Curate by trait-trial
wolfemd
2020-Sep-16
Last updated: 2020-12-04
Checks: 7 0
Knit directory: IITA_2020GS/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200915) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 79b6430. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: data/.DS_Store
Ignored: output/.DS_Store
Untracked files:
Untracked: data/GEBV_IITA_OutliersRemovedTRUE_73119.csv
Untracked: data/PedigreeGeneticGainCycleTime_aafolabi_01122020.csv
Untracked: data/iita_blupsForCrossVal_outliersRemoved_73019.rds
Untracked: output/DosageMatrix_IITA_2020Sep16.rds
Untracked: output/IITA_CleanedTrialData_2020Dec03.rds
Untracked: output/IITA_ExptDesignsDetected_2020Dec03.rds
Untracked: output/Kinship_AA_IITA_2020Sep16.rds
Untracked: output/Kinship_AD_IITA_2020Sep16.rds
Untracked: output/Kinship_A_IITA_2020Sep16.rds
Untracked: output/Kinship_DD_IITA2020Sep16.rds
Untracked: output/Kinship_D_IITA_2020Sep16.rds
Untracked: output/cvresults_ModelADE_chunk1.rds
Untracked: output/cvresults_ModelADE_chunk2.rds
Untracked: output/cvresults_ModelADE_chunk3.rds
Untracked: output/genomicPredictions_ModelADE_threestage_IITA_2020Sep21.rds
Untracked: output/genomicPredictions_ModelADE_twostage_IITA_2020Dec03.rds
Untracked: output/genomicPredictions_ModelA_threestage_IITA_2020Sep21.rds
Untracked: output/iita_blupsForModelTraining_twostage_asreml_2020Dec03.rds
Untracked: output/model_meangetgvs_vs_year.csv
Untracked: output/model_rawgetgvs_vs_year.csv
Untracked: output/training_data_summary.csv
Untracked: workflowr_log.R
Unstaged changes:
Modified: output/IITA_ExptDesignsDetected.rds
Modified: output/iita_blupsForModelTraining.rds
Modified: output/meanGETGVbyYear_IITA_2020Dec03.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/02-curateByTrial.Rmd) and HTML (docs/02-curateByTrial.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 7bae38d | wolfemd | 2020-12-03 | Build site. |
| html | b9bb6f8 | wolfemd | 2020-12-03 | Build site. |
| html | d72a9ed | wolfemd | 2020-09-21 | Build site. |
| html | d6d72f8 | wolfemd | 2020-09-17 | Build site. |
| html | 7e156dd | wolfemd | 2020-09-17 | Build site. |
| Rmd | 7ea8b80 | wolfemd | 2020-09-17 | All steps including genomic predicting (excluding cross-validation), |
Previous step
- Prepare a training dataset: Download data from DB, “Clean” and format DB data
Nest by trial
Start with cleaned data from previous step.
rm(list = ls())
library(tidyverse)
library(magrittr)
dbdata <- readRDS(here::here("output", "IITA_CleanedTrialData.rds"))All downstream analyses in this step will by on a per-trial (location-year-studyName combination).
The nestByTrials() function converts a data.frame where each row is a plot to one where each row is a trial, with a list-type column TrialData containing the corresponding trial’s plot-data.
source(here::here("code", "gsFunctions.R"))
dbdata <- nestByTrials(dbdata)dbdata %>% head %>% rmarkdown::paged_table()dbdata$TrialData[[1]] %>% slice(1:20) %>% rmarkdown::paged_table()Detect experimental designs
The next step is to check the experimental design of each trial. If you are absolutely certain of the usage of the design variables in your dataset, you might not need this step.
Examples of reasons to do the step below:
- Some trials appear to be complete blocked designs and the blockNumber is used instead of replicate, which is what most use.
- Some complete block designs have nested, incomplete sub-blocks, others simply copy the “replicate” variable into the “blockNumber variable”
- Some trials have only incomplete blocks but the incomplete block info might be in the replicate and/or the blockNumber column
One reason it might be important to get this right is that the variance among complete blocks might not be the same among incomplete blocks. If we treat a mixture of complete and incomplete blocks as part of the same random-effect (replicated-within-trial), we assume they have the same variance.
Also error variances might be heterogeneous among different trial-types (blocking scheme available) and/or plot sizes (maxNOHAV).
