps" "Sd"
[21] "beta" "pb" "Sb" "alpha" "D1"
[26] "D2" "D3" "D4" dfe_sift$delta <- dfe_sift$to - dfe_sift$fromTechnical check: distribution of \(\epsilon_{anc}\)
A few species have a high estimated error epsilon_anc rate of SNP orientation and I think that all inference with eps> 0.2 should hardly be trusted , so these are filtered out.
qplot(log10(dfe_sift$eps), bins=20) + xlab("rate of SNP polarization error (eps_anc)")+theme_minimal(base_size = 16)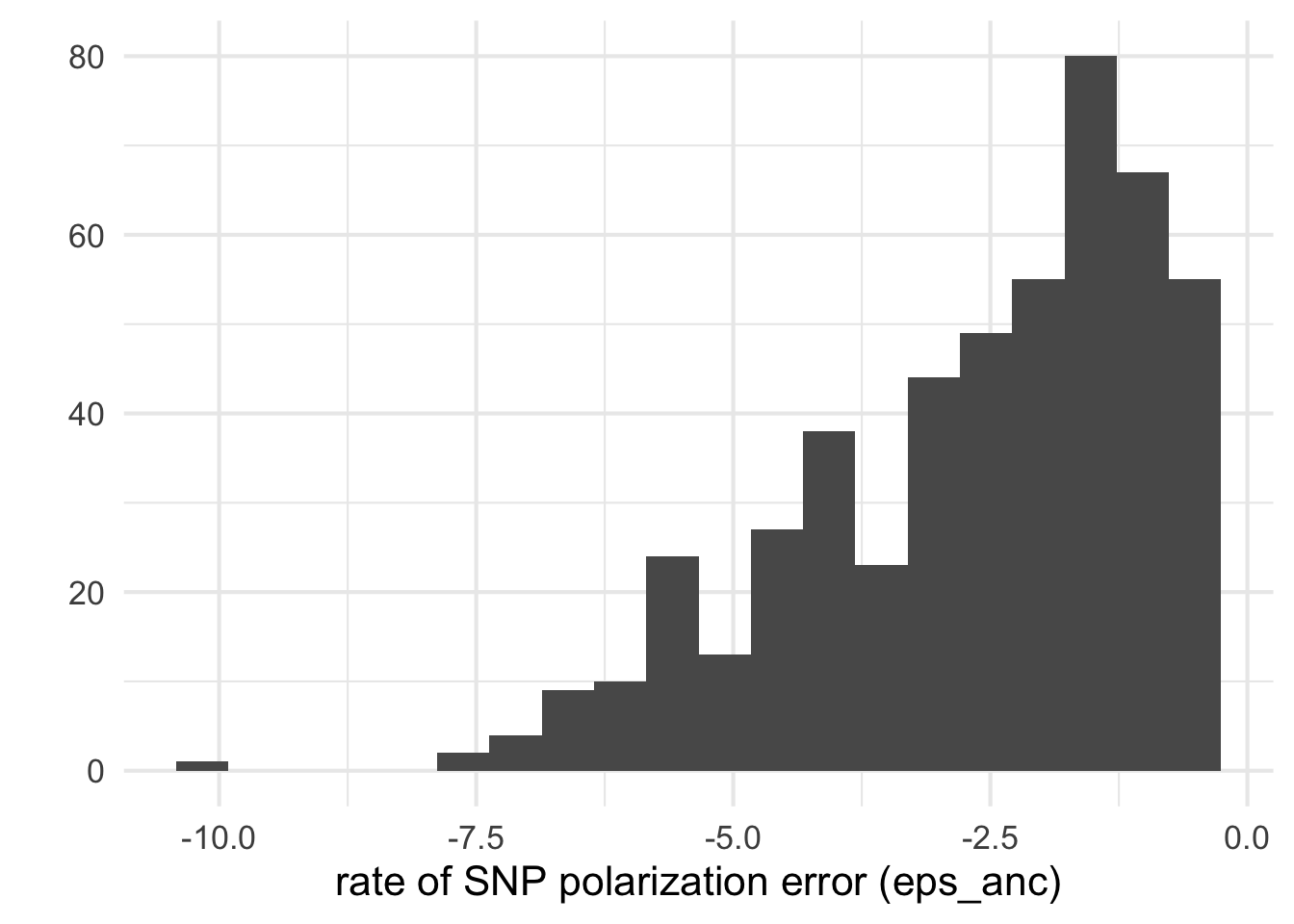
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
names(dfe_sift) [1] "species" "group" "category" "fold" "from"
[6] "to" "delta" "PiS" "PiN" "PiNPiS"
[11] "syn_counts" "nsyn_counts" "Lsyn" "Lnsyn" "TD4"
[16] "TD0" "GC3" "gradient" "eps" "Sd"
[21] "beta" "pb" "Sb" "alpha" "D1"
[26] "D2" "D3" "D4" dfe_sift %>%
filter(nsyn_counts>100) %>%
ggplot(aes(x= log10(nsyn_counts),
y = log10(eps+0.000001),
weight=sqrt(1+nsyn_counts))) +
geom_point(aes(color = delta<0), size=0.6) +
ylab("SNP polarization error, log10(eps)")+
geom_smooth(method="loess", color= "cornflowerblue", span=0.75, se=T)+
xlab("SFS sample size, log10( non-syn. counts in SFS)")+
scale_color_colorblind()+
theme_cowplot(font_size = 17)+
theme(legend.position = c(0.7,0.9))+
theme(legend.background = element_rect("white"))+
ggsave2(filename = "eps_vs_lognsyn_counts.pdf", device = "pdf")+
NULLSaving 7 x 5 in image`geom_smooth()` using formula 'y ~ x'