Detect designs
dbdata <- detectExptDesigns(dbdata)dbdata %>% count(programName, CompleteBlocks, IncompleteBlocks) %>% rmarkdown::paged_table()Output file
saveRDS(dbdata, file = here::here("output", "IITA_ExptDesignsDetected.rds"))Model by trait-trial
NOTICE: Doing the next step on a server, too many traits and trials for laptop.
The next step fits models to each trial (for each trait)
rm(list = ls())
library(tidyverse)
library(magrittr)
source(here::here("code", "gsFunctions.R"))
dbdata <- readRDS(here::here("output", "IITA_ExptDesignsDetected.rds"))
traits <- c("MCMDS", "DM", "PLTHT", "BRNHT1", "BRLVLS", "HI", "logFYLD", "logTOPYLD",
"logRTNO", "TCHART", "LCHROMO", "ACHROMO", "BCHROMO")
# Nest by trait-trial. This next function will structure input trial data by
# trait. This will facilitate looping downstream analyses over each trait for
# each trial.
dbdata <- nestTrialsByTrait(dbdata, traits)dbdata %>% head %>% rmarkdown::paged_table()dbdata$TraitByTrialData[[1]] %>% head %>% rmarkdown::paged_table()Fit models
dbdata <- curateTrialsByTrait(dbdata, traits, ncores = 20)Output file
saveRDS(dbdata, file = here::here("output", "IITA_CuratedTrials.rds"))Plot Results
library(tidyverse); library(magrittr); #library(plotly)
dbdata<-readRDS(file=here::here("output","IITA_CuratedTrials.rds"))
traits<-c("MCMDS","DM","PLTHT","BRNHT1","BRLVLS","HI","logFYLD","logTOPYLD","logRTNO","TCHART","LCHROMO","ACHROMO","BCHROMO")
dbdata %<>%
mutate(Trait=factor(Trait,levels=traits),
TrialType=factor(TrialType,levels=c("CrossingBlock","GeneticGain","CET","ExpCET","PYT","AYT","UYT","NCRP"))) Heritabilities overall
dbdata %>% ggplot(., aes(x = Trait, y = H2, fill = Trait)) + geom_boxplot(color = "darkgray") +
theme_bw() + scale_fill_viridis_d(option = "magma") + theme(axis.text.x = element_text(face = "bold",
angle = 90), axis.title = element_text(face = "bold", size = 12), plot.title = element_text(face = "bold",
size = 14), legend.position = "none") + labs(x = NULL, y = expression("H"^"2"),
title = "Broad-sense Heritabilities across trials")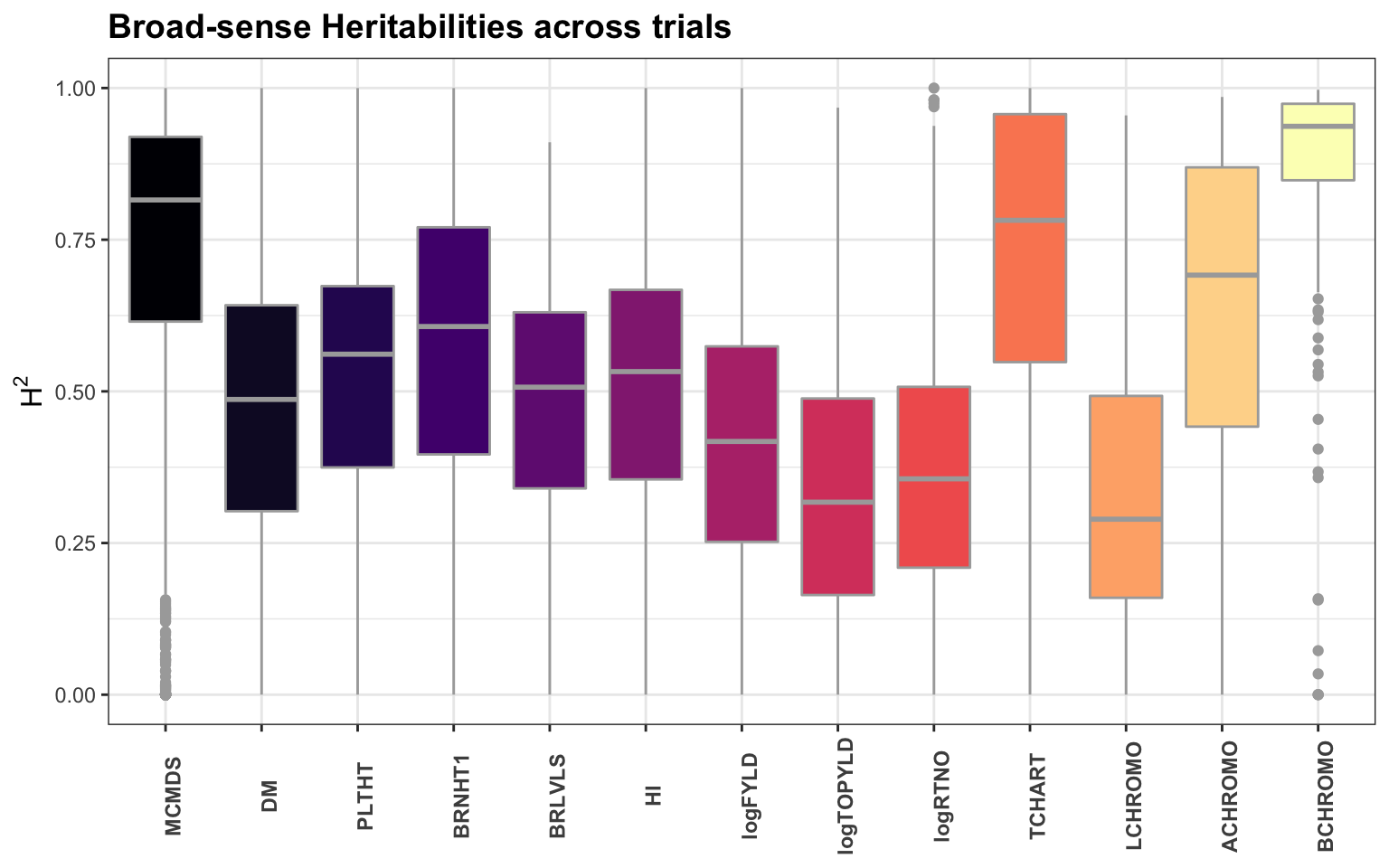
Residual variances, by TrialType and Trait
dbdata %>% select(studyYear:VarComps) %>% unnest(VarComps) %>% ggplot(., aes(x = TrialType,
y = Residual, fill = TrialType)) + geom_boxplot(color = "darkgray") + theme_bw() +
facet_wrap(~Trait, scales = "free", nrow = 3) + scale_fill_viridis_d(option = "inferno") +
theme(axis.text.x = element_text(angle = 90, face = "bold"), legend.position = "none")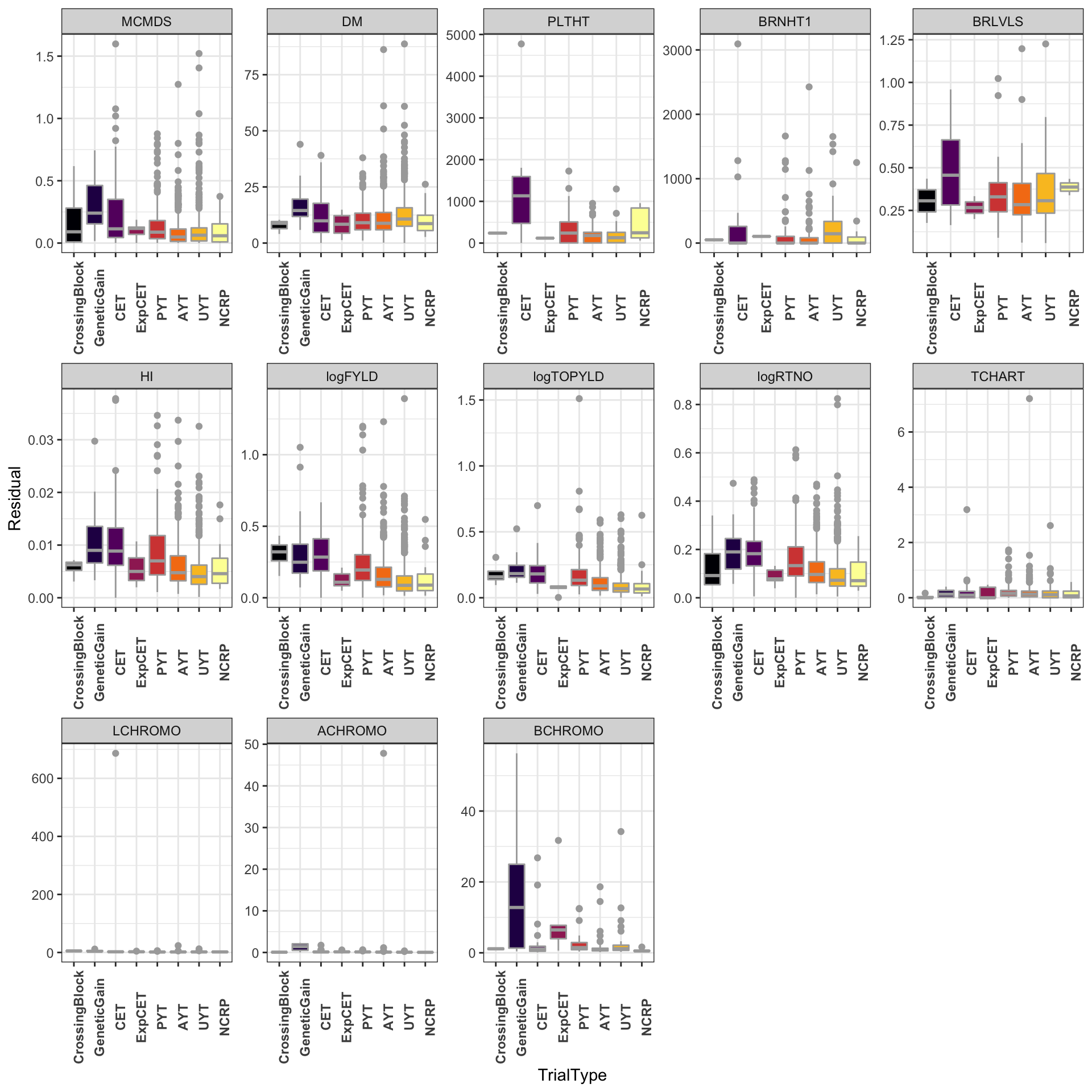