`geom_smooth()` using formula 'y ~ x'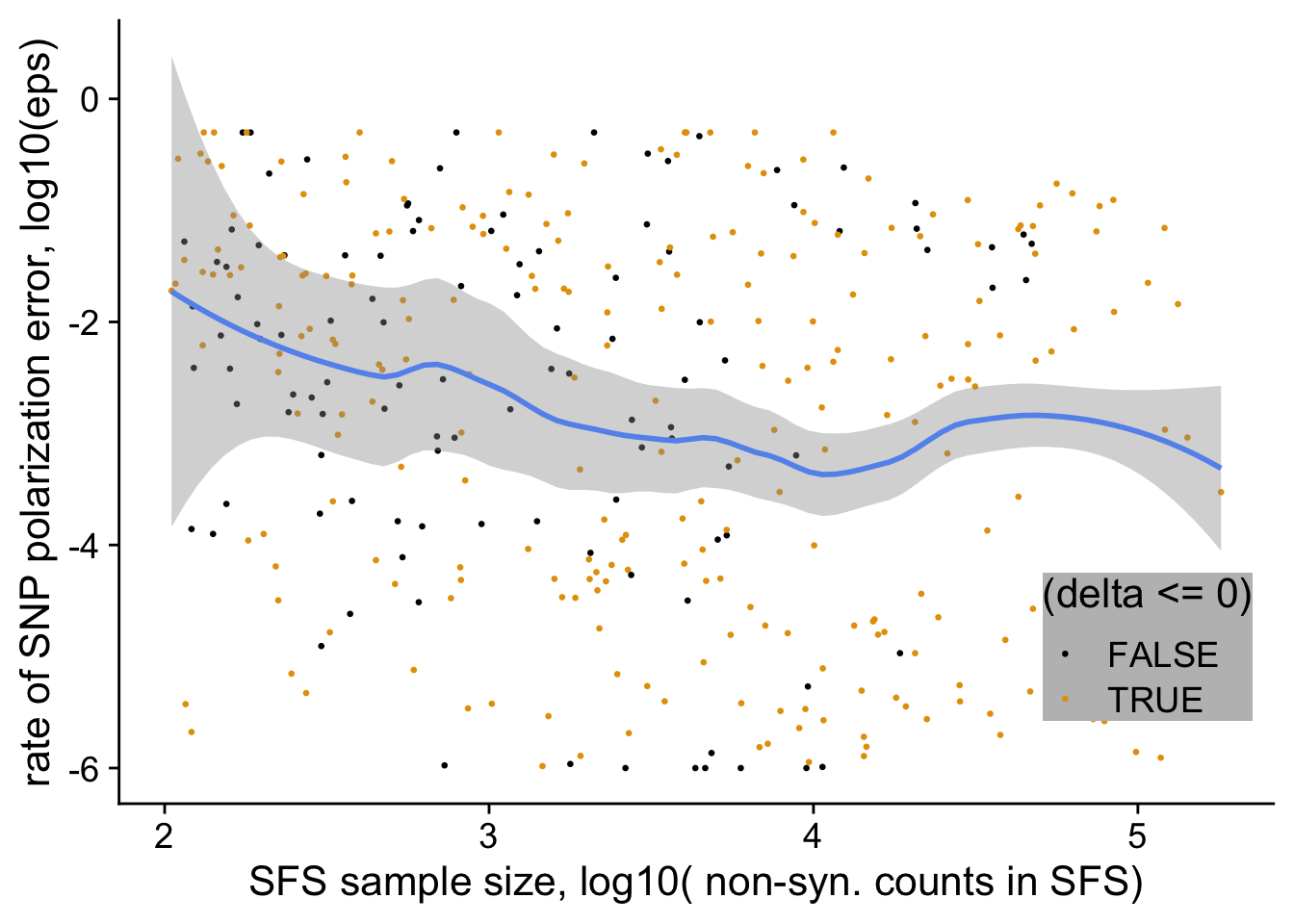
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
dfe_sift %>%
filter(nsyn_counts>100) %>%
ggplot(aes(x=delta, y = log10(eps + 0.000001), size = sqrt(nsyn_counts), weight=sqrt(1+nsyn_counts) ))+
geom_jitter(height = 0,width = 0.2, color="grey80")+
geom_smooth(method = "loess", aes(color = NULL), color = "black")+
# geom_smooth(method = "lm", aes(color = NULL), color = "black", se =T)+
geom_abline(intercept = log10(0.1), slope=0, color ="red")+
theme_cowplot(font_size = 17)+
# facet_wrap(~group)+
theme(legend.position = "none")+
xlab(expression(delta))+
ylab("SNP polarization error, log10(eps)")+
scale_size("counts in n-syn SFS", range=c(1,4))+
ggsave2(filename = "eps_vs_delta.pdf", device = "pdf")+
NULLSaving 7 x 5 in image`geom_smooth()` using formula 'y ~ x'
`geom_smooth()` using formula 'y ~ x'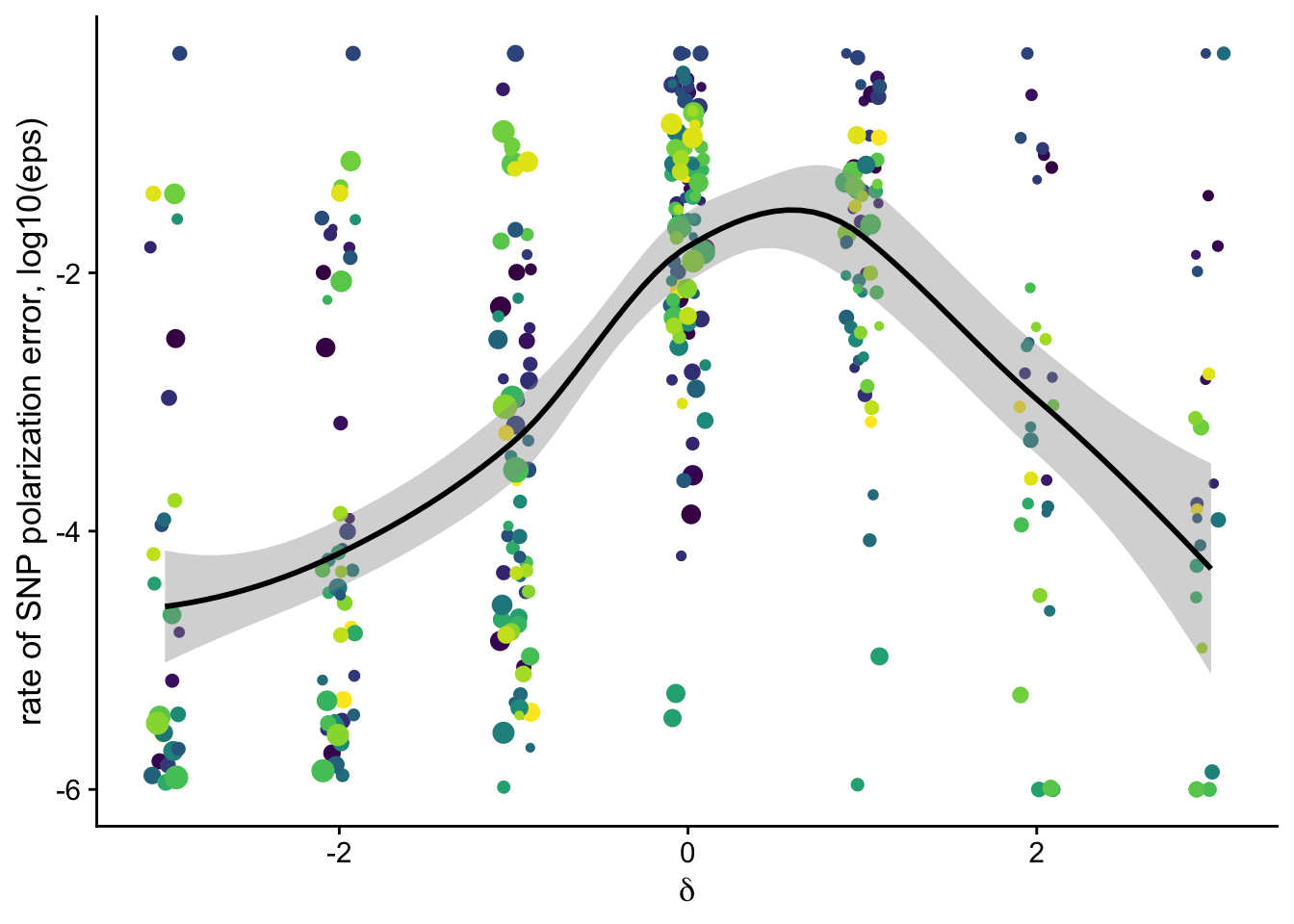
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
Filtering data before figure
We exclude:
* the \(\epsilon_{anc}\) > 0.1 * the number of chromosomes in the sfs < 6 species_low_nchr(manually curated list below)
unique(dfe_sift$species) [1] "Qa" "Qv" "Qd" "Ayan" "Cjapon" "Did" "Dis" "Laca"
[9] "Lfor" "Peu" "Pil" "Pru" "Pnig" "Ptrich" "Bpend" "Aly"
[17] "Atha" "Sbic" "Cgr" "Crub" "Shab" "Zmay" species_low_nchr <- c("Qmango", "Shua", "Bnana")
dfe_sift <- dfe_sift %>%