H2 by trait and trialtype.
dbdata %>% select(studyYear:VarComps) %>% unnest(VarComps) %>% ggplot(., aes(x = TrialType,
y = H2, fill = TrialType)) + geom_boxplot(color = "darkgray") + theme_bw() +
facet_wrap(~Trait, scales = "free", nrow = 2) + scale_fill_viridis_d(option = "inferno") +
theme(axis.text.x = element_text(angle = 90, face = "bold"), legend.position = "none")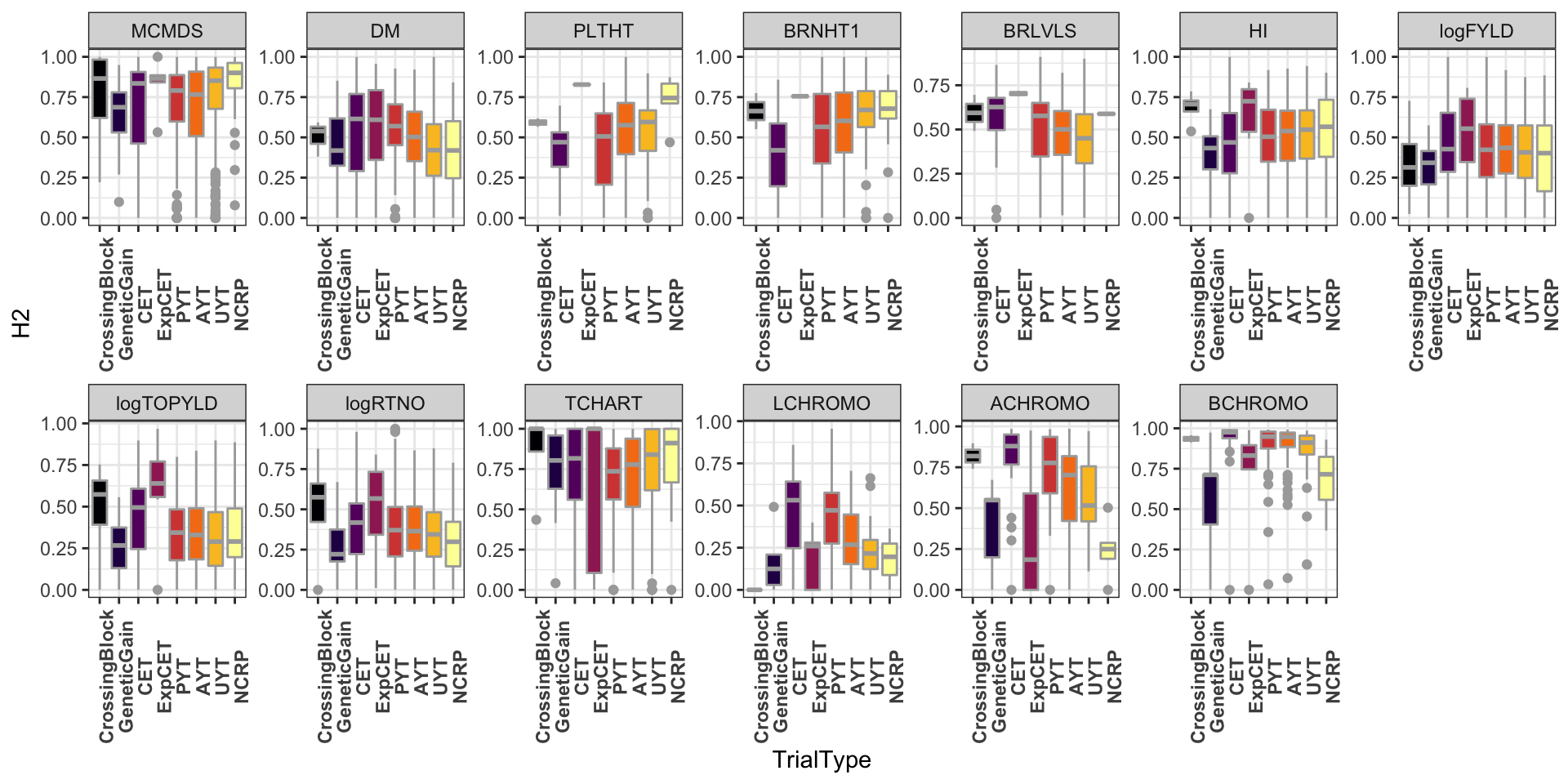
Number of outliers detected and removed by trait-trialType.
dbdata %>% ggplot(., aes(x = TrialType, y = Noutliers, fill = TrialType)) + geom_boxplot(color = "darkgray") +
theme_bw() + facet_wrap(~Trait, scales = "free", nrow = 4) + scale_fill_viridis_d(option = "inferno") +
theme(axis.text.x = element_text(angle = 90, face = "bold"), legend.position = "none")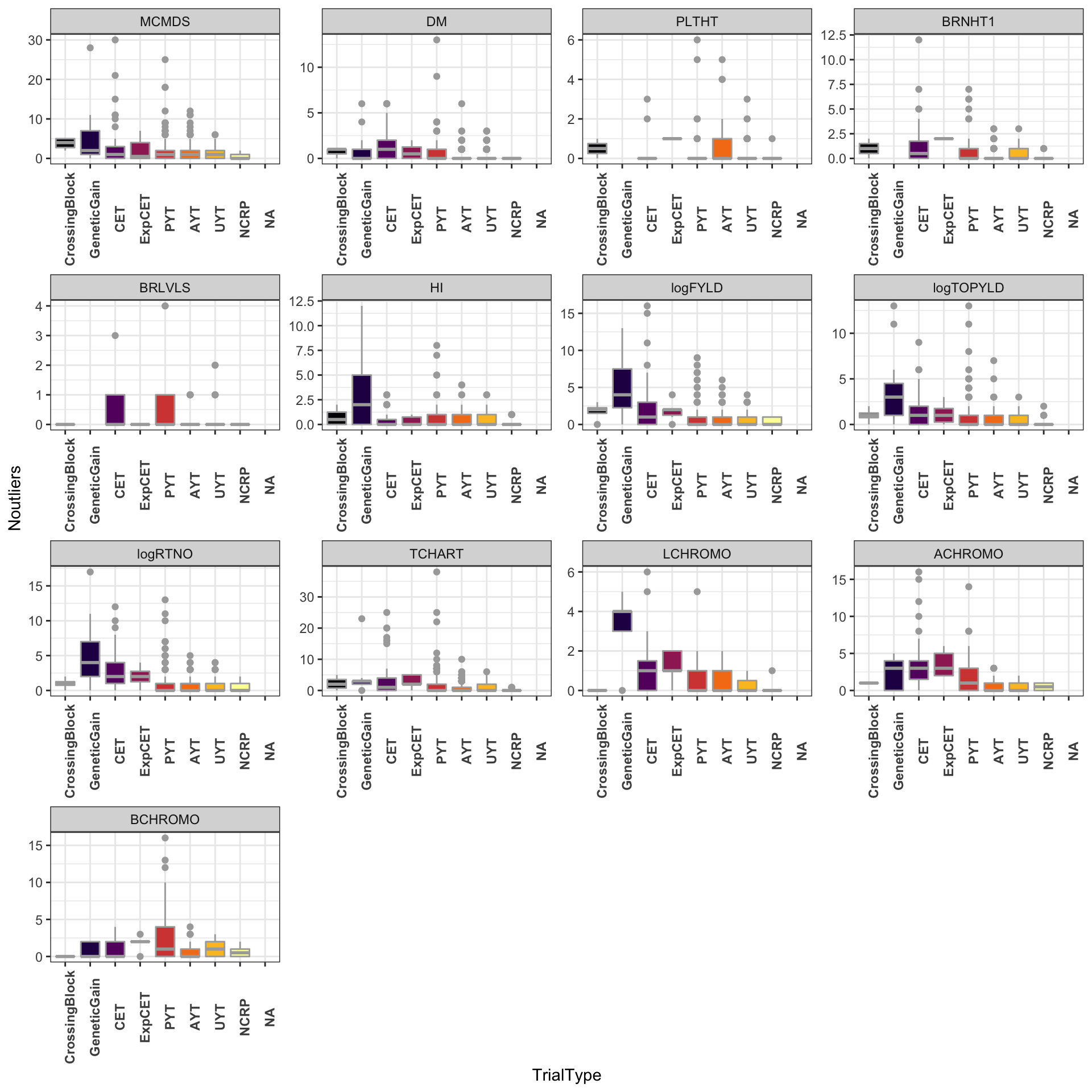
Missingness
dbdata %>% ggplot(., aes(x = TrialType, y = propMiss, fill = TrialType)) + geom_boxplot(color = "darkgray") +
theme_bw() + facet_wrap(~Trait, scales = "free", nrow = 3) + scale_fill_viridis_d(option = "inferno") +
theme(axis.text.x = element_text(angle = 90, face = "bold"), legend.position = "none")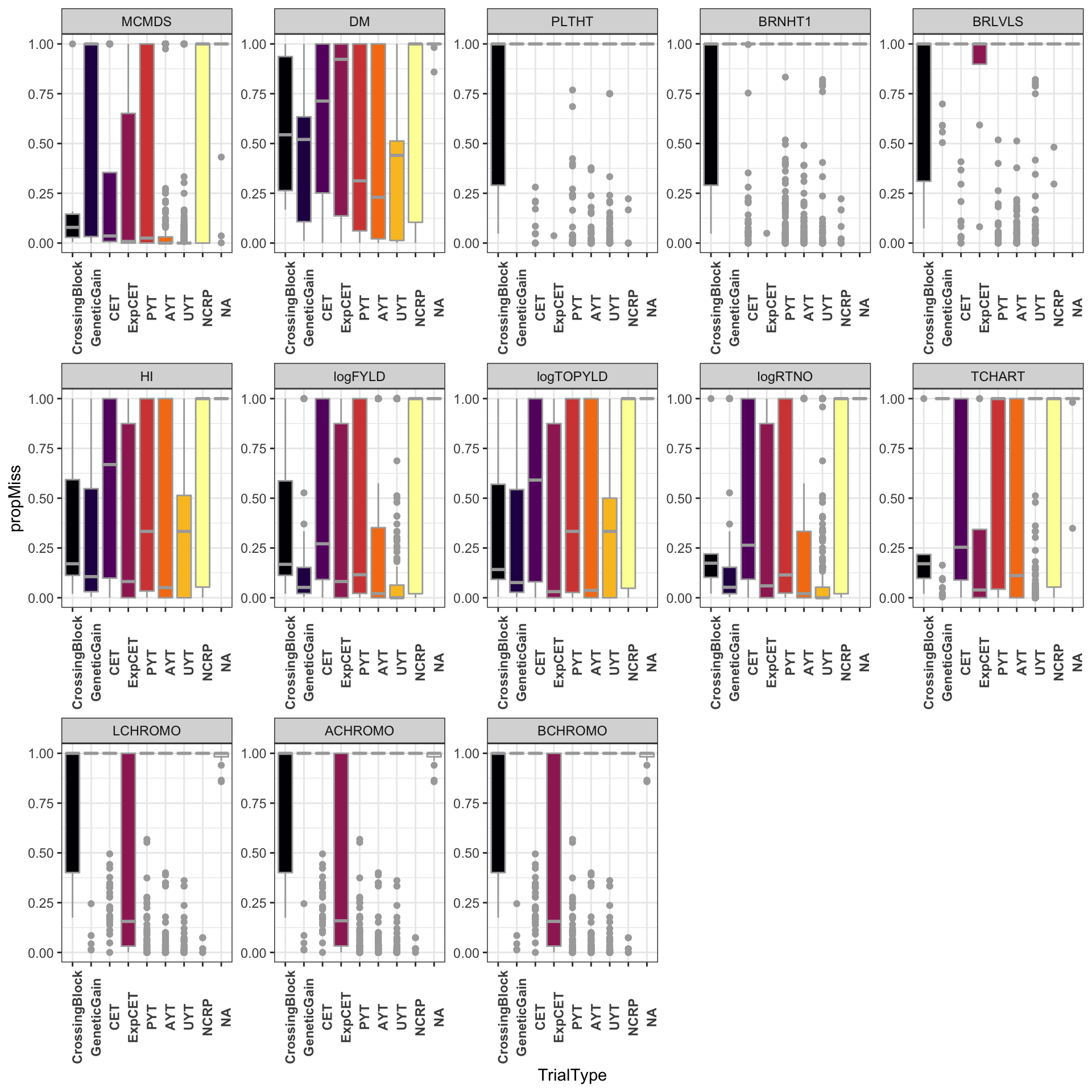
Next step
- Get BLUPs combining all trial data: Combine data from all trait-trials to get BLUPs for downstream genomic
sessionInfo()R version 4.0.2 (2020-06-22)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] magrittr_2.0.1 forcats_0.5.0 stringr_1.4.0 dplyr_1.0.2
[5] purrr_0.3.4 readr_1.4.0 tidyr_1.1.2 tibble_3.0.4
[9] ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] tidyselect_1.1.0 xfun_0.19 haven_2.3.1 colorspace_2.0-0