filter(!(species %in% species_low_nchr)) %>%
filter(eps <0.1) #
dim(dfe_sift)[1] 322 28The Flux of beneficial mutations \(p_b s_b\)
Detecting beneficial mutations is notoriously difficult as they are expected to be overall quite rare and therefore make a modest contribution to SFS counts. But \(\delta\) is a very relevant covariate Among the classes of mutations categorized as likely deleterious (negative \(\delta\)) we have virtually zero flux of beneficial mutations; but as \(\delta\) increases, so does the flux of beneficial mutations \(p_b S_b\):
the Flux \(p_b*S_b\)
Sylvain: The same but in log-scale
dfe_sift %>%
ggplot(aes(x=delta, y=pb*Sb, weight = sqrt(1+nsyn_counts))) +
# geom_point(aes(size = nsyn_counts))+
geom_jitter(height = 0, width = 0.1, aes(size = sqrt(1+nsyn_counts)), color="grey40")+
scale_y_log10() +
# facet_wrap(~ group) +
geom_smooth(method = "loess", formula ="y~ x", se =T, aes(color = NULL), color = "black")+
theme_minimal(base_size = 15)+
xlab(expression(delta))+
ylab("Flux of beneficial mutation: pb*Sb")+
scale_color_viridis_d()+
theme(legend.position = "none")+
ggsave2(filename = "flux_benef_vsdelta.pdf", device = "pdf")+
NULLSaving 7 x 5 in image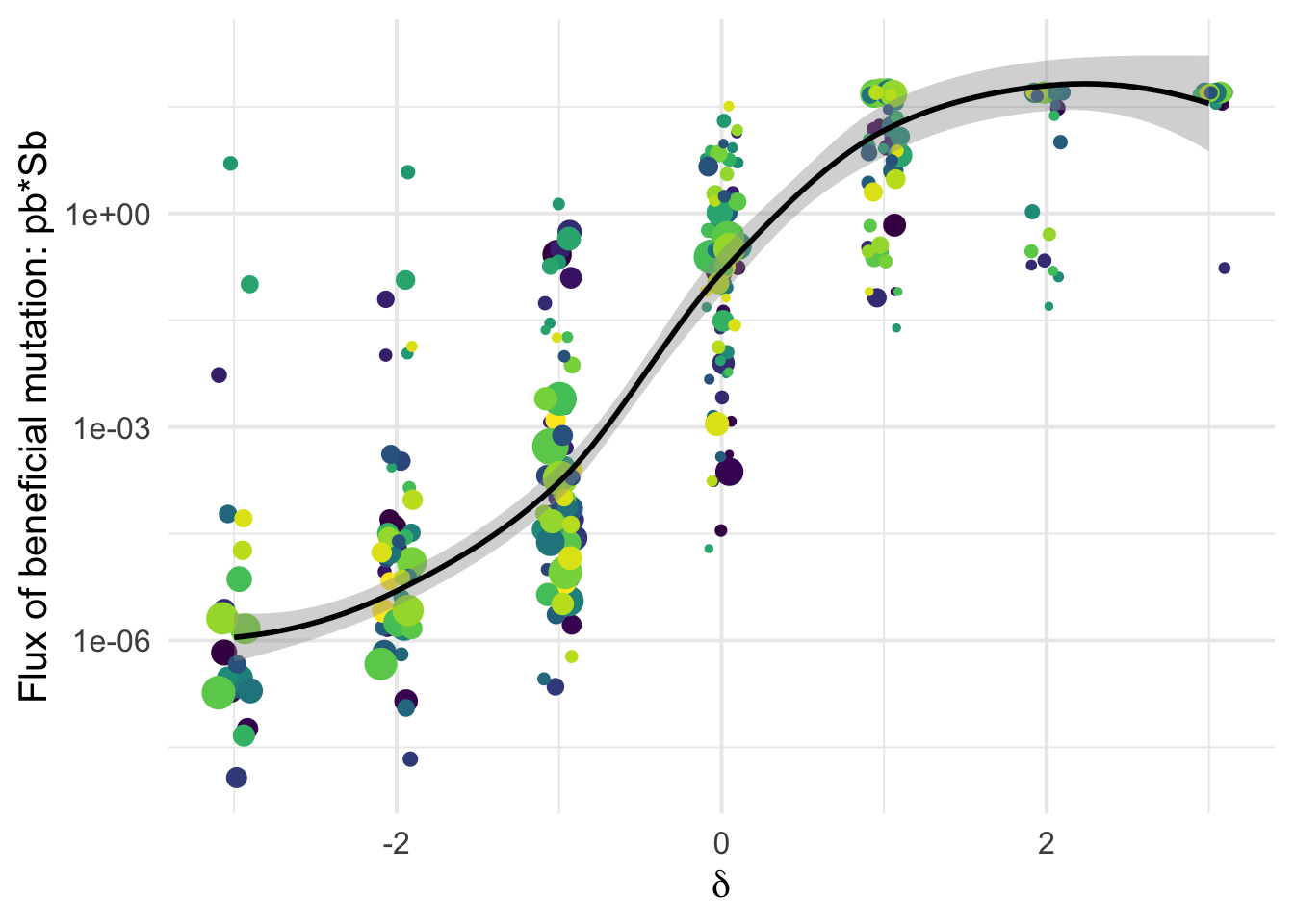
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
the mere proportion \(p_b\)
Nb We dot not add a “trend fitting curve” as these get often into negative value which makes the figure confusing.
Sylvain: The same but in log-scale
dfe_sift %>%
ggplot(aes(x=delta, y=pb, weight = 1+nsyn_counts)) +
# geom_point(aes(size = nsyn_counts))+
geom_jitter(height = 0, width = 0.1, aes(size = sqrt(1+nsyn_counts)))+
# facet_wrap(~ group) +
geom_smooth(method = "glm", formula = y ~ x, se =T, aes(color = NULL), color = "black", method.args=list(family="binomial") )+
theme_minimal(base_size = 15)+
xlab(expression(delta))+
ylab("proportion of beneficial mutations")+
scale_color_viridis_d()+
theme(legend.position = "none")+
ggsave2(filename = "pb_versus_delta.pdf",device = "pdf")+
NULLSaving 7 x 5 in image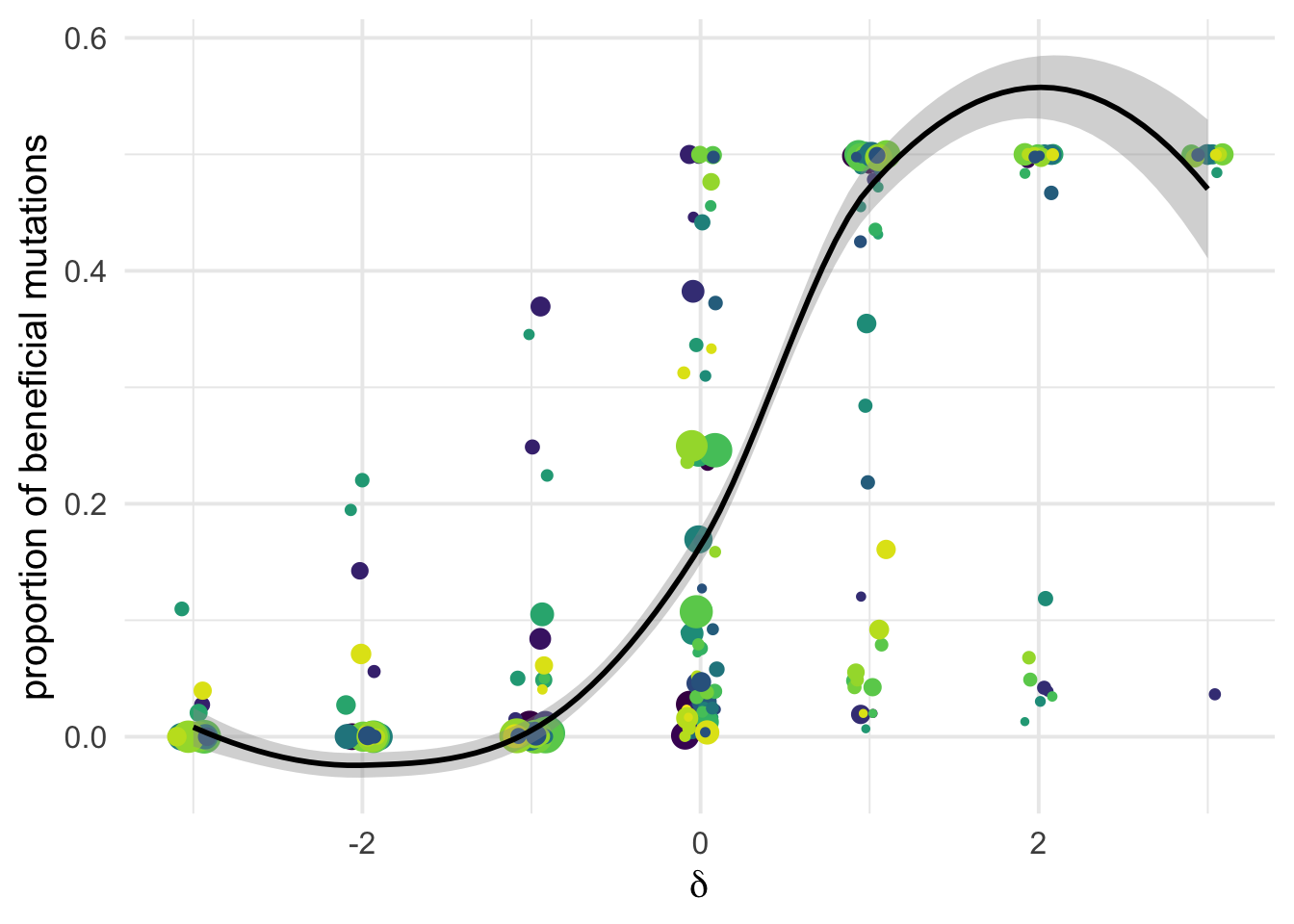
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
Binning of DFE by \(N_e s\)
Poportion of mutations in Nes classes
We can see that conditioning on the \(\delta\) covariates is very informative: there is a strong covariation between the proportion of mutations in Ne*s classes inferred via polyDFE and the perceived functional categories as obtained via SIFT:
dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(x=delta, y= D1, weight= 1+nsyn_counts)) +
geom_point(aes(size = nsyn_counts ))+
# facet_wrap(~ group) +
# geom_smooth(method = "glm", formula ="y~ x", se =T, color="black", method.args=list(family="binomial") )+
theme_minimal(base_size = 17)+
xlab(expression(delta))+
ylab("prop in Nes[0-1]")+
scale_color_viridis_d()+
theme(legend.position = "none")+
NULL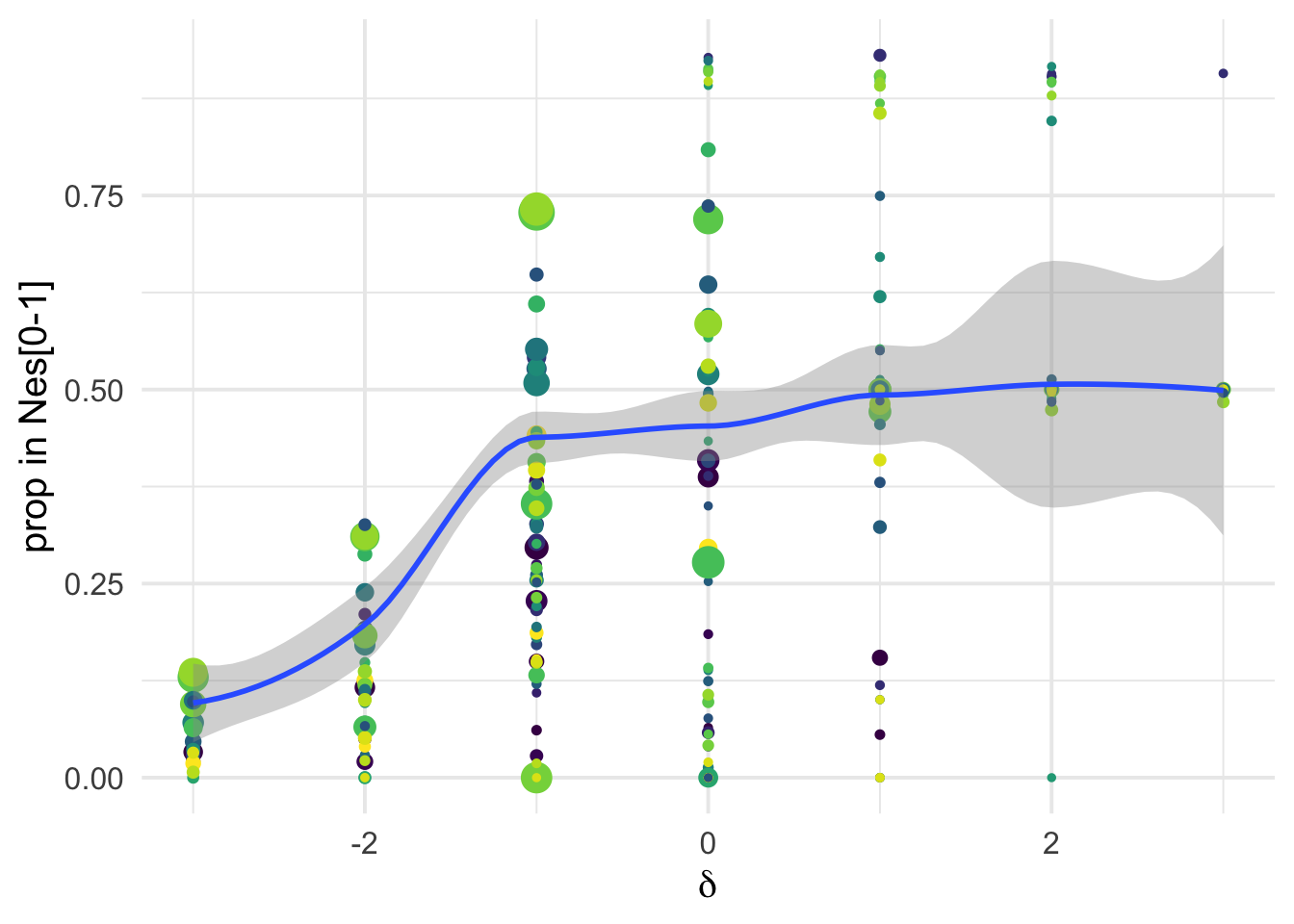
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(x=delta, y= D2, weight= 1+nsyn_counts)) +
geom_point(aes(size = nsyn_counts))+
# facet_wrap(~ group) +
geom_smooth(method = "glm", formula ="y~ x", se =T, color="black")+
theme_minimal(base_size = 17)+
xlab(expression(delta))+
ylab("prop in Nes[-1, -10]")+
scale_color_viridis_d()+
theme(legend.position = "none")+
NULL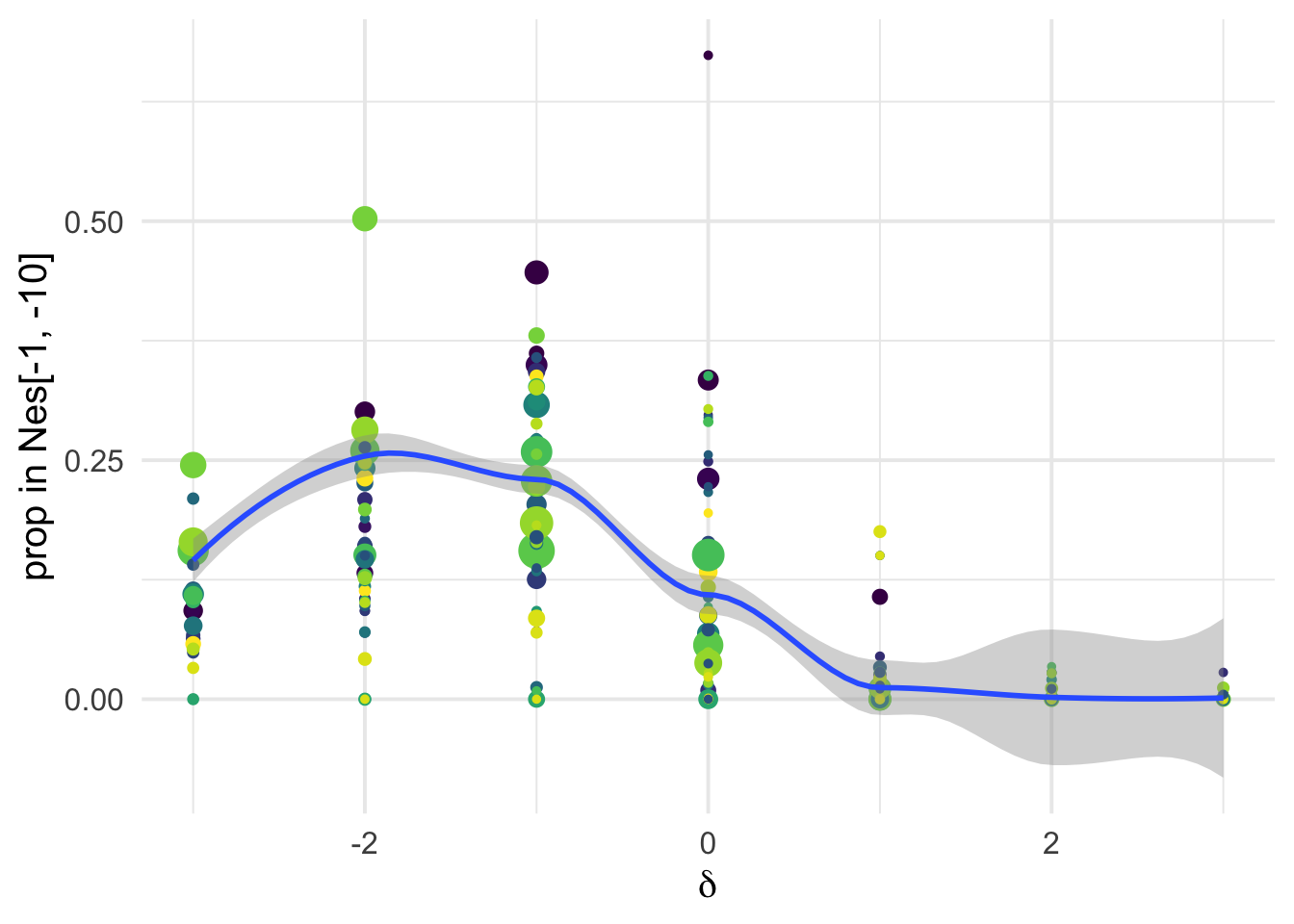
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(x=delta, y= D3, weight= 1+nsyn_counts)) +
geom_point(aes(size = nsyn_counts))+