[5] vctrs_0.3.5 generics_0.1.0 viridisLite_0.3.0 htmltools_0.5.0
[9] yaml_2.2.1 rlang_0.4.9 later_1.1.0.1 pillar_1.4.7
[13] withr_2.3.0 glue_1.4.2 DBI_1.1.0 dbplyr_2.0.0
[17] modelr_0.1.8 readxl_1.3.1 lifecycle_0.2.0 munsell_0.5.0
[21] gtable_0.3.0 cellranger_1.1.0 rvest_0.3.6 evaluate_0.14
[25] labeling_0.4.2 knitr_1.30 ps_1.4.0 httpuv_1.5.4
[29] fansi_0.4.1 broom_0.7.2 Rcpp_1.0.5 promises_1.1.1
[33] backports_1.2.0 scales_1.1.1 formatR_1.7 jsonlite_1.7.1
[37] farver_2.0.3 fs_1.5.0 hms_0.5.3 digest_0.6.27
[41] stringi_1.5.3 rprojroot_2.0.2 grid_4.0.2 here_1.0.0
[45] cli_2.2.0 tools_4.0.2 crayon_1.3.4 whisker_0.4
[49] pkgconfig_2.0.3 ellipsis_0.3.1 xml2_1.3.2 reprex_0.3.0
[53] lubridate_1.7.9.2 rstudioapi_0.13 assertthat_0.2.1 rmarkdown_2.5
[57] httr_1.4.2 R6_2.5.0 git2r_0.27.1 compiler_4.0.2