# facet_wrap(~ group) +
geom_smooth(method = "glm", formula ="y~ x", se =T)+
theme_minimal(base_size = 17)+
xlab(expression(delta))+
ylab("prop in Nes[-10, -100]")+
scale_color_viridis_d()+
theme(legend.position = "none")+
NULL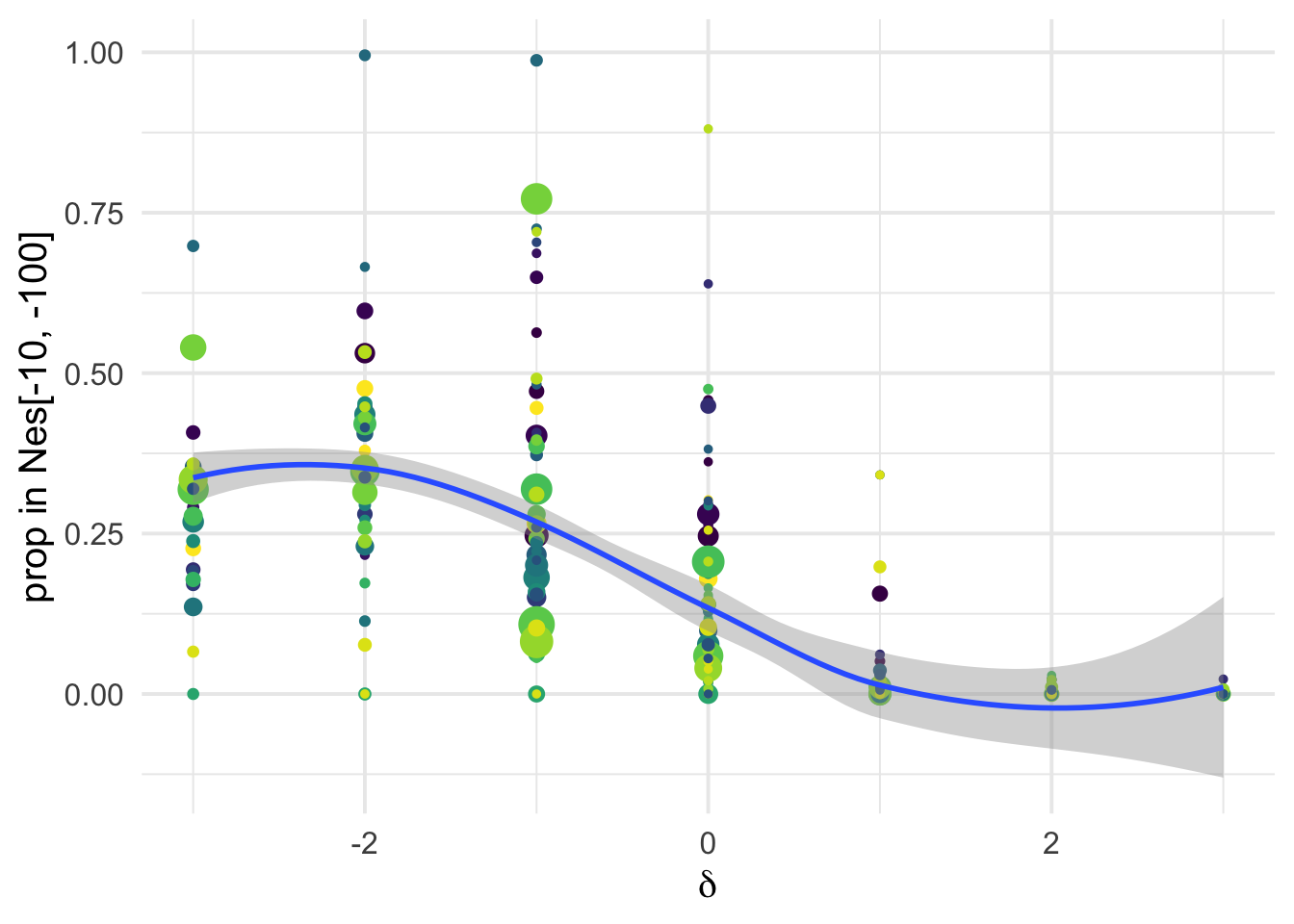
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(x=delta, y= D4, weight= 1+nsyn_counts)) +
geom_point(aes(size = nsyn_counts))+
# facet_wrap(~ group) +
# geom_smooth(method = "loess", formula ="y~ x", se =T)+
theme_minimal(base_size = 15)+
xlab(expression(delta))+
ylab("prop in Nes[- 100 -...]")+
scale_color_viridis_d()+
theme(legend.position = "none")+
NULL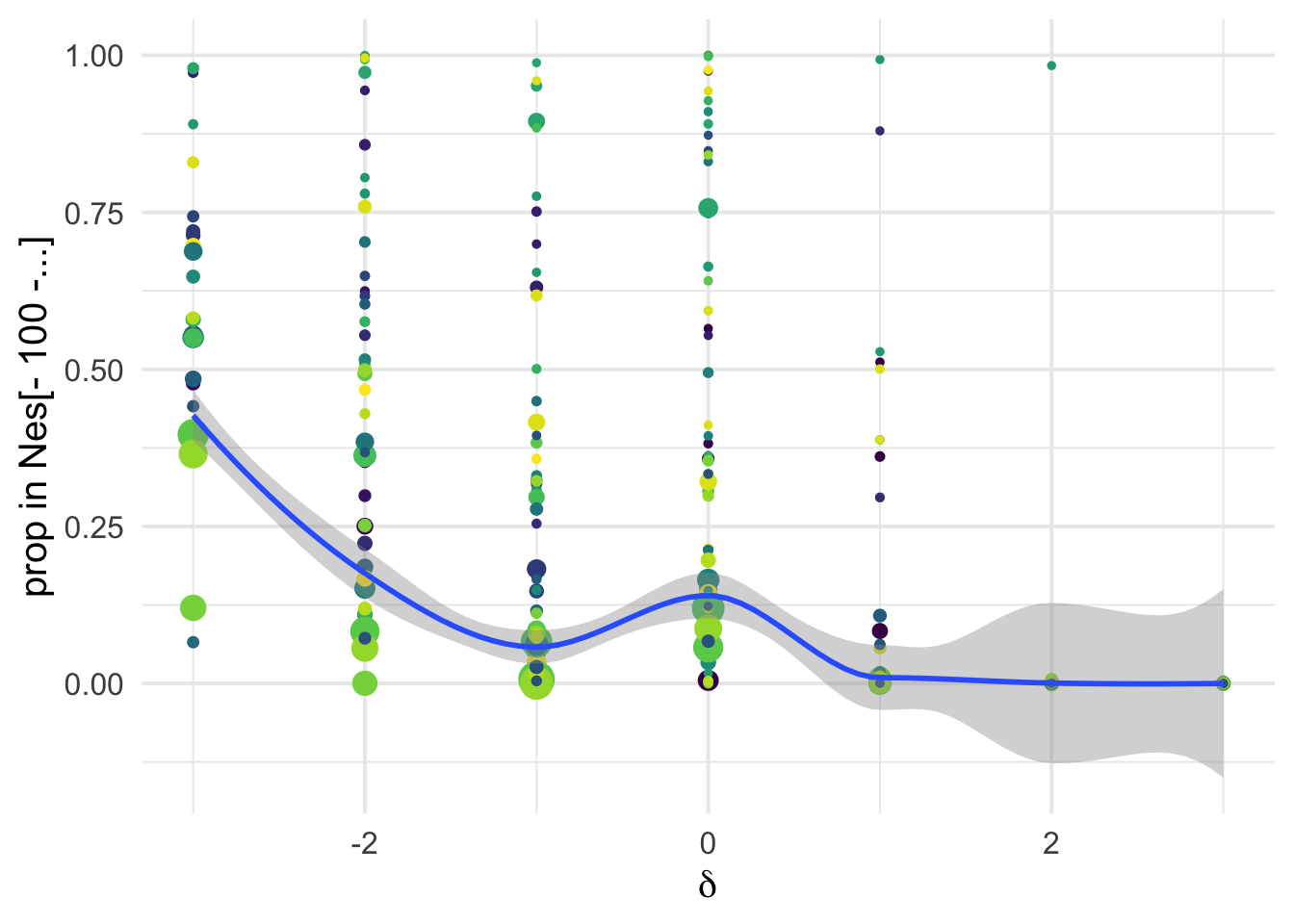
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
Overall figure combining
Fig Legend, each line denotes the proportion of mutations in the DFE that are beneficial (orange) or that are (increasingly) deleterious mutations : D1 ( Nes in 0-1) in light grey, D2 (Nes in 1-10) dark grey, D3(10-100 blue), D4+D5(Nes > 100) red.
fig_overview <- dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(weight= 1+nsyn_counts)) +
# geom_point(aes(size = nsyn_counts, color=species ))+
# facet_wrap(~ group) +
geom_smooth(aes(x=delta, y= D1), method = "loess", formula ="y~ x", se =F, color="grey90", span =0.5)+
geom_smooth(aes(x=delta, y= D2), method = "loess", formula ="y~ x", se =F, color = "grey70", span = 0.5)+
# geom_smooth(aes(x=delta, y= D3), method = "loess", formula ="y~ x", se =F, color = "cornflowerblue", span = 0.5)+
geom_smooth(aes(x=delta, y= D3 +D4), method = "loess", formula ="y~ x", se =F, color = "red", span=0.5)+
geom_smooth(aes(x=delta, y= pb), method = "loess", formula ="y~ x", se =F, color = "orange", span=0.5)+
theme_cowplot(font_size = 17)+
xlab(expression(delta))+
ylab("proportion per in Nes class")+
scale_color_viridis_d()+
theme(legend.position = "none")+
NULL
plot(fig_overview)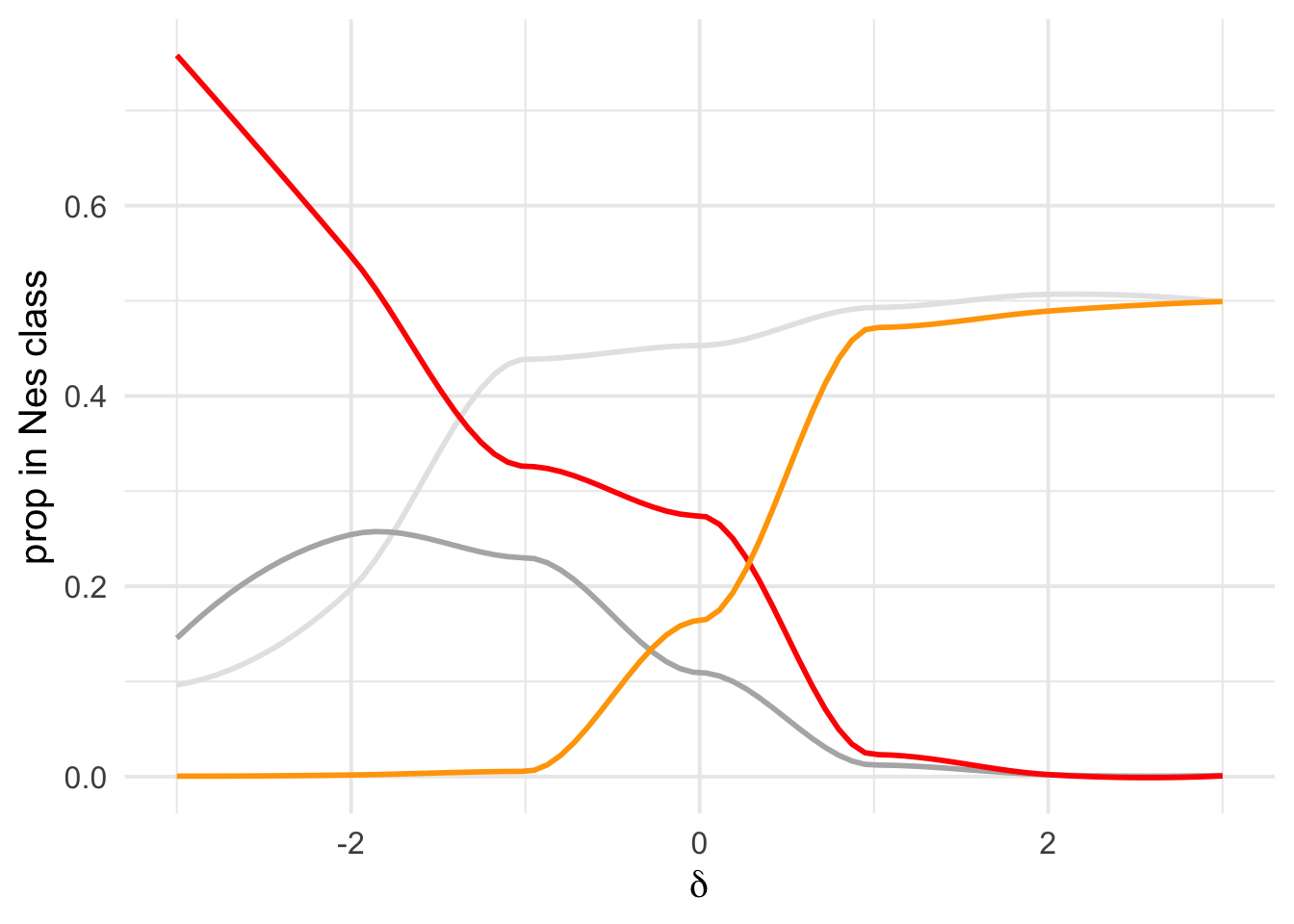
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
ggsave(plot = fig_overview, filename = "overview_dfe_bins_ByDelta.pdf", "pdf")Saving 7 x 5 in imagePiN/PiS corrected
Another representation by adding +1 to every count: \(\pi_N =\frac{n_N + 1}{L_N + 1}\) and \(\pi_S =\frac{n_S + 1}{L_S + 1}\) we can then directly use a log scale
dfe_sift$PiNPiScor <- (dfe_sift$nsyn_counts+1)*(dfe_sift$Lsyn+1)/((dfe_sift$Lnsyn+1)*(dfe_sift$syn_counts+1))
dfe_sift %>%
# filter(cat04==0) %>%
ggplot(aes(x=delta, y=PiNPiScor, weight=(1+nsyn_counts)) )+
# geom_point(aes(size = nsyn_counts)) +
geom_jitter(width = 0.1, aes(size = nsyn_counts)) +
scale_y_log10() +
# facet_wrap(~ group) +
geom_smooth(method = "loess", formula = y ~ x, se =T, aes(color = NULL), color = "black", span=0.5 )+
# geom_smooth(method = "loess", formula ="y~ x", se =T)+
theme_cowplot(font_size = 15)+
xlab("Delta SIFT score")+
ylab("corrected piN/piS")+
scale_color_viridis_d()+
theme(legend.position = "none")+
# ggsave2("pin_pis_corrected_vs_delta.png", device = "png")+
NULL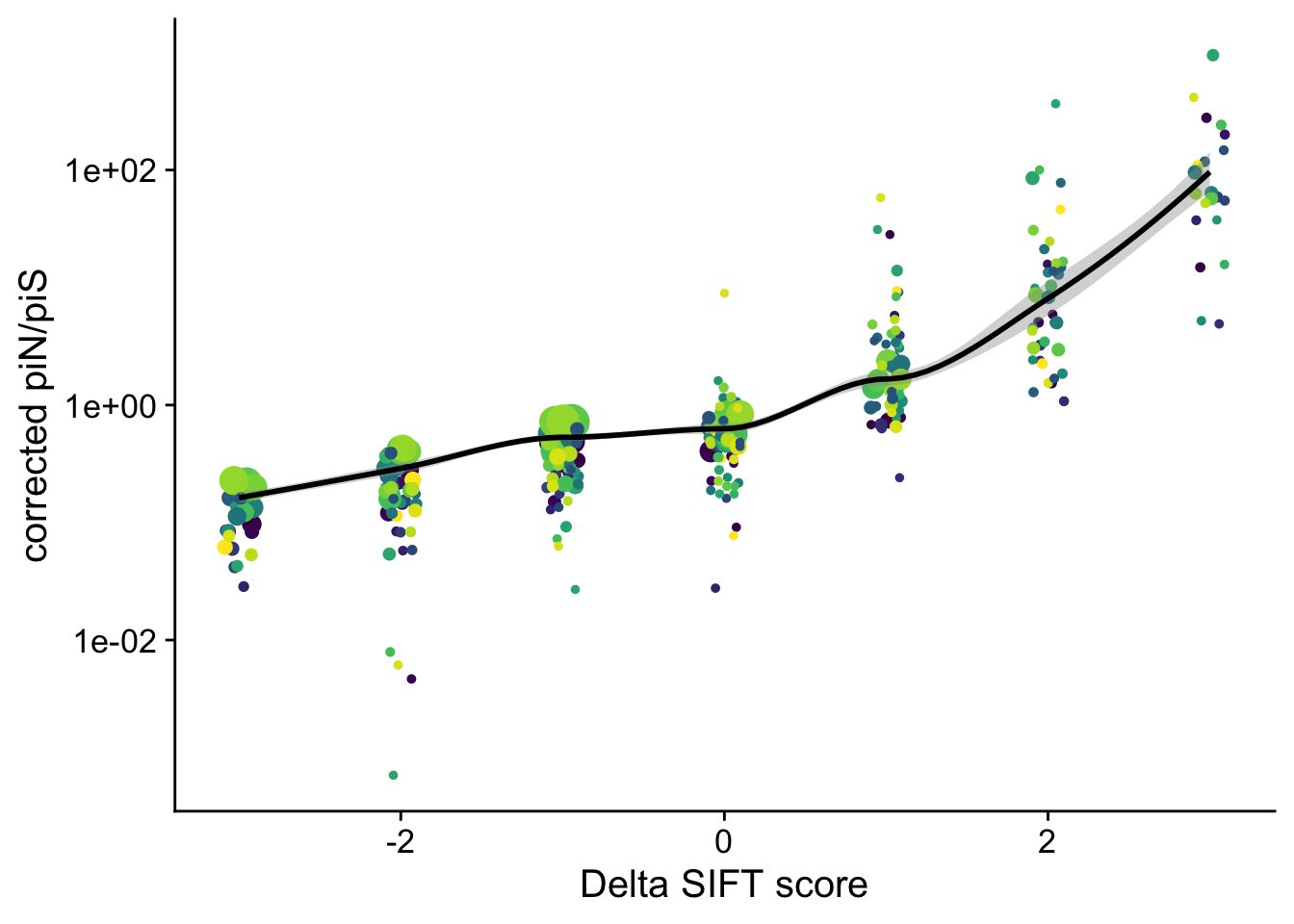
| Version | Author | Date |
|---|---|---|
| 706a03c | Thomas Bataillon | 2021-03-13 |
sessionInfo()R version 4.0.2 (2020-06-22)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] knitr_1.29 cowplot_1.1.0 magrittr_1.5 dplyr_1.0.2 ggthemes_4.2.0
[6] ggplot2_3.3.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.5 pillar_1.4.6 compiler_4.0.2 later_1.1.0.1
[5] git2r_0.27.1 workflowr_1.6.2 tools_4.0.2 digest_0.6.25
[9] lattice_0.20-41 nlme_3.1-148 evaluate_0.14 lifecycle_0.2.0
[13] tibble_3.0.3 gtable_0.3.0 mgcv_1.8-31 pkgconfig_2.0.3
[17] rlang_0.4.7 Matrix_1.2-18 rstudioapi_0.11 yaml_2.2.1
[21] xfun_0.16 withr_2.2.0 stringr_1.4.0 generics_0.0.2
[25] fs_1.5.0 vctrs_0.3.2 rprojroot_2.0.2 grid_4.0.2
[29] tidyselect_1.1.0 glue_1.4.1 R6_2.4.1 rmarkdown_2.3
[33] farver_2.0.3 purrr_0.3.4 whisker_0.4 splines_4.0.2
[37] scales_1.1.1 promises_1.1.1 ellipsis_0.3.1 htmltools_0.5.0
[41] colorspace_1.4-1 httpuv_1.5.4 labeling_0.3 stringi_1.4.6
[45] munsell_0.5.0 crayon_1.3.